Web Scraping in Java With Jsoup
Last Updated :
21 Mar, 2024
Web scraping means the process of extracting data from websites. It’s a valuable method for collecting data from the various online sources. Jsoup is a Java library that makes handling HTML content easier. Let’s learn how to build a basic web scraper with Jsoup.
Prerequisites
Here’s what you need to use in:
Concept
Jsoup helps us to read HTML documents. It lets us follow the document’s structure and extract the data we want. We use CSS selectors or DOM traversal methods for this. With Jsoup, we go to a website, get its HTML, and take out things like text, links or images.
Step-by-Step Implementation
Now, let’s create a basic Java project using Maven.
Step 1: Create a Java Maven project
Open the cmd/terminal and run the following commands to create a new Maven project.
mvn archetype:generate
-DgroupId=com.example
-DartifactId=java-jsoup1
-DarchetypeArtifactId=maven-archetype-quickstart
-DinteractiveMode=false
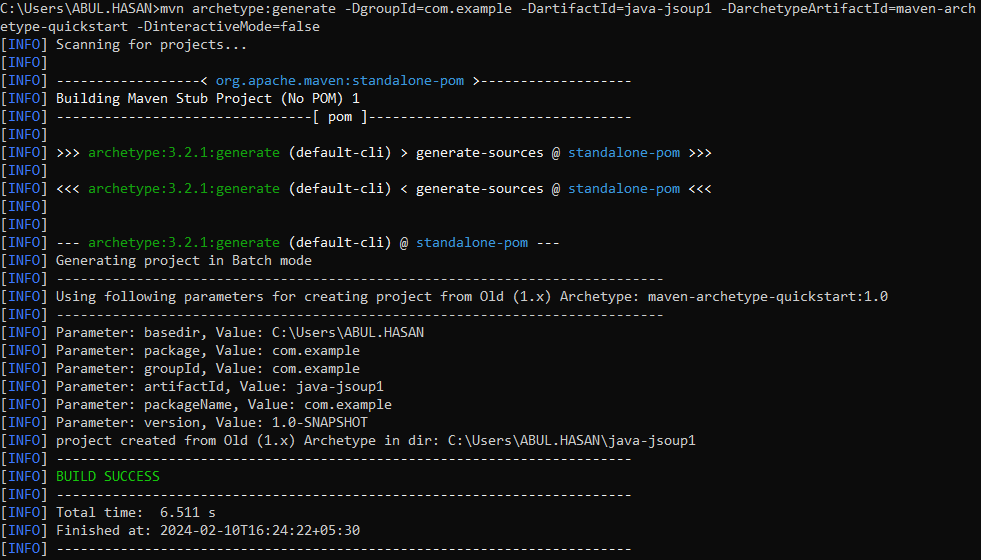
This command will generate a basic Maven project structure. Below we can see the Maven project builds successfully.
Step 2: Add Jsoup Dependency
Open the pom.xml file in the project folder then add the Jsoup dependency into it and save the file.
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
</dependencies>
Step 3: Create a Java File
In the src/main/java/com/example folder, create a Java file named MyScrapper.java.
Java
package com.example;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class MyScrapper {
public static void main(String[] args)
{
try {
Document doc
= Jsoup
.connect("https://geeksforgeeks.org/")
.get();
Elements links = doc.select("a[href]");
Elements images = doc.select("img[src]");
System.out.println("Links: ");
for (Element link : links) {
System.out.println(link.attr("href"));
}
System.out.println("\n-----\n");
System.out.println("Images:");
for (Element image : images) {
System.out.println(image.attr("src"));
}
}
catch (IOException e) {
e.printStackTrace();
}
}
}
Explanation:
- Firstly We declare that the class is part of the com.example package.
- After that, we import those classes we need from Jsoup library and java.io package.
- Then created a class named MyScrapper with the main mthod because its the entry point of the program. and it throws an IOException. This shows that input/output exceptions could happen.
- We use Jsoup.connect(“https://geeksforgeeks.org/”).get() to establish a connection to the website and fetch its HTML content as a Document object.
- Selecting Elements:
- doc.select(“a[href]”) selects all anchor elements (<a>) with an href attribute and stores them in the links variable.
- doc.select(“img[src]”) selects all image elements (<img>) with a src attribute and stores them in the images variable.
- And at last, the extracted values are printed to the console.
Step 4: Run the Program
To run the project, use below maven commands.
mvn compile
mvn exec:java -Dexec.mainClass="com.example.MyScrapper"
Note: The project can be direct run by presssing the run icon in the IDE.
Output:
In this article will teach you how to make a basic web scraper using Jsoup in Java. Make sure to follow website rules and scrape responsibly and fairly.
Share your thoughts in the comments
Please Login to comment...