What is a Distributed Cache?
Last Updated :
22 Apr, 2024
Distributed caches are essential tools for improving the speed and reliability of applications in distributed computing environments. By storing frequently accessed data closer to where it’s needed and across multiple servers, distributed caches reduce latency and ease the load on backend systems. In this article, we’ll explore what distributed caches are, how they work, and why they’re crucial for modern applications.
Important Topics for Distributed Cache
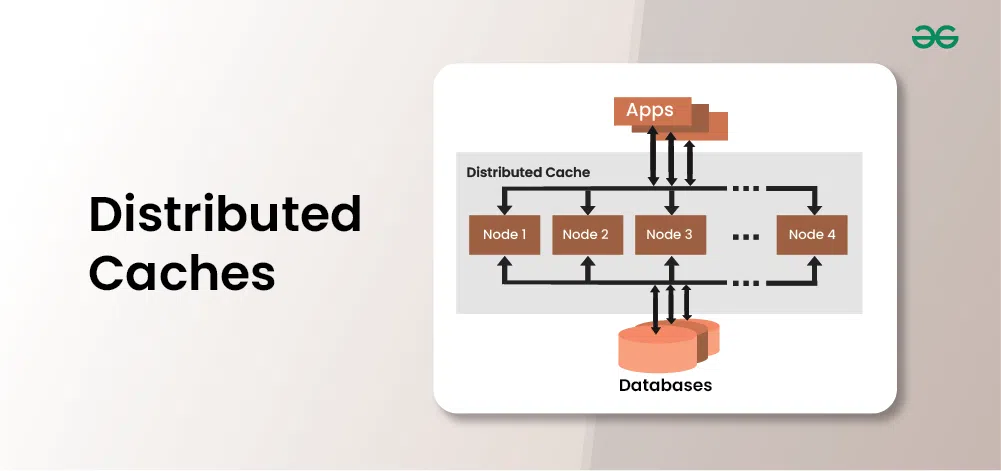
What is a Distributed Cache?
A distributed cache is a cache with data spread across multiple nodes in a cluster and multiple clusters across multiple data centers worldwide. A distributed cache is a system that pools together the random-access memory (RAM) of multiple networked computers into a single in-memory data store used as a data cache to provide fast access to data.
- While most caches are traditionally in one physical server or hardware component, a distributed cache can grow beyond the memory limits of a single computer by linking together multiple computers–referred to as a distributed architecture or a distributed cluster–for larger capacity and increased processing power.
- Distributed caches are especially useful in environments with high data volume and load.
- The distributed architecture allows incremental expansion/scaling by adding more computers to the cluster, allowing the cache to grow in step with the data growth.
How Distributed Cache Works?
Below is how a Distributed Cache typically works:
- Data Storage: The distributed cache system allocates a portion of memory on each node or server to store cached data. This memory is typically faster to access than disk storage, enabling faster read and write operations.
- Data Replication: To ensure high availability and fault tolerance, the distributed cache system replicates cached data across multiple nodes or servers. This means that if one node fails, the data can still be accessed from other nodes in the cluster.
- Cache Invalidation: Cached data needs to be invalidated or updated periodically to reflect changes in the underlying data source. Distributed cache systems implement various strategies for cache invalidation, such as time-based expiration, event-based invalidation, or manual invalidation.
- Cache Coherency: Maintaining cache coherency ensures that all nodes in the distributed cache system have consistent copies of cached data. This involves synchronization mechanisms to update or invalidate cached data across all nodes when changes occur.
- Cache Access: Applications interact with the distributed cache system through a cache API, which provides methods for storing, retrieving, and updating cached data. When an application requests data, the distributed cache system checks if the data is already cached. If it is, the data is retrieved from the cache memory, avoiding the need to access the underlying data source.
- Cache Eviction: To prevent the cache from consuming too much memory, distributed cache systems implement eviction policies to remove least recently used (LRU) or least frequently used (LFU) data from the cache when it reaches its capacity limit.
Regarding the concurrency there are several concepts involved with it such as eventual consistency, strong consistency, distributed locks, commit logs and stuff. Also, distributed cache often works with distributed system co-ordinators such as Zookeeper. It facilitates communication and helps maintain a consistent state amongst the several running cache nodes.
Key components of Distributed Caching
The key components of distributed Caching include:
1. Cache Servers or Nodes
Cache servers are the primary components in a distributed caching system. They store temporary data across multiple machines or nodes, ensuring that the data is available close to where it’s needed. Each cache server can operate independently, and in case of a server failure, the system can reroute requests to another server using consistent hashing, ensuring high availability and fault tolerance.
2. Cache Data
This is the actual data stored in the distributed cache system. It can include frequently accessed objects, database query results, or any other data that benefits from being stored in memory for fast access.
3. Cache Client
Applications interact with the distributed cache system through a cache client, which provides an interface for storing, retrieving, and updating cached data. The cache client abstracts the complexity of cache management and communication with cache nodes, making it easier for developers to integrate caching into their applications.
4. Cache API
The cache API defines the methods and operations available for interacting with the distributed cache system. This includes commands for reading, writing, invalidating, and evicting cached data, as well as administrative operations for managing the cache cluster.
5. Cache Manager
The cache manager is responsible for coordinating cache operations and managing the overall behavior of the distributed cache system. It may include components for data distribution, replication, eviction, consistency maintenance, and cache invalidation.
6. Data Partitioning
In a distributed caching system, data may be partitioned or sharded across multiple cache nodes to distribute the workload and balance resource usage. Data partitioning strategies determine how data is divided among cache nodes based on keys, hashes, or other criteria.
7. Replication and Consistency Mechanisms
To ensure high availability and fault tolerance, distributed caching systems often replicate cached data across multiple nodes. Replication mechanisms ensure that data remains consistent and up-to-date across all replicas, even in the event of node failures or network partitions.
8. Monitoring and Management Tools
Distributed caching systems typically provide tools and interfaces for monitoring cache performance, health, and usage metrics. These tools enable administrators to monitor cache utilization, troubleshoot issues, and perform maintenance tasks such as adding or removing cache nodes.
Benefits of Distributed Cache
These are some of the core benefits of using a distributed cache methodology :
- Keeps frequently accessed data in memory, which enhancing the application’s response time and user experience.
- Allows for adding more nodes to the cluster, enabling applications to scale horizontally without impacting performance and can handle high data requests, making it suitable for applications requiring high throughput.
- Can replicate data across multiple nodes, ensuring that data is always available even if one or more nodes fail.
- By caching data in memory, distributed cache reduces the need for network requests to fetch data from a database or file system, reducing network traffic and improving performance.
- Reduces the need for expensive hardware upgrades or additional database lisences, making it a cost-effective solution for scaling applications.
- Can store user session data, improving the performance and scalability of web applications.
- Can be integrated with other systems like Apache Kafka to provide real-time data processing capabilities.
Popular Use Cases of Distributed Cache
There are many use cases for which an application developer may include a distributed cache as part of their architecture. These include:
- Application acceleration:
- Applications that rely on disk-based relational databases can’t always meet today’s increasingly demanding transaction performance requirements.
- By storing the most frequently accessed data in a distributed cache, you can dramatically reduce the I/O bottleneck of disk-based systems.
- This ensures your applications run much faster, even with a large number of transactions when usage spikes.
- Storing web session data :
- A site may store user session data in a cache to serve as inputs for shopping carts and recommendations.
- With a distributed cache, you can have a large number of concurrent web sessions that can be accessed by any of the web application servers that are running the system.
- This lets you load balance web traffic over several application servers and not lose session data should any application server fail.
- Decreasing network usage/costs :
- By caching data in multiple places in your network, including on the same computers as your application, you can reduce network traffic and leave more bandwidth available for other applications that depend on the network.
- Reducing the impact of interruptions :
- Depending on the architecture, a cache may be able to answer data requests even when the source database is unavailable. This adds another level of high availability to your system.
- Extreme scaling :
- Some applications request significant volumes of data. By leveraging more resources across multiple machines, a distributed cache can answer those requests.
Implementing Distributed Caching
Setting up a distributed cache involves several steps, from choosing the right caching solution to configuring and deploying it in a distributed environment. Below is the general step-by-step guide:
- Step 1: Select a suitable distributed caching solution based on application requirements and infrastructure.
- Step 2: Install and configure the caching software on each node or server in the distributed system.
- Step 3: Define data partitioning and replication strategies to ensure efficient data distribution and high availability.
- Step 4: Integrate the caching solution with the application, ensuring that data reads and writes are directed to the cache.
- Step 5: Monitor and fine-tune the cache performance, adjusting configurations as needed for optimal results.
Distributed Caching Challenges
Although there are benefits, distributed caching poses certain challenges as well:
- Data consistency: The main challenge with distributed caching is maintaining data consistency. Caches may have different data versions or may experience replication delays, leading to data inconsistency.
- Cache invalidation: Implementing proper cache invalidation and synchronization mechanisms or using eventual consistency models can help mitigate this challenge. Invalidating caches can be challenging, especially when data is frequently changing or interdependent. Ensuring that the cache is refreshed, i.e., updated when underlying data changes, or employing strategies, such as cache expiration based on time, can help maintain cache validity.
- Cache eviction strategies: Since data access patterns may differ across the nodes, it is quite challenging to implement cache eviction strategies in a distributed cache environment. Careful consideration should be given to selecting an eviction strategy that aligns with your application’s data access patterns and requirements.
- Cache synchronization: In multi-level caching systems, where multiple caches, like local cache and distributed cache, are used, ensuring proper synchronization and consistency across different cache layers can be challenging. You can prevent inconsistencies in your data by implementing the right synchronization strategies.
- Network overhead: Distributed caching systems require communication and synchronization between cache servers, which introduces network overhead. High network latency or limited bandwidth can affect cache performance and overall application responsiveness.
- Complexity and maintenance: For the cache infrastructure to operate smoothly, it must be properly maintained, monitored, and troubleshot with proper expertise and resources. Implementation of a distributed caching system, in the application architecture introduces increased complexity in terms of implementation, management, and monitoring.
- Application compatibility: Some applications may not be designed to work seamlessly with distributed caching or may have dependencies that don’t support caching effectively. Evaluate and modify the application to ensure compatibility with the distributed caching approach.
Conclusion
Distributed cache is an essential component in modern web applications that can help improve application performance, scalability, and user experience. For example, it can reduce application latency, improve response times, and enable faster data access by storing frequently accessed data in memory.
Share your thoughts in the comments
Please Login to comment...