Parsing XML
We have created parseXML() function to parse XML file. We know that XML is an inherently hierarchical data format, and the most natural way to represent it is with a tree. Look at the image below for example:
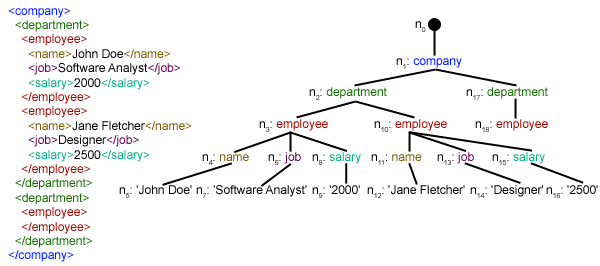
Here, we are using xml.etree.ElementTree (call it ET, in short) module. Element Tree has two classes for this purpose – ElementTree represents the whole XML
document as a tree, and Element represents a single node in this tree. Interactions with the whole document (reading and writing to/from files) are usually done on the ElementTree level. Interactions with a single XML element and its sub-elements are done on the Element level.
Ok, so let’s go through the parseXML() function now:
tree = ET.parse(xmlfile)
Here, we create an ElementTree object by parsing the passed xmlfile.
root = tree.getroot()
getroot() function return the root of tree as an Element object.
for item in root.findall('./channel/item'):
Now, once you have taken a look at the structure of your XML file, you will notice that we are interested only in item element.
./channel/item is actually XPath syntax (XPath is a language for addressing parts of an XML document). Here, we want to find all item grand-children of channel children of the root(denoted by ‘.’) element.
You can read more about supported XPath syntax here.
for item in root.findall('./channel/item'):
# empty news dictionary
news = {}
# iterate child elements of item
for child in item:
# special checking for namespace object content:media
if child.tag == '{http://search.yahoo.com/mrss/}content':
news['media'] = child.attrib['url']
else:
news[child.tag] = child.text.encode('utf8')
# append news dictionary to news items list
newsitems.append(news)
Now, we know that we are iterating through item elements where each item element contains one news. So, we create an empty news dictionary in which we will store all data available about news item. To iterate though each child element of an element, we simply iterate through it, like this:
for child in item:
Now, notice a sample item element here:

We will have to handle namespace tags separately as they get expanded to their original value, when parsed. So, we do something like this:
if child.tag == '{http://search.yahoo.com/mrss/}content':
news['media'] = child.attrib['url']
child.attrib is a dictionary of all the attributes related to an element. Here, we are interested in url attribute of media:content namespace tag.
Now, for all other children, we simply do:
news[child.tag] = child.text.encode('utf8')
child.tag contains the name of child element. child.text stores all the text inside that child element. So, finally, a sample item element is converted to a dictionary and looks like this:
{'description': 'Ignis has a tough competition already, from Hyun.... ,
'guid': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... ,
'link': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... ,
'media': 'http://www.hindustantimes.com/rf/image_size_630x354/HT/... ,
'pubDate': 'Thu, 12 Jan 2017 12:33:04 GMT ',
'title': 'Maruti Ignis launches on Jan 13: Five cars that threa..... }
Then, we simply append this dict element to the list newsitems.
Finally, this list is returned.