Are you preparing for an SQL Server interview? Preparing for a SQL Server interview requires a comprehensive understanding of SQL concepts, ranging from basic to advanced levels. Whether you’re a seasoned professional or a beginner, it’s essential to review and practice common interview questions to ensure readiness.
In this interview preparation guide, we’ll cover a range of SQL Server interview questions categorized by difficulty level, from easy to advanced, including query-based questions. From explaining fundamental SQL Server concepts to tackling complex query scenarios, this comprehensive resource will help you ace your SQL Server interview.

Top 50 SQL Server Interview Questions for 2024
The questions are categorized in the four levels:
Beginner SQL Server Interview Questions
Preparing for your initial SQL Server interview? Gain confidence by mastering foundational concepts. This guide explores frequently asked beginner questions on database creation, querying techniques, and table management.
1. Explain the Difference Between SQL and T-SQL.
|
Basis of Comparison
|
SQL
|
T-SQL
|
|
Stands For
|
Structured Query Language
|
Transact – SQL
|
|
Definition
|
Used for querying and manipulating data stored in a database.
|
It’s an extension of SQL that is primarily used in Microsoft SQL Server databases and software.
|
|
Feature
|
SQL is open-source.
|
T-SQL is developed and owned by Microsoft.
|
|
Functions
|
Basic functions provided by SQL standards
|
Additional functions provided by Microsoft SQL Server
|
|
Triggers
|
Supported, but specifics may vary between database systems
|
Supported, with specific syntax and features in Microsoft SQL Server
|
|
Error Handling
|
Basic error handling capabilities provided by SQL standards
|
Enhanced error handling features available in T-SQL
|
2. What are the Different Data Types Used in SQL Server?
In SQL Server, there are several data types used to define the type of data that can be stored in a column. Here are some of the commonly used data types:
- Numeric Data Types
- Character String Data Types
- Date and Time Data Types
- Binary Data Types
- Boolean Data Type
- Other Data Types
- XML
- JSON
- HIERARCHYID
3. How to Create a Table in SQL Server?
To create a table in SQL Server, you can use the CREATE TABLE statement followed by the table name and a list of column definitions.
CREATE TABLE TableName (
Column1 DataType1 [Constraint],
Column2 DataType2 [Constraint],
...
ColumnN DataTypeN [Constraint]
);
In addition, we can directly create the table using SQL Server Management Studio (SSMS).
4. What is the Purpose of an Alias in a Query?
In SQL Server, an alias is used to provide an alternative name for a table or a column in a query result set. The primary purposes of using aliases in a query are:
- Improved Readability: Aliases can make queries easier to read and understand.
- Avoiding Ambiguity: When a query involves multiple tables with columns having the same name, using aliases can help avoid ambiguity.
- Shortening Column Names: Alias allows us to give a shorter, more concise name for a column in the query result.
5. What is the Difference Between INNER JOIN and LEFT JOIN?
In SQL Server, INNER JOIN and LEFT JOIN are both types of join operations used to retrieve data from multiple tables based on a specified condition.

INNER JOIN
- An INNER JOIN returns only the rows where there is a match between the columns in both tables.
- It only returns rows where there is a match in both tables based on the specified join condition.
LEFT JOIN
- A LEFT JOIN returns all the rows from the left table, along with matching rows from the right table.
- If there is no matching row in the right table, NULL values will be returned for the columns from the right table.
6. How to Insert, Update, and Delete Data From a Table?
Insert Data: To insert data into a table, you use the INSERT INTO statement
INSERT INTO table_name (column1, column2,...)
VALUES (value1, value2,...);
Update Data: To update existing data in a table, you use the UPDATE statement
UPDATE TableName
SET Column1 = NewValue1, Column2 = NewValue2, ...
WHERE Condition;
Delete Data: To delete data from a table, you use the DELETE FROM statement
DELETE FROM TableName
WHERE Condition;
7. How to Grant Permissions to a User?
In SQL Server, you can grant permissions to a user using the GRANT statement. Permissions can be granted at various levels such as database level, schema level, table level, and even specific stored procedures or functions.
GRANT permission_type
ON [target]
TO user_name;
we can also grant permission using SQL Server Management Studio.
8. How to Create a Stored Procedure?
To create a stored procedure in SQL Server, we can use the CREATE PROCEDURE statement followed by the procedure name and its definition.
CREATE PROCEDURE procedure_name
@parameter1 data_type,
@parameter2 data_type,
...
AS
BEGIN
-- SQL statements
END;
9. What are the Basic Aggregate Functions?
In SQL Server, aggregate functions are used to perform a calculation on a set of values and return a single value. Here are some of the basic aggregate functions:
- COUNT(): This function counts the number of rows in a result set or the number of non-null values in a column.
- MAX(): This function returns highest value in a column.
- MIN(): This function returns lowest value in a column.
- SUM(): This function returns the sum of all values in a numeric column.
- AVG(): This function calculates the average value of a numeric column.
10. How to Use the LIKE Operator for Pattern Matching?
In SQL Server, the LIKE operator is used for pattern matching in string values. It allows you to search for strings that match a specified pattern, which may include wildcard characters.
SELECT column1, column2, ...
FROM table_name
WHERE column_name LIKE pattern;
11. What is the Difference Between a Scalar Function and a Table-Valued Function?
Scalar Function
- A scalar function is a user-defined function that returns a single scalar value (such as integer, string, or date) based on the input parameters.
- It operates on a single row of data at a time and returns a single value.
- They can be built-in, such as GETDATE(), LEN() or UPPER() or user-defined.
Table-valued Functions
- A table-valued function is a user-defined function that returns a table as its output.
- It operates on a set of input parameters and can return multiple rows of data.
12. Explain the Basic Concept of User-Defined Functions (UDFs).
- User-defined functions (UDFs) are procedures that accept arguments, do complicated procedures, and then return the result-set or the value.
- UDFs, three types of them, are user-defined scalar functions, table-valued functions and system functions.
We can use UDFs for the following reasons:
- They can be created, stored, and called at any number of times.
- They allow faster execution because UDFs don’t need to be reparsed or reoptimized.
- They minimize network traffic as it reduces the number of rows sent to the client.
13. How to Check the Execution Plan of a Query?
- On the toolbar, select Database Engine Query. we can also open an existing query and display the estimated execution plan by selecting the Open File toolbar button and locating the existing query.
- Enter the query for which we would like to display the estimated execution plan.
- On the Query menu, select Display Estimated Execution Plan or select the Display Estimated Execution Plan toolbar button. The estimated execution plan is displayed on the Execution Plan tab in the results pane.

Display Estimated Execution
14. Explain the Difference Between Clustered and Non-Clustered Indexes.
|
Feature
|
Clustered Index
|
Non – Clustered Index
|
|
Definition
|
It describes the order in which data is stored in tables physically.
|
It doesn’t sort tables physically inside a table but creates a logical order for stored data.
|
|
Key Structure
|
Contains the actual data rows.
|
Contains only pointers to the data rows
|
|
Index Key Columns
|
Each table will have only one clustered index.
|
There could be many non-clustered indexes for a table.
|
|
Data Accessing
|
Fast
|
Slow
|
15. When would We Create an Index?
We would typically create an index to improve the performance of queries that frequently search or filter data based on certain columns.
- Frequent Searches: Creating an index on columns used for filtering data can greatly improve query performance. It helps SQL Server quickly find the relevant rows needed for the query.
- Join Columns: Creating indexes on columns used for joining tables can speed up the join operation. It helps SQL Server efficiently locate matching rows, improving performance.
- Query Optimization: The SQL Server query optimizer uses indexes to determine the best way to execute a query. Building indexes helps the optimizer choose the most effective execution plan for our queries, improving performance.
- Aggregation: Aggregate functions (SUM, AVG, and COUNT) are optimized when applied on indexed columns.
This section delves into commonly encountered interview questions for intermediate users. Test your knowledge on topics like joins, functions, and performance optimization to impress your interviewer.
16. How to Determine If an Index is Effective?
- Execution Plans: Analyze the execution plans of queries that use the index. Look for Index Seek operations instead of Index Scan operations. Seek operations indicate that the index is effectively narrowing down the rows being retrieved.
- Query Performance: Measure the query execution time with and without the index. If the query performs significantly better with the index, it indicates that the index is effective.
- Index Usage Statistics: SQL Server maintains statistics about index usage. You can query dynamic management views like sys.dm_db_index_usage_stats to see how frequently an index is being used. If an index is rarely or never used, it might not be effective and could potentially be dropped.
- Index Design: Evaluate the design of the index itself. Consider factors such as the columns included in the index, their data types, and the order of columns.
17. Can We Write a Query to find Unused Indexes?
We can find unused indexes by querying the dynamic management views (DMVs) provided by SQL Server. Here’s a query to find unused indexes:
SELECT
OBJECT_NAME(s.[object_id]) AS TableName,
i.name AS IndexName,
i.type_desc AS IndexType,
s.user_seeks,
s.user_scans,
s.user_lookups,
s.user_updates
FROM
sys.dm_db_index_usage_stats AS s
INNER JOIN
sys.indexes AS i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id
WHERE
OBJECTPROPERTY(s.[object_id],'IsUserTable') = 1
AND s.database_id = DB_ID()
AND (s.user_seeks + s.user_scans + s.user_lookups) = 0
ORDER BY
TableName,
IndexName;
This query retrieves information about indexes along with their usage statistics. Unused indexes will have NULL values for user seeks, scans, and lookups but non-NULL values for user updates.
18. What are the Benefits of using Views in SQL Server?
- Simplicity and Abstraction: Views provide a way to abstract complex SQL queries into a single, easy-to-use object.
- Data Security: Views can be used to restrict access to certain columns or rows of a table. By granting users access to views rather than the underlying tables, you can implement security policies to control what data users can see.
- Performance Optimization: Views can help optimize query performance by precomputing joins, aggregations, or complex calculations.
- Simplified Data Access: Views can simplify data access by combining data from multiple tables into a single virtual table. This can eliminate the need for complex joins in application code, making queries more straightforward and easier to manage.
19. How to Create a View with Joins and Aggregates?
Here we have created a view named loss_summary_view with columns week, from_code, to_code, count_a, sum_x, sum_y, and sum_z. The view is constructed by selecting data from tables history and calendar and performing joins and aggregate functions.
CREATE VIEW loss_summary_view (week, from_code, to_code, count_a, sum_x, sum_y, sum_z)
AS
SELECT c.week, h.from_code, h.to_code, COUNT(h.a) AS count_a, SUM(h.x) AS sum_x, SUM(h.y) AS sum_y, SUM(h.z) AS sum_z
FROM history AS h
JOIN calendar AS c ON c.month = 100610 AND c.day = h.day
GROUP BY c.week, h.from_code, h.to_code;
20. How to Update Data through a View?
Create a view showing customers from Paris using the WITH CHECK OPTION statement.
CREATE VIEW vwCustomersParis
AS
SELECT CompanyName, ContactName, Phone, City
FROM Customers
WHERE City = 'Paris'
WITH CHECK OPTION
Update the above created view by moving everyone from Paris to Lyons.
UPDATE vwCustomersParis
SET City = 'Lyons'
The above statement update data by moving everyone from Paris to Lyons will fail because Lyons does not meet the criteria defined in the view.
21. Explain the Security Implications of using Views.
- Data Restriction: Views can restrict access to sensitive data by exposing only specific columns or rows from underlying tables. This allows administrators to control who can see what data, enhancing overall data security.
- Access Control: By granting permissions on views rather than underlying tables, administrators can implement fine-grained access control. This means users can be given access to specific views without needing direct access to the underlying tables, reducing the risk of unauthorized data access.
- Data Masking: Views can be used to apply data masking techniques, such as replacing sensitive data with masked values or aggregating data to provide a summarized view while protecting underlying details. This helps prevent unauthorized users from accessing sensitive information.
22. How to Identify Performance Bottlenecks in a Query?
- To identify performance bottlenecks, start by monitoring our queries for execution time, resource consumption, and query plan.
- Tools like SQL Server Profiler can help capture and analyze query metrics, highlighting queries that are slow, resource-intensive, or have suboptimal plans.
- Use SQL Server Management Studio (SSMS) or another database management tool to execute the query and view its execution plan. Look for areas with high estimated or actual costs, such as table scans, index scans, key lookups, or sorts.
23. What are some Techniques for Query Optimization?
- Query Execution Plans: The query execution plan in SQL Server details how a query is executed. It shows which tables are accessed, how they are accessed, how they are joined, and any other operations performed.
- Statistics: Regularly update statistics to ensure the query optimizer has accurate information for generating efficient execution plans. Use the UPDATE STATISTICS command or enable auto-update statistics.
- Query Rewriting: Rewrite queries to use more efficient syntax or to optimize joins, filters, and subqueries. Simplify complex queries to improve performance.
- Avoid Cursors: Avoid using cursors whenever possible, as they can lead to poor performance. Instead, use set-based operations like SELECT, INSERT, UPDATE, and DELETE to manipulate data.
24. Explain the Role of Statistics in Query Optimization.
- Query Plan Generation: When SQL Server receives a query, the query optimizer evaluates various execution plans to determine the most efficient way to retrieve the required data. Statistics provide the optimizer with estimates of the number of rows and data distribution, helping it choose the optimal plan.
- Index Selection: Statistics help the optimizer decide whether to use indexes or perform a table scan.
- Join Order and Join Type Selection: Statistics provide information about the size and selectivity of tables involved in join operations.
25. How can we Use Partitioning to Improve Performance?
- For very large databases and tables, such as one with 27 billion rows, table partitioning can significantly improve query performance. By partitioning a table, queries can be applied to only the relevant partitions, making them more efficient and faster.
- Partitioning simplifies data management by logically dividing large tables or indexes into smaller, more manageable partitions. This can lead to faster data loads, deletes, and index rebuilds, as operations are performed on smaller subsets of data.
- Partitioning can increase parallelism by allowing SQL Server to process multiple partitions concurrently. This can lead to faster query execution times, especially for CPU-bound queries that can benefit from parallel processing.
26. Describe Different Authentication Modes in SQL Server.
In SQL Server, there are two different kinds of authentication modes:
- Windows Authentication Mode: In Windows Authentication mode, SQL Server uses the Windows username for authentication, and the SQL Server username and password boxes are disabled. Authentication is based on Windows credentials rather than SQL Server credentials.
- Mixed Mode: SQL Server supports both Windows and SQL Server authentication modes. we can require a username and password for authentication, allowing users to connect through either Windows authentication or SQL Server authentication. Administrators can maintain user accounts in SQL Server.
27. How can we Implement Role-Based Access Control (RBAC) in SQL Server?
1. Identify Roles: Determine the roles needed for our application or system.
2. Create Database Roles: Use the CREATE ROLE statement to create database roles that correspond to the identified roles.
CREATE ROLE SalesRole;
CREATE ROLE HRRole;
3. Assign Permissions to Roles: Grant appropriate permissions to each role using the GRANT statement.
GRANT SELECT, INSERT, UPDATE, DELETE ON dbo.SalesTable TO SalesRole;
GRANT SELECT, INSERT, UPDATE, DELETE ON dbo.EmployeeTable TO HRRole;
4. Assign Users to Roles: Add users to the appropriate roles using the ALTER ROLE statement or the sp_addrolemember stored procedure.
ALTER ROLE SalesRole ADD MEMBER SalesUser;
EXEC sp_addrolemember 'HRRole', 'HRUser';
5. Use Role-Based Security: Modify our application or system to utilize role-based security. Instead of directly granting permissions to users, check their roles and grant permissions based on their roles.
IF USER_IN_ROLE('SalesRole')
BEGIN
-- Allow access to sales-related functionality
END
ELSE IF USER_IN_ROLE('HRRole')
BEGIN
-- Allow access to HR-related functionality
END
28. What are Stored Procedures and How can they Improve Security?
Stored procedures in SQL Server are precompiled sets of SQL statements that can be reused.

Stored procedures can improve security in several ways:
- Access Control: Granting permissions to execute stored procedures instead of directly on tables controls data access tightly.
- Parameterized Queries: Stored procedures accept parameters, preventing SQL injection attacks.
- Transaction Management: They manage transactions, ensuring data integrity by grouping SQL statements into atomic operations.
29. Explain Different Types of Replication in SQL Server.
In SQL Server, three different types of replications are available:
- Snapshot replication: Snapshot replication is ideal for replicating data that changes infrequently and is easy to maintain. For example, it can be used to distribute lists that are updated once per day from a main server to branch servers.
- Transactional replication: Transactional replication is a method of data distribution from a publisher to a subscriber. It is suitable for scenarios where data changes frequently.
- Merge replication: Merge replication consolidates data from various sources into a single centralized database. It is used when central and branch databases need to update information simultaneously.
30. When would we use Transactional Replication Versus Merge Replication?
Transactional Replication:
- For near real-time data distribution from a publisher to subscribers.
- One-way replication with minimal latency.
Merge Replication:
- For bidirectional synchronization of frequently changing data.
- Suitable for scenarios with disconnected or mobile clients.
Advanced SQL Server Interview Questions
Elevate your interview preparation by deep diving into advanced SQL Server interview question section. Be ready to showcase your expertise with complex queries, performance optimization strategies, and intricate server administration tasks.
31. How do we Configure and Manage Replication in SQL Server?
Configuring and managing replication in SQL Server involves several steps. Here’s a general overview:
- Identify Publisher and Distributor.
- Choose replication type: Snapshot, Transactional, or Merge.
- Set up publication to specify data to replicate.
- Define subscriptions for where replicated data will be delivered.
- Monitor replication status and performance using SSMS or Replication Monitor.
- Handle maintenance tasks such as index maintenance and backup/restoration.
32. Explain Different High Availability Solutions in SQL Server (e.g., Always On Availability Groups).
Always On Availability Groups:
- Provides data protection and availability.
- Allows multiple readable secondary replicas.
- Supports automatic failover.
Failover Clustering:
- Offers high availability at the instance level.
- Uses shared storage and multiple servers for failover.
Database Mirroring:
- Provides high availability at the database level.
- Being deprecated in favor of Always On Availability Groups.
Log Shipping:
- Copies transaction log backups to secondary databases.
- Supports manual failover.
Replication:
- Replicates data from one database to another.
- Supports data distribution and scalability but not automatic failover.
33. How to Configure And Manage Always On Availability Groups?
Configuring and managing Always On Availability Groups (AGs) in SQL Server involves several steps. Here’s a general guide:
- Enable Always On Availability Groups
- Create an Availability Group
- Add Databases to the Availability Group
- Configure Availability Group Replicas
- Join Secondary Replicas
- Monitor Availability Groups
- Maintenance and Troubleshooting
Always On Availability Groups provide high availability and disaster recovery solutions for SQL Server databases.
34. What are the Considerations For Disaster Recovery in SQL Server?
- Implement regular backups and store them offsite.
- Use high availability solutions like Always On Availability Groups or Failover Clustering.
- Set up database mirroring or log shipping for standby servers.
- Plan for point-in-time recovery with transaction log backups.
- Develop and test a comprehensive disaster recovery plan.
- Monitor systems for early detection of issues.
- Ensure security and compliance in disaster recovery plans.
- Document procedures and key contacts for quick response.
35. Can we Write a Script to Import Data from a Flat File into a Table in SQL Server?
Yes, we can write a script to import data from a flat file into a table in SQL Server. Here’s an example script using the BULK INSERT statement:
BULK INSERT TableName
FROM 'C:\Path\To\Your\File.csv'
WITH
(
FIELDTERMINATOR = ',', -- Specify the field terminator
ROWTERMINATOR = '\n', -- Specify the row terminator
FIRSTROW = 2 -- Specify the first row to start importing data
);
In this script, replace TableName with the name of your SQL Server table and 'C:\Path\To\Your\File.csv' with the path to your flat file. Adjust FIELDTERMINATOR and ROWTERMINATOR as per your file format.
36. Explain how to Loop through a Result Set using Cursors in SQL Server.
To loop through a result set using cursors in SQL Server, you can follow these steps:
- Declare Cursor: Declare a cursor and specify the SELECT statement that defines the result set.
- Open Cursor: Open the cursor to start fetching rows from the result set.
- Fetch Rows: Use a loop to fetch rows one by one from the cursor.
- Process Rows: Inside the loop, process each fetched row as needed.
- Close Cursor: After looping through the result set, close the cursor to release resources.
- Deallocate Cursor: Optionally, deallocate the cursor to free memory resources.
37. How can we use Error Handling in T-SQL scripts?
In T-SQL scripts, error handling can be implemented using the TRY…CATCH construct.
BEGIN TRY
-- T-SQL statements that might raise an error
-- For example:
SELECT 1/0; -- This will raise a divide by zero error
END TRY
BEGIN CATCH
-- Catch block to handle the error
-- we can capture information about the error using functions like ERROR_NUMBER(), ERROR_MESSAGE(), etc.
PRINT 'An error occurred: ' + ERROR_MESSAGE(); -- Print the error message
-- Additional error handling logic can be implemented here
END CATCH;
Functions like ERROR_NUMBER(), ERROR_MESSAGE(), ERROR_STATE(), ERROR_SEVERITY(), and ERROR_PROCEDURE() can be used to retrieve information about the error.
38. Explain the Basic Components of SSIS packages.
The important component in SSIS package are:
- Data flow: The Data Flow is a key part of an SSIS package that moves and changes data from one place to another. It has three main parts: Source, Transformation, and Destination.
- Control flow: The Control Flow is where we define the order and execution of tasks in an SSIS package. It includes tasks like SQL and script execution, looping, conditional execution, and managing workloads.
- Package Explorer: The Package Explorer in SSIS helps developers navigate and manage package components. It shows a hierarchy of the package, including control flow tasks, data flow components, connection managers, variables, and event handlers.
- Event handler: An Event Handler in SSIS lets a package react to certain events as it runs. These events can be errors, warnings, task completion, package start, package end, and more. Event Handlers are useful for custom error handling, logging, notifications, or other actions based on specific events during package execution.
Query Based SQL Server Interview Questions
For our better understanding, we will considering the following tables to write queries.
Employee Table:
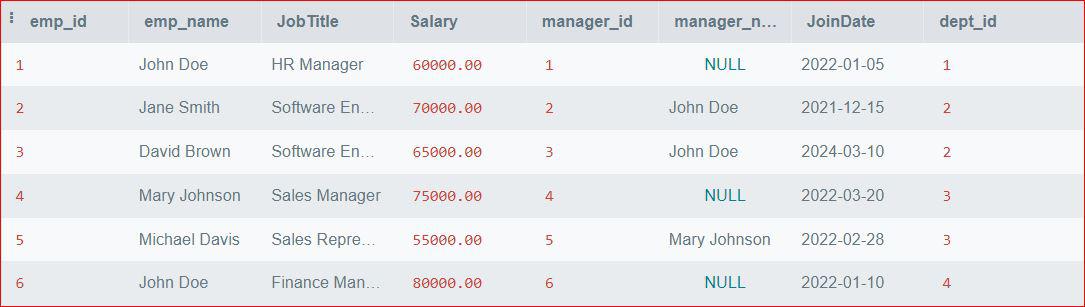
Employee Table
Departments Table:
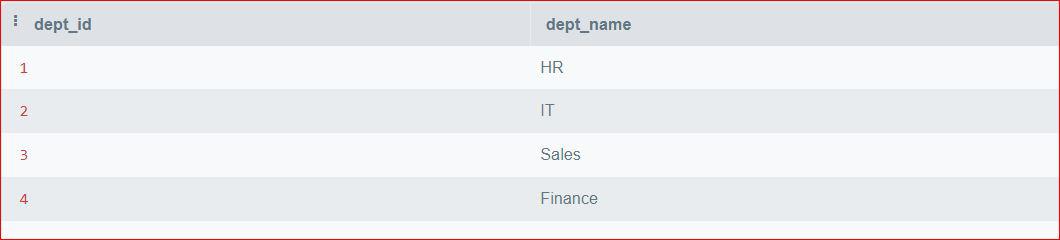
Departments Table
Sales Table:

Sales Table
Order Table:

Order Table
39. Write a SQL Query to Find the nth Highest Salary from an Employee Table.
SELECT DISTINCT TOP 1 Salary AS NthHighestSalary
FROM (
SELECT TOP 1 Salary
FROM Employees
ORDER BY Salary DESC
) AS NthHighestSalaries
ORDER BY Salary ASC;
Output:
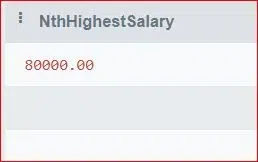
Highest salary
40. Write a SQL Query to Retrieve the Names of Employees who are also Managers.
SELECT e.emp_name
FROM Employees e
JOIN Employees m ON e.manager_name = m.emp_name;
Output:
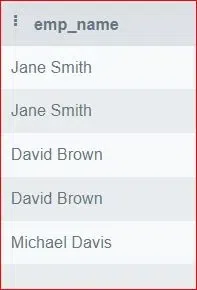
Output
41. Write a SQL Query to Find the Second Highest Salary from an Employee table.
SELECT MAX(Salary) AS salary
FROM Employees
WHERE Salary < (SELECT MAX(Salary) FROM Employees);
Output:
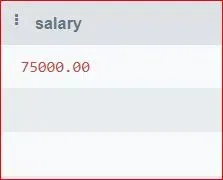
Second highest salary
42. Write a Query to Calculate the Total Number of Orders Placed by each Customer.(order table)
SELECT cust_ID, COUNT(*) AS TotalOrders
FROM Orders
GROUP BY cust_ID;
Output:
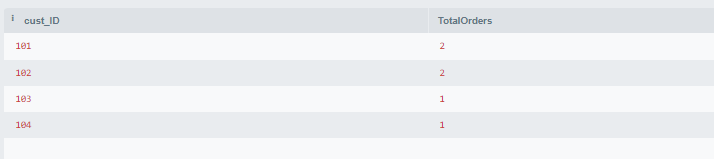
Output
43. Write a Query to Find Employees who have the Same Job Title but Different Salaries.
SELECT e1.emp_id , e1.emp_name, e1.JobTitle, e1.Salary
FROM Employees e1
JOIN Employees e2 ON e1.JobTitle= e2.JobTitle
WHERE e1.emp_id <> e2.emp_id AND e1.Salary <> e2.Salary
ORDER BY e1.job_title, e1.emp_id;
Output:

Output
44. Write a SQL Query to get the Top 5 Highest-Paid Employees.
SELECT TOP 5 * FROM Employees
ORDER BY Salary DESC;
Output:

Output
45. Write a Query to Find All Employees who Joined in the Last Month.
SELECT * FROM Employees
WHERE JoinDate>= DATEADD(MONTH, -1, DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0))
AND JoinDate< DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
Output:
No employees are there who joined in the last month.

Output
46. Write a SQL Query to Find Duplicate Records in a Table.
SELECT emp_name, COUNT(*) AS DuplicateCount
FROM Employees
GROUP BY emp_name
HAVING COUNT(*) > 1;
Output:

Output
47. Write a Query to Calculate the Average Salary of Employees in Each Department.
SELECT d.dept_name, AVG(e.Salary) AS AvgSalary
FROM Employees e
JOIN
Departments d ON e.dept_id = d.dept_id
GROUP BY d.dept_name;
Output:
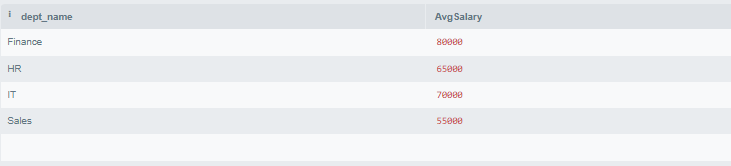
Output
48. Write a SQL Query to Find the Total Number of Products Sold each month.
SELECT
YEAR,
MONTH,
COUNT(*) AS TotalProductsSold
FROM
Sales
GROUP BY
YEAR,
MONTH
ORDER BY
YEAR,
MONTH;
Output:
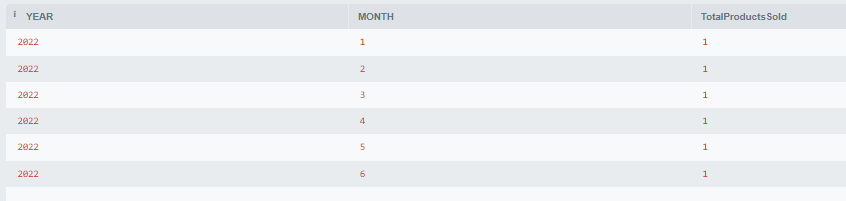
Output
49. Write a SQL Query to Identify Employees who have Duplicate Manager Names.
SELECT e1.emp_ID, e1.emp_name, e1.manager_name FROM Employees e1
JOIN Employees e2 ON e1.manager_name = e2.manager_name
WHERE e1.emp_ID <> e2.emp_ID
AND e1.emp_name <> e2.emp_name
ORDER BY e1.manager_name, e1.emp_ID;
Output:

Output
50. Write a Query to Fetch the Names of Employees Along with their Department Names.
SELECT e.emp_name, d.dept_name
FROM Employees e
JOIN Departments d ON e.dept_ID = d.dept_ID;
Output:
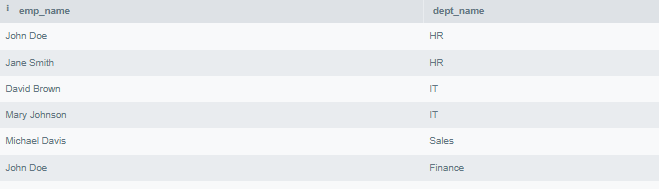
Output
Conclusion
mastering SQL Server interview questions is crucial for anyone aspiring to excel in database management roles. By delving into the topics covered in this guide, from basic SQL concepts to advanced techniques like query optimization and replication, you’re equipping yourself with the knowledge needed to ace SQL Server interviews.
Keep practicing, stay updated with the latest advancements in SQL Server technology, and approach each interview with confidence. With a solid understanding of SQL fundamentals and hands-on experience, you’ll be well-prepared to impress potential employers and secure your desired role in the ever-evolving world of database management.
Frequently Asked Questions – SQL Server Interview Question
Q. How do I prepare for a SQL interview?
Brush up on SQL fundamentals, practice queries, explore advanced topics (if needed), and hone your interview skills.
Q. What are the jobs in SQL Server?
There are multiple jobs in SQL Server like: Data scientist, Business analyst, Quality assurance engineer, Server engineer and more.
Q. What are the benefits of using SQL Server?
Using SQL Server offers benefits such as data security, reliability, scalability, and integration with other Microsoft products and technologies. It also provides tools for data analysis, reporting, and business intelligence.
Q. How can I learn SQL Server?
You can learn SQL Server through online tutorials, official Microsoft documentation, virtual labs, and training courses. There are also community forums and user groups dedicated to SQL Server where you can learn from experienced professionals and enthusiasts.
Q. What are the latest features in SQL Server?
The latest versions of SQL Server include features such as in-memory OLTP, always encrypted, enhanced security capabilities, improved query processing, and better integration with cloud services.
Share your thoughts in the comments
Please Login to comment...