Relationship between Data Mining and Machine Learning
Last Updated :
30 Sep, 2022
There is no universal agreement on what “Data Mining” suggests that. The focus on the prediction of data is not always right with machine learning, although the emphasis on the discovery of properties of data can be undoubtedly applied to Data Mining always.
So, let’s begin with that: data processing may be a cross-disciplinary field that focuses on discovering the properties of knowledge sets. (Forget concerning it being the analysis step of “knowledge discovery in databases” KDD, this was perhaps valid years agone, it’s not anymore).
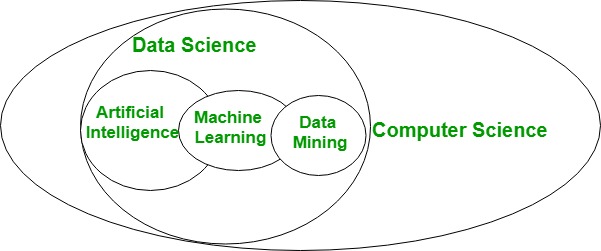
There are unit different approaches to discovering the properties of knowledge sets. Machine Learning is one of them. Another one is just gazing at the information sets victimization image techniques or Topological information Analysis.
On the opposite hand, Machine Learning may be a sub-field of knowledge science that focuses on planning algorithms that may learn from and create predictions on the information. Machine learning includes supervised Learning and Unsupervised Learning ways. Unsupervised ways take off from unlabelled information sets, so, in a way, they’re associated directly with looking for unknown properties in them (e.g., clusters or rules).
It is clear then that machine learning will be used for data processing. However, data processing will use different techniques besides or on high of machine learning.
To create things even a lot of sophisticated, currently, we have a replacement term, information Science, that’s competitory for attention, particularly with data processing and KDD. Even the SIGKDD cluster at ACM is slowly moving towards victimization information Science. On their website, they currently describe themselves as “The community for data processing, information science, and analytics.” According to the predictions, KDD can disappear as a term pretty before a lengthy edition, and data processing can merely merge into an information science.
Say the matter is to filter Outliers from your information (Anomaly detection), which might be a knowledge Mining task. One could build use of standard Machine Learning techniques like K-means algorithmic rule in Cluster analysis to spot these outliers and build the algorithmic rule to learn whereas doing this.
Now, these Outliers square measure ‘Previously Unknown, ’ and thus the task was the same be of information Mining, whereas Machine Learning comes into an image with the ‘Learning’ attribute of the algorithmic rule wont to find the outliers.
To “teach the machine” you wish information. As an example, if you would like to train a neural web for predicting the winner of the Superbowl, you can’t merely sort in UN agency won that game for the year. That’s not reaching to be enough. You will wish for a lot of information, like the maximum amount you’ll be able to get. You want each stat for each player ideally for his or her entire career. A lot of information you’ve got, a lot of the neural web will learn from the same details. I attempted coaching a neural network to form practical jokes and I had like 10kb of information. I believed that was loads, then found a diary wherever somebody was victimized over 3mb. That’s why you wish for data processing. If you’re thinking of the pc as someone, how long will it take someone to be told to speak? They observe several conversations; they don’t merely hear ten conversations then as if by magic become fluent. Thus essentially, data processing is one of the earliest steps toward machine learning. You mine the info, then organize, normalize, etc. because of the initial stages of coaching a neural web.
Share your thoughts in the comments
Please Login to comment...