Web Crawling using Cheerio
Last Updated :
10 Sep, 2023
By sending HTTP request to a particular URL and then by extracting HTML of that web page for getting useful information is known as crawling or web scraping.
Modules to be used for crawling in Nodejs:
- request: For sending HTTP request to the URL
- cheerio: For parsing DOM and extracting HTML of web page
- fs: For reading or writing the data into the file
Installation of these modules:
The easiest way to install modules in Nodejs is using NPM. it can be done in two ways:
- Globally Installation: If we install any module globally then we can use it anywhere in our system. It can be done by the following command:
npm i -g package_name
- Locally Installation: If we install any module locally then we can use it only within that particular project directory. It can be done by the following command:
npm i package_name
For this task we will use the local installation:
Steps for Web Crawling using Cheerio:
Step 1: create a folder for this project
Step 2: Open the terminal inside the project directory and then type the following command:
npm init
It will create a file named
package.json
which contains all information about the modules, author, github repository and its versions as well.
For know more about
package.json
please visit this link:
explanation of package.json
To install the modules locally using NPM simply do:
npm install request
npm install cheerio
npm install fs
This can be done in the single line as well using NPM:
npm install request cheerio fs
After successfully installing modules our package.json will have structure like this :

Here in this screenshot we can see all our dependencies have been listed within the dependencies object, It implies we have successfully installed all of them in our current project directory.
Step 3: Now we will code for crawler Steps for coding:
- First we will import all our required modules
- Then, we will send a HTTP request to the URL and then server of the desired website will respond with an web page, it will be done with the request module
- Now, we have the HTML of the web page, our task is to extract the useful information from it, so we will traverse the DOM tree and will find out the selectors
- After extracting our information, we will save it into a file, this task will be done with the help of fs module
Code for Crawler:
1. Create a file called server.js and add the following lines:
const request = require('request');
const cheerio = require('cheerio');
const mongoose = require('fs');
Explanation of these lines of code: Here in these three lines, we are importing all these three modules, required for crawling and data saving into a file.
2. We will hit the URL from where we want to crawl data: Here we are going to crawl the list of smartphones from an e-commerce website Flipkart. URL for showing smartphones list are as follows in flipkart:
const URL = "https://www.flipkart.com/search?q=mobiles";
On this URL web page looks like this: Now we will hit this URL with the help of
Now we will hit this URL with the help of
request
module:
request(URL, function (err, res, body) {
if(err)
{
console.log(err, "error occurred while hitting URL");
}
else
{
console.log(body);
}
});
Let’s understand these piece of code: Here we are using request module to send the HTTP request to the flipkart’s URL of smartphones, and the function within the request module takes three parameters error, response, body respectively. Here if error comes then we log it otherwise we log the body. For testing it, when we will run our script by
node server.js
we can see the whole HTML of the page in our console. It is the complete HTML of the web page for this URL. Now our task is to extract the useful information so we will visit the DOM tree and find out the selectors by inspecting element. For doing it right click on the web page and go to the inspect element like it:  Now we will visit the DOM:
Now we will visit the DOM:  Now we will change our request to hit the URL accordingly to the inspection:
Now we will change our request to hit the URL accordingly to the inspection:
request(URL, function (err, res, body) {
if(err)
{
console.log(err);
}
else
{
let $ = cheerio.load(body); //loading of complete HTML body
$('div._1HmYoV > div.col-10-12>div.bhgxx2>div._3O0U0u').each(function(index){
const link = $(this).find('div._1UoZlX>a').attr('href');
const name = $(this).find('div._1-2Iqu>div.col-7-12>div._3wU53n').text();
console.log(link); //link for smartphone
console.log(name); //name of smartphone
});
}
});
3. Saving the data into the file For doing it we will create an array and an object
let arr = []; //creating an array
let object =
{
link : link,
name : name,
} //creating an object
fs.writeFile('data.txt', arr, function (err) {
if(err) {
console.log(err);
}
else{
console.log("success");
}
});
And over each iteration we will push our object into the array after converting it into string; At last we will write the whole array into the file. by this method our complete data will be saved in the file successfully!
Now our whole code will like it:javascript
// Write Javascript code here
const request = require('request');
const cheerio = require('cheerio');
const fs = require('fs');
const URL = "https://www.flipkart.com/search?q=mobiles";
request(URL, function (err, res, body) {
if(err)
{
console.log(err);
}
else
{
const arr = [];
let $ = cheerio.load(body);
$('div._1HmYoV > div.col-10-12>div.bhgxx2>div._3O0U0u').each(function(index){
const data = $(this).find('div._1UoZlX>a').attr('href');
const name = $(this).find('div._1-2Iqu>div.col-7-12>div._3wU53n').text();
const obj = {
data : data,
name : name
};
console.log(obj);
arr.push(JSON.stringify(obj));
});
console.log(arr.toString());
fs.writeFile('data.txt', arr, function (err) {
if(err) {
console.log(err);
}
else{
console.log("success");
}
});
}
});
Now run the code:
node server.js
You can see the output on terminal like this while running the code:
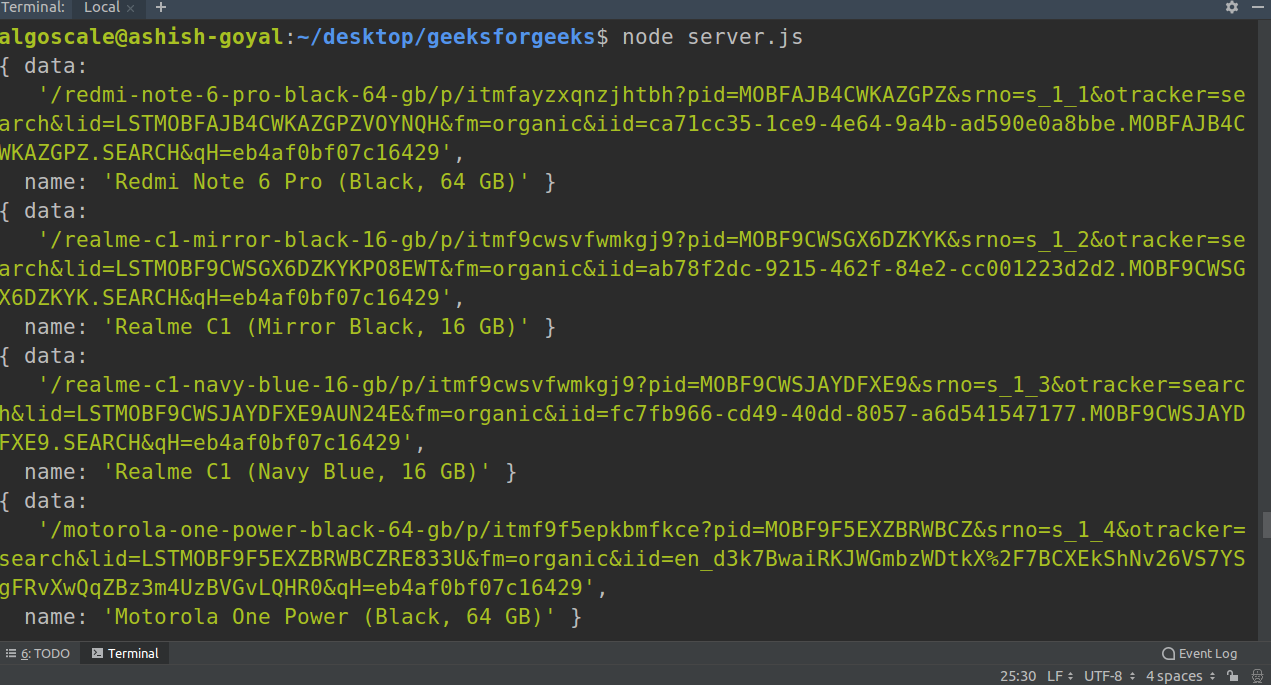
After successfully running the code, there is a file named data.txt also which has all the data extracted! we can find this file in our project directory.
So, it is a simple example of how to create a web scraper in nodejs using cheerio module. From here, you can try to scrap any other website of your choice. In case of any queries, post them below in comments section.
Share your thoughts in the comments
Please Login to comment...