PySpark Dataframe Split
Last Updated :
10 Jul, 2023
PySpark is an open-source library used for handling big data. It is an interface of Apache Spark in Python. It is fast and also provides Pandas API to give comfortability to Pandas users while using PySpark. Dataframe is a data structure in which a large amount or even a small amount of data can be saved. They are used in the fields of Machine Learning and Data Science. It contains ‘Rows’ and ‘Columns’.
In this article, we will learn different ways to split a Spark data frame into multiple data frames using Python.
Different Ways of Splitting Spark Datafrme
There are many ways by which you can split the Spark DataFrame into multiple DataFrames. Lets us see a few of these methods.
Split a Spark Dataframe into N equal Dataframes
In this method, we will be splitting a data frame into N equal data frames. For this, we will need a dictionary that stores the dataframe to be split into. The main approach to solve this problem is, if the dataframe is splittable into the given argument, then it will divide the data frame into that number of equal data frames and store it as values of keys in the dictionary or else it will just output that splitting the data frames into the expected number of data frames is not possible.
Example:
In this example, we define a function named split_df_into_N_equal_dfs() that takes three arguments a dictionary, a PySpark data frame, and an integer. This function splits the given data frame into N equal data frames and stores the resulting data frame in the dictionary. After that, we create a Pandas data frame and convert it into a PySpark data frame using session.createDataFrame(). After that, we print the original data frame using sp_df.show() function.
We create an empty dictionary df_dict used to store the splitted data frames and split_df_into_N_equal_dfs() function is called with the df_dict, sp_df, and 2 as arguments. This function splits the original data frame into two equal data frames and stores them in the dictionary df_dict with keys 0 and 1. The resulting data frame is then printed using the show() method.
Python3
import pyspark
import pandas as pd
session = pyspark.sql.SparkSession.builder.getOrCreate()
def split_df_into_N_equal_dfs(d, df, n):
if df.count()/n == int(df.count()/n):
rows = df.count()/n
start = 0
d_ix = 0
for i in range(1, df.count()+1):
if i % rows == 0:
d[d_ix] = session.createDataFrame(
df.collect()[start:i])
d_ix += 1
start = i
else:
print('Cannot make given number of\
equal DataFrames from the DataFrame')
df = pd.DataFrame({
'Odd_Numbers':[y for y in range(1,
17, 2)],
'Even_Numbers':[x for x in range(2,
17, 2)],
})
sp_df = session.createDataFrame(df)
print("Original Data frame")
sp_df.show()
df_dict = {}
split_df_into_N_equal_dfs(df_dict,
sp_df, 2)
print("Splitted Data frame")
df_dict[0].show()
df_dict[1].show()
|
Output:
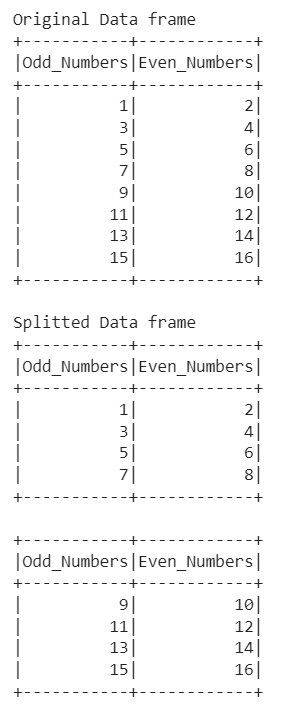
Split the dataframe into equal dataframes
Split a Spark Dataframe using filter() method
In this method, the spark dataframe is split into multiple dataframes based on some condition. We will use the filter() method, which returns a new dataframe that contains only those rows that match the condition that is passed to the filter() method.
Example:
In this example, we are splitting the dataset based on the values of the Odd_Numbers column of the spark dataframe. We created two datasets, one contains the Odd_Numbers less than 10 and the other more than 10.
Python3
import pyspark
import pandas as pd
session = pyspark.sql.SparkSession.builder.getOrCreate()
df = pd.DataFrame({
'Odd_Numbers':[y for y in range(1,
17, 2)],
'Even_Numbers':[x for x in range(2,
17, 2)],
})
df = session.createDataFrame(df)
print("Original Data frame")
df.show()
print("Splitted Dataframe")
df.filter(df['Odd_Numbers'] < 10).show()
df.filter(df['Odd_Numbers'] > 10).show()
|
Output:

Split the dataframe using filter() method
Split a Spark Dataframe using randomSplit() method
In this method, we will split the Spark dataframe using the randomSplit() method. This method splits the dataframe into random data from the dataframe and has weights and seeds as arguments.
Example:
In this example, we split the dataframe into two dataframes. The dataframes are divided based on the weights parameter of the randomSplit() function. The weights list is a list based on which the dataframe is split.
Python3
import pyspark
import pandas as pd
session = pyspark.sql.SparkSession.builder.getOrCreate()
df = pd.DataFrame({
'Odd_Numbers':[y for y in range(1,
17, 2)],
'Even_Numbers':[x for x in range(2,
17, 2)],
})
df = session.createDataFrame(df)
print("Original Data frame")
df.show()
weights = [4.0, 7.0]
splits = df.randomSplit(weights, seed=None)
print("Splitted Dataframe")
splits[0].show()
splits[1].show()
|
Output:

Split the dataframe using randomSplit() method
Share your thoughts in the comments
Please Login to comment...