Introduction:
User-level threads and kernel-level threads are two different approaches to implementing thread management in an operating system.
User-level threads are managed entirely by the application, without any involvement from the operating system kernel. The application manages the creation, scheduling, and synchronization of threads, using libraries such as pthreads or WinThreads. User-level threads are generally faster to create and switch between than kernel-level threads, as there is no need to switch to kernel mode or perform costly context switches.
However, user-level threads have some limitations. For example, if one thread blocks, the entire process may block, as the operating system is unaware of the thread’s status. Additionally, user-level threads cannot take advantage of multiple CPUs or CPU cores, as only one user-level thread can be executing at a time.
Kernel-level threads, on the other hand, are managed by the operating system kernel. Each thread is a separate entity with its own stack, register set, and execution context. The kernel handles thread scheduling, synchronization, and management, allowing multiple threads to execute simultaneously on different CPUs or cores.
Kernel-level threads are more heavyweight than user-level threads, as they require a context switch to kernel mode for thread management operations. However, kernel-level threads provide better isolation and control over thread execution, and can take advantage of multiple CPUs or cores to improve performance.
In summary, user-level threads provide fast and efficient thread management, but lack some of the benefits of kernel-level threads, such as support for multiple CPUs and better thread isolation. Kernel-level threads provide more robust thread management, but are more heavyweight and may be slower to create and switch between.
A task is accomplished on the execution of a program, which results in a process. Every task incorporates one or many sub tasks, whereas these sub tasks are carried out as functions within a program by the threads. The operating system (kernel) is unaware of the threads in the user space.
There are two types of threads, User level threads (ULT) and Kernel level threads (KLT).
- User Level Threads :
Threads in the user space designed by the application developer using a thread library to perform unique subtask.
- Kernel Level Threads :
Threads in the kernel space designed by the os developer to perform unique functions of OS. Similar to a interrupt handler.
There exist a strong a relationship between user level threads and kernel level threads.
Dependencies between ULT and KLT :
- Use of Thread Library :
Thread library acts as an interface for the application developer to create number of threads (according to the number of subtasks) and to manage those threads. This API for a process can be implemented in kernel space or user space. In real-time application, the necessary thread library is implemented in user space. This reduces the system call to kernel whenever the application is in need of thread creation, scheduling or thread management activities. Thus, the thread creation is faster as it requires only function calls within the process. The user address space for each thread is allocated at run-time. Overall it reduces various interface and architectural overheads as all these functions are independent of kernel support.
- Synchronization :
The subtasks (functions) within each task (process) can be executed concurrently or parallelly depending on the application. In that case, single-threaded process is not suitable. There evokes multithreaded process. A unique subtask is allocated to every thread within the process. These threads may use the same data section or different data section. Typically, threads within the same process will share the code section, data section, address space, open files etc.
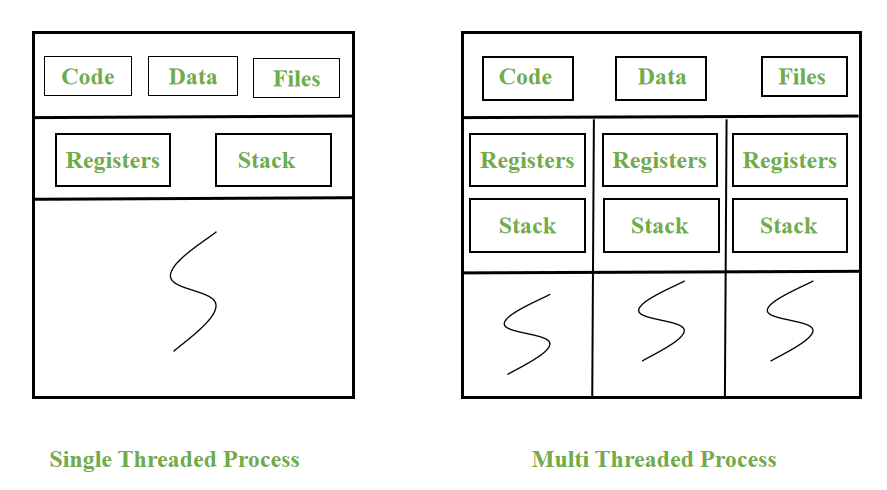
When subtasks are concurrently performed by sharing the code section, it may result in data inconsistency. Ultimately, requires suitable synchronization techniques to maintain the control flow to access the shared data (critical section).
In a multithreaded process, synchronization adopted using four different models :
- Mutex Locks – This allows only one thread at a time to access the shared resource.
- Read/Write Locks – This allows exclusive writes and concurrent read of a shared resource.
- Counting Semaphore – This count refers to the number of shared resource that can be accessed simultaneously at a time. Once the count limit is reached, the remaining threads are blocked.
- Condition Variables – This blocks the thread until the condition satisfies(Busy Waiting).
All these synchronization models are carried out within each process using thread library. The memory space for the lock variables is allocated in the user address space. Thus, requires no kernel intervention.
1. Scheduling :
The application developer during the thread creation sets the priority and scheduling policy of each ULT thread using the thread library. On the execution of program, based on the defined attributes the scheduling takes place by the thread library. In this case, the system scheduler has no control over thread scheduling as the kernel is unaware of the ULT threads.
2. Context Switching :
Switching from one ULT thread to other ULT thread is faster within the same process, as each thread has its own unique thread control block, registers, stack. Thus, registers are saved and restored. Does not require any change of address space. Entire switching takes place within the user address space under the control of thread library.
3. Asynchronous I/O :
After an I/O request ULT threads remains in blocked state, until it receives the acknowledgment(ack) from the receiver. Although it follows asynchronous I/O, it creates a synchronous environment to the application user. This is because the thread library itself schedules an other ULT to execute until the blocked thread sends sigpoll as an ack to the process thread library. Only then the thread library, reschedules the blocked thread.
For example, consider a program to copy the content(read) from one file and to paste(write) in the other file. Additionally, a pop-up that displays the percentage of progress completion.
This process contains three subtasks each allocated to a ULT,
- Thread A – Read the content from source file. Store in a global variable X within the process address space.
- Thread B – Read the global variable X. Write in the destination file.
- Thread C – Display the percentage of progress done in a graphical representation.
Here, the application developer will schedule the multiple flow of control within a program using the thread library.
Order of execution: Begins with Thread A, Then thread B and Then thread C.
Thread A and Thread B shares the global variable X. Only when after thread A writes on X, thread B can read X. In that case, synchronization is to be adopted on the shared variable to avoid thread B from reading old data.Context switching from thread A to Thread B and then Thread C takes place within the process address space. Each thread saves and restores the registers in its own thread control block (TCB). Thread C remains in blocked state, until thread B starts its first write operation on the destination file. This is the reason behind, the graphical indication of 100% pops-up a few seconds later although process completion.
Dependency between ULT and KLT :
The one and only major dependency between KLT and ULT arise when an ULT is in need of the Kernel resources. Every ULT thread is associated to a virtual processor called Light-weight process. This is created and bound to ULT by the thread library according to the application need. Whenever a system call invoked, a kernel level thread is created and scheduled to the LWPs by the system scheduler. These KLT are scheduled to access the kernel resources by the system scheduler which is unaware of the ULT. Whereas the KLT is aware of each ULT associated to it via LWPs.

What if the relationship does not exist?
If there is no association between KLT and ULT, then according to kernel every process is a single-threaded process. In that case,
- The system scheduler may schedule a process with threads that are of less priority or idle threads. This leads to starvation of high-prioritized thread, which in turn reduces the efficiency of the system.
- When a single thread gets blocked, the entire process gets blocked. Then the CPU utilization even in a multicore system will become much less. Though there may exist executable threads, kernel considers every process as a single threaded process and allocates only one core at a time.
- System scheduler may provide a single time slice irrespective of the number of threads within a process. A single threaded process and a process with 1000 threads provided with same time slice will make system more inefficient.
Here are some advantages and disadvantages of user-level threads and kernel-level threads:
Advantages of user-level threads:
- Lightweight: User-level threads are lightweight and fast to create and switch between, as they do not require kernel intervention.
- Flexible: User-level threads allow for greater flexibility in thread management, as the application can implement custom scheduling and synchronization strategies.
- Portable: User-level threads are portable across different operating systems and hardware architectures, as they are implemented entirely in user space.
Disadvantages of user-level threads:
- Lack of concurrency: User-level threads cannot take advantage of multiple CPUs or CPU cores, as only one thread can be executing at a time.
- Limited system awareness: User-level threads are not visible to the operating system, which can limit their ability to interact with system resources.
- Poor scalability: User-level threads can suffer from poor scalability when there are many threads, as the application may not have enough information to effectively manage them.
Advantages of kernel-level threads:
- Concurrency: Kernel-level threads can take advantage of multiple CPUs or CPU cores, allowing for greater concurrency and improved performance.
- Better resource management: Kernel-level threads are visible to the operating system, allowing for better resource management and scheduling.
- Robustness: Kernel-level threads are more robust than user-level threads, as they are not affected by application-level issues such as blocking or crashes.
Disadvantages of kernel-level threads:
- Overhead: Kernel-level threads are more heavyweight than user-level threads, as they require kernel intervention for management operations.
- Complexity: Kernel-level threads can be more complex to implement and manage, as they require more coordination between the operating system and the application.
- Less flexible: Kernel-level threads may be less flexible than user-level threads, as they are subject to the scheduling and management policies of the operating system.
Share your thoughts in the comments
Please Login to comment...