Working with Git Repositories
Last Updated :
29 Dec, 2019
Git is a free and open-source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
Git relies on the basis of distributed development of software where more than one developer may have access to the source code of a specific application and can modify changes to it which may be seen by other developers. It allows the user to have “versions” of a project, which show the changes that were made to the code over time, and allows the user to backtrack if necessary and undo those changes.
Repositories in GIT contain a collection of files of various different versions of a Project. These files are imported from the repository into the local server of the user for further updations and modifications in the content of the file. A VCS or the Version Control System is used to create these versions and store them in a specific place termed as a repository.
Repositories in Git are of two types:
- Local Repository: Git allows the users to perform work on a project from all over the world because of its Distributive feature. This can be done by cloning the content from the Central repository stored in the GitHub on the user’s local machine. This local copy is used to perform operations and test them on the local machine before adding them to the central repository.
- Remote Repository: Git allows the users to sync their copy of the local repository to other repositories present over the internet. This can be done to avoid performing a similar operation by multiple developers. Each repository in Git can be addressed by a shortcut called remote.
Git provides tools to perform work on these repositories according to the needs of the user. This workflow of performing modifications to a Repository is referred to as the Working Tree.
Bare repositories: A bare repository is a remote repository that can interact with other repositories but there is no operation performed on this repository. There is no Working Tree for this repository because of the same. A bare repository in Git can be created on the local machine of the user with the use of the following command:
$ git init --bare
A bare repository is always created with a .git extension. This is used to store all the changes, commits, refs, etc. that are being performed on the repository. It is usually a hidden directory.
A Git repository can also be converted to a bare repository but that is more of a manual process. Git doesn’t officially provide the support to do the same. But one can easily convert it into a bare repository by moving the content of the .git folder into the root folder and removing all the other files from the current working tree of the repository.
Further, the Git repository needs to be updated with the following command:
$ git config core.bare true
It is always recommended to clone a repository before performing such an operation.
How to Clone a Git repository?
Git allows its users to perform work on a single project for more than one local machine at the same time. This can be done by downloading a copy of the repository on to the local machine and further updating it with the central server after the modifications are done and are ready to be moved. This cloning process can be done by the use of a predefined git command
$ git clone
This will create an exact copy of the existing Git repository with a complete history of all the previously cloned repositories. Users can perform whatever actions on the local copy of the repository and can discard those changes without making any change in the original repository.

Adding a Remote Repository to Local Repository
A user can also work on Remote repositories by adding them to the local repositories. This will make the fetching and push process much easier than doing the same from the central repository. A default remote repository named origin gets created when the cloning process is done by the use of clone command. This remote ‘origin’ gets linked to the cloned repository.

Here, it can be seen that there is only one repository named origin which is the default repository.
To push content to this repository, the git push command is used. It will by default push the content into the origin remote.
To add a remote repository with the local repository, $ git remote add command is used. The file name and path are to be passed to this command as an argument.
$ git remote add

This will add the remote repository at the given path with the local repository.

Here, it can be seen that a new repository named new_remote has been added with the existing remotes.
Renaming a Remote Repository
Remote repositories can be renamed whenever there is a need. This can be done with a Git command termed as rename.
$git remote rename

Note:The default remote repository ‘origin’ gets created only when a repository is cloned but not when a repository is created with the use of git init command.
Pushing changes to a remote repository
After the user is done with the modifications in the Local repository, there is a need to push these changes in the remote repository. This can be done with the git push command. Users can define which branch is to be pushed into the repository by passing its name as an argument.
By default, the data will be pushed from the current branch into the same branch of the remote repository.
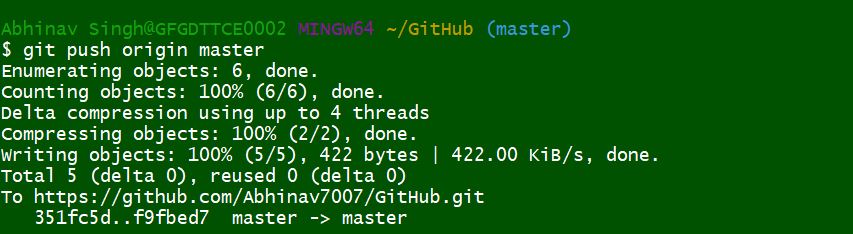
Pull or Fetch from a Remote Repository
Pulling or Fetching of data from a central repository is done to update the collaborator’s local copy of the repository. This helps to replace the older version with the latest one. This process is done by the use of a Git command termed as git pull or git fetch.
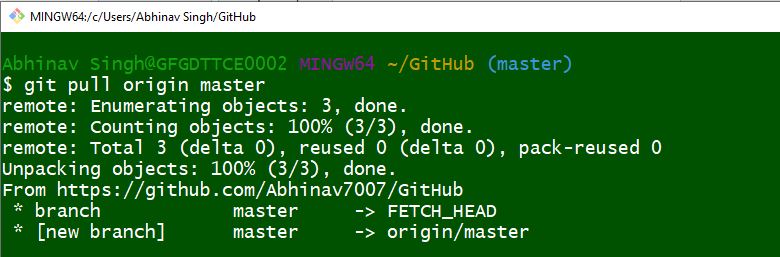
Pull command and fetch command can be both used for the same job, as they both update the repository to the latest version. The only difference between a fetch command and a pull command is that the fetch command only updates the remote branches and not the local branch, while pull command updates both the local and remote repositories.
Share your thoughts in the comments
Please Login to comment...