Static Hashing in DBMS
Last Updated :
10 Apr, 2024
Static hashing refers to a hashing technique that allows the user to search over a pre-processed dictionary (all elements present in the dictionary are final and unmodified). In this article, we will take an in-depth look at static hashing in a DBMS.
What is Static Hashing?
When a search key is specified in a static hash, the hashing algorithm always returns the same address. For example, if you take the mod-4 hash function, only 5 values will be produced. For this to work, the output address must always be the same. The number of buckets at any given time is constant.
The data bucket address obtained by static hashing will always be the same. So, if we use the mod(5) hash function to get the address of EmpId = 103, we always get the same data bucket address 3. In this case, the data bucket position remains unchanged. Therefore, all existing data buckets in memory remain unchanged while the entire hashing process remains the same. In this case, there are five partitions in the memory used to hold data.
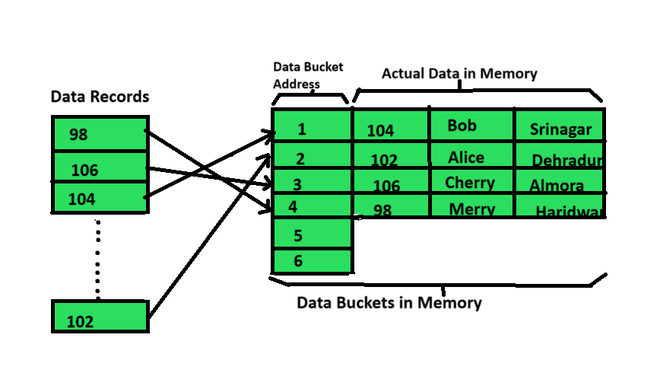
Data Buckets in Memory (Static Hashing)
What are the Operations in Static Hashing?
Searching the data: When data is needed, the same hash function is used to get the address of the packet where the data is stored.
Inserting Data: When new data is entered into the table, the hash key is used to create the address of the new data and place the data there.
Deleting a Record: To delete a record, we must first provide the record to be destroyed. The data of this address will be deleted from memory.
Updating a Record: To update the info, we will first find it using the hash function and then change the profile info. If we want to add data to the file, but the address of the dataset created by the hash function is not empty or there is data in the address, we cannot add information. Bucket overflow is the term used to describe this situation in static hashing.
There are many ways to solve bucket overflow problem. Here are some of the most common uses:
Open Hashing
When the hash function returns an address that already contains information, the next packet is assigned to it through a process called linear probing. For example, if the new address needed after input is R4, the hash function will produce 112 as the address of R4. However, the residence is completely finished; so the system selects 113 as the next available packet and assigns it R4.
Close Hashing
When the data group is full, a new bucket will be created for the same hash result and added after the old group. This method is called overflow chaining. For example, if the new address to be added to the file is R4, the hash function will give it address 112. But the bucket is too full to hold any more information. In this case, a new bucket will be placed and tied to the end of the 112 bucket.
Advantages of Static Hashing
The advantages of using static hashes in a DBMS are:
- Performance is very good for small data sets.
- Help with storage management.
- Hash keys facilitate access to address information.
- The primary key value can be used by the hash value.
Disadvantages of Static Hashing
Disadvantages of using static hashing techniques in DBMS are:
- Static hashing is not a good choice for big data.
- This process takes longer than usual because the hash function has to go through all memory locations in the DBMS system.
- Does not work with extensible databases.
- The sorting technique is not good compared to other hashing techniques.
Conclusion
Static hashing is one of many other hashing techniques used to show that data is not stored sequentially and also provides the correct memory address for each value in the data. Unlike other hashes, static hash methods can be used for static results without changing the values of objects, objects, and relational data in the DBMS.
Frequently Asked Questions on Static Hashing – FAQs
What is hash collision?
A hash collision occurs when the hash values of two or more files in the dataset are not assigned to the same location in the hash table.
What to do with hash conflicts?
There are two methods that can be used to avoid hash collisions which includes rehashing in which calls the association hash function, which is used repeatedly until space appears. Second method is the chaining method creates a linked list of objects whose keys have the same value. This method should have an extension for each address.
What is the time complexity of static hashing?
The Modulo Hash Function calculates the hash of key data and performs a modulo N operation to find the array index (node identifier) to store or retrieve a key. The time complexity of finding an identity in the static hash part is constant O(1).
Share your thoughts in the comments
Please Login to comment...