A quick review of the present need to store massive chunks of data relevant to multiple related or unrelated categories, reveals that databases must be highly effective at what they are designed to do.
This is not only because of the amount of data being continuously revised or modified that we are dealing with the dynamics of it aren’t of sole interest anymore. It’s because of the social value that every individual has assigned to them: databases are the literal backbone of a client’s lifestyle or a business’s worth.
Designing different types of databases lies at the core of the functionality that they provide to the users. Since data is a dynamic entity, the way it is stored varies a lot. It is also the reason behind companies designing their own types of databases that comply with their needs. In this article, we will be discussing the types of Databases in detail.
Types of Databases
There are several types of databases, that are briefly explained below.
Hierarchical Databases
Just as in any hierarchy, this database follows the progression of data being categorized in ranks or levels, wherein data is categorized based on a common point of linkage. As a result, two entities of data will be lower in rank and the commonality would assume a higher rank. Refer to the diagram below:
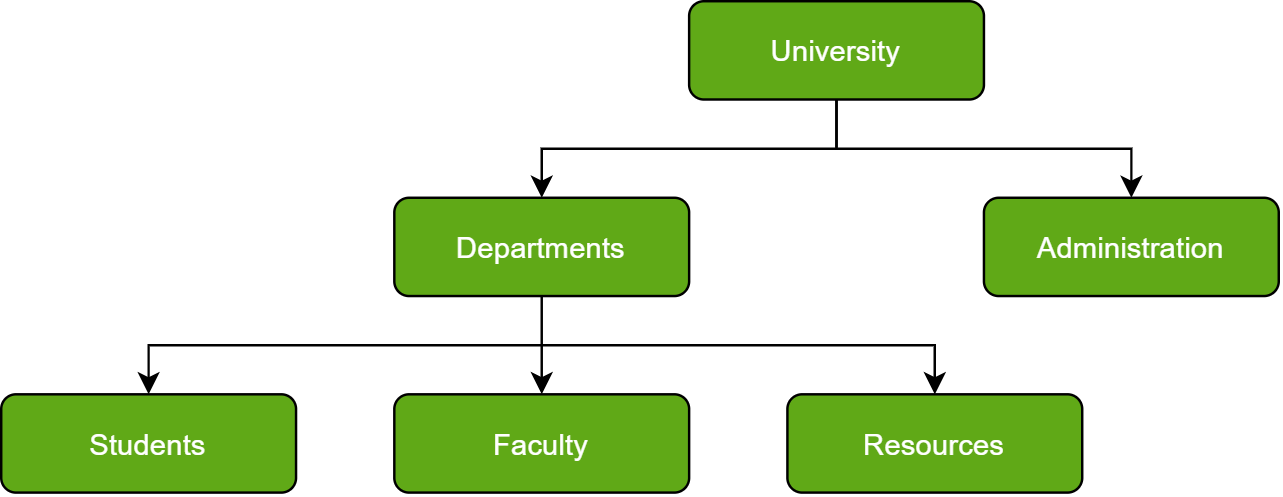
Hierarchical Database Example
Do note how Departments and Administration are entirely unlike each other and yet fall under the domain of a University. They are elements that form this hierarchy.
Another perspective advises visualizing the data being organized in a parent-child relationship, which upon addition of multiple data elements would resemble a tree. The child records are linked to the parent record using a field, and so the parent record is allowed multiple child records. However, vice versa is not possible.
Notice that due to such a structure, hierarchical databases are not easily salable; the addition of data elements requires a lengthy traversal through the database.
Network Databases
In Layman’s terms, a network database is a hierarchical database, but with a major tweak. The child records are given the freedom to associate with multiple parent records. As a result, a network or net of database files linked with multiple threads is observed. Notice how the Student, Faculty, and Resources elements each have two-parent records, which are Departments and Clubs.
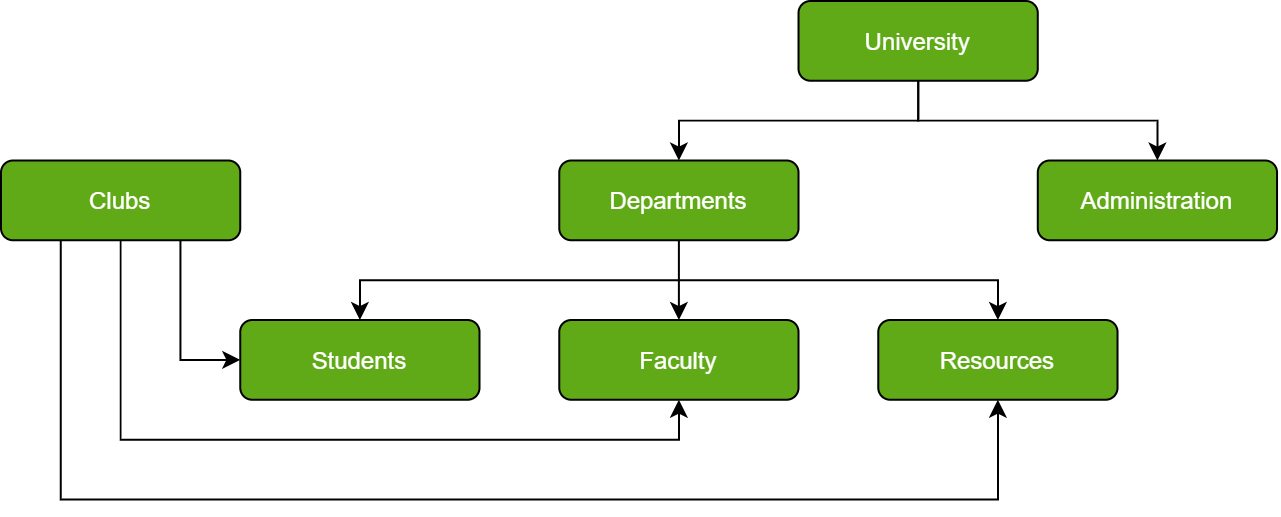
Network Database Example
Certainly, a complex framework, network databases are more capable of representing two-directional relationships. Also, conceptual simplicity favors the utilization of a simpler database management language.
The disadvantage lies in the inability to alter the structure due to its complexity and also in it being highly structurally dependent.
Object-Oriented Databases
Those familiar with the Object-Oriented Programming Paradigm would be able to relate to this model of databases easily. Information stored in a database is capable of being represented as an object which response as an instance of the database model. Therefore, the object can be referenced and called without any difficulty. As a result, the workload on the database is substantially reduced.
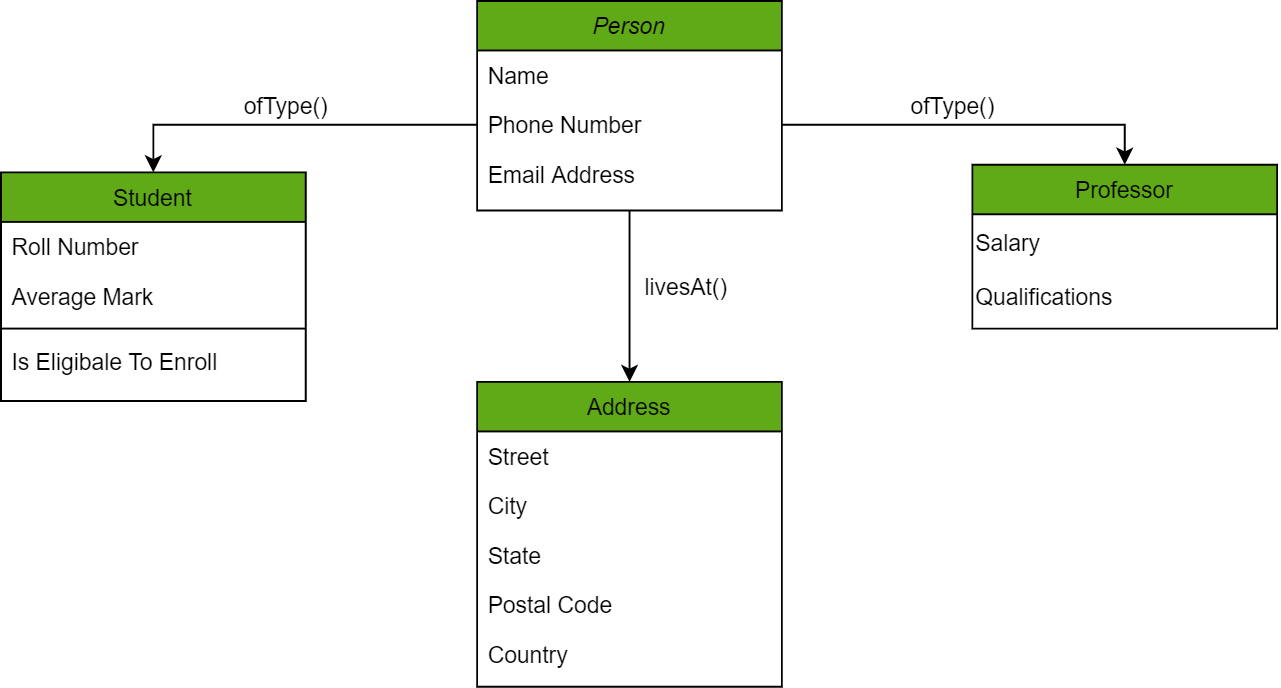
Object-Oriented Example
In the chart above, we have different objects linked to one another using methods; one can get the address of the Person (represented by the Person Object) using the livesAt() method. Furthermore, these objects have attributes which are in fact the data elements that need to be defined in the database.
An example of such a model is the Berkeley DB software library which uses the same conceptual background to deliver quick and highly efficient responses to database queries from the embedded database.
Relational Databases
Considered the most mature of all databases, these databases lead in the production line along with their management systems. In this database, every piece of information has a relationship with every other piece of information. This is on account of every data value in the database having a unique identity in the form of a record.
Note that all data is tabulated in this model. Therefore, every row of data in the database is linked with another row using a primary key. Similarly, every table is linked with another table using a foreign key.
Refer to the diagram below and notice how the concept of ‘Keys’ is used to link two tables.
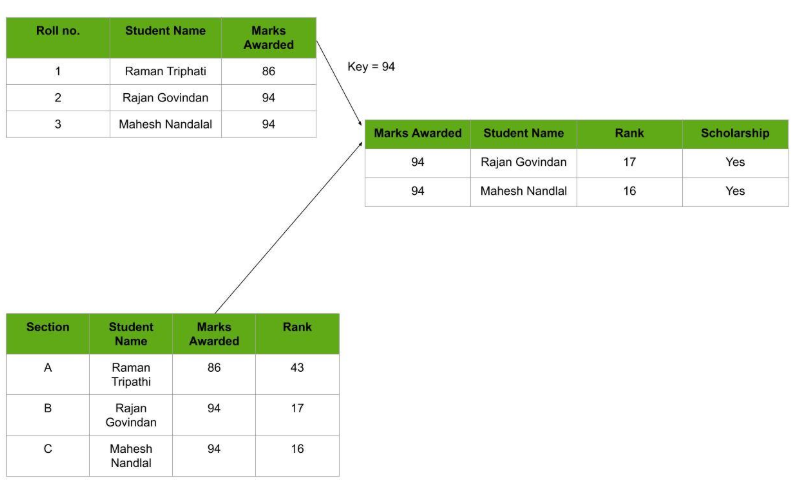
Relational Database Example
Due to this introduction of tables to organize data, it has become exceedingly popular. In consequence, they are widely integrated into Web-Ap interfaces to serve as ideal repositories for user data. What makes it further interesting is the ease in mastering it, since the language used to interact with the database is simple (SQL in this case) and easy to comprehend.
It is also worth being aware of the fact that in Relational databases, scaling and traversing through data is quite a light-weighted task in comparison to Hierarchical Databases.
Cloud Databases
A cloud database is used where data requires a virtual environment for storing and executing over the cloud platforms and there are so many cloud computing services for accessing the data from the databases (like SaaS, Paas, etc).
There are some names of cloud platforms are-
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
- Microsoft Azure
- ScienceSoft, etc.
Centralized Databases
A centralized database is basically a type of database that is stored, located as well as maintained at a single location and it is more secure when the user wants to fetch the data from the Centralized Database.
Advantages
- Data Security
- Reduced Redundancy
- Consistency
Disadvantages
- The size of the centralized database is large which increases the response and retrieval time.
- It is not easy to modify, delete and update.
Personal Databases
Collecting and Storing the data on its own System and this type of databases is basically designed for the single user.
Advantages
- It is easy to handle
- It occupies less space
Operational Databases
It is used for creating, updating, and deleting the database in real-time and it is basically designed for executing and handling the daily data operation in organizations and businesses purposes.
Advantages
- easy to fetch.
- Structured data
- Real-time processing
NoSQL Databases
A NoSQL originally referring to non SQL or non-relational is a database that provides a mechanism for storage and retrieval of data. This data is modeled in means other than the tabular relations used in relational databases.
A NoSQL database includes simplicity of design, simpler horizontal scaling to clusters of machines, and finer control over availability. The data structures used by NoSQL databases are different from those used by default in relational databases which makes some operations faster in NoSQL. The suitability of a given NoSQL database depends on the problem it should solve. Data structures used by NoSQL databases are sometimes also viewed as more flexible than relational database tables.
MongoDB falls in the category of NoSQL document-based database.
Advantages of NoSQL
There are many advantages of working with NoSQL databases such as MongoDB and Cassandra. The main advantages are high scalability and high availability.
Disadvantages of NoSQL
NoSQL has the following disadvantages.
- NoSQL is an open-source database.
- GUI is not available
- Backup is a weak point for some NoSQL databases like MongoDB.
- Large document size.
These are but a few types of database structures which represent the fundamental concepts extensively used in the industry. However, as mentioned earlier, clients tend to focus on creating databases which would suit their own needs; to store data in a schema which showcases a variable functionality based on its blueprint. Hence, the scope for development in reference to databases and database management systems is bright.
Frequently Asked Questions
Q.1: What are the most common SQL database types?
Answer:
Relational databases and non-relational databases are the two basic categories of databases in SQL.
Q.2: Which NewSQL databases are the mostly used?
Answer:
The most popular NewSQL databases are CockroachDB and NuoDB, Spanner etc.
Q.3: In SQL,What is a database?
Answer:
A database in SQL is an organized collection of Structured data. Databases help us with efficiently storing, accessing, and manipulating data held on a computer system or Server.
Share your thoughts in the comments
Please Login to comment...