In machine learning, feature selection is an essential phase, particularly when working with high-dimensional datasets. Although Support Vector Machines (SVMs) are strong classifiers, the features that are used might affect how well they perform.
This post will discuss the idea of ideal feature selection for support vector machines (SVMs), its significance, and doable methods for doing feature selection.
Feature Selection in Support Vector Machines
SVM is a supervised learning technique utilized for both regression and classification applications. The way it operates is by identifying the hyperplane that divides the data into the most different classes. SVMs are capable of successfully completing non-linear classification tasks as well as linear classification tasks by implicitly mapping their inputs into high-dimensional feature spaces.
A feature is a characteristic that affects an issue or is helpful for the problem; feature selection is the process of deciding which features are crucial for the model. The foundation of all machine learning procedures is feature engineering, which consists primarily of two steps: feature extraction and feature selection.
Feature selection is a technique to minimize the model’s input variable by using only pertinent data to lessen overfitting.
Why Feature Selection is Important?
Feature selection is important for support vector machine (SVM) classifiers for a variety of reasons:
- Enhanced Interpretability: By choosing the most relevant features, you gain a clearer understanding of which factors significantly affect the model’s predictions.
- Improved Efficiency: Reducing the feature set lowers training and prediction times, making the model more computationally efficient.
- Reduced Overfitting: Feature selection helps prevent the model from memorizing irrelevant details in the training data, leading to better generalization on unseen data.
- Better Generalization Performance: A model trained on a well-chosen feature subset is likely to perform better on new data compared to a model using all features.
- Addressing Curse of Dimensionality: In high-dimensional settings, SVMs can suffer from the curse of dimensionality, where performance degrades. Feature selection mitigates this effect.
Optimal Feature Selection for Support Vector Machines
The most discriminative and informative features for the particular machine learning task make up the optimal feature subset.
Popular methods for feature selection used with Support Vector Machines (SVMs) include forward feature selection, backward feature selection, and recursive feature elimination. These methods choose or remove features repeatedly according to how they affect the performance of the model. Let’s examine each strategy and offer code samples that make use of SequentialFeatureSelector from scikit-learn.
Forward Feature Selection
This method adds features to the feature set iteratively, one at a time, starting with a blank set of features. The feature that enhances the model’s performance the most at each step is chosen. The procedure is carried out repeatedly until the model’s performance shows no further improvement.
When there is a large number of features in the dataset and limited computational resources, forward feature selection is advantageous.
This sample implementation shows how to use the scikit-learn SequentialFeatureSelector for forward feature selection using the Support Vector Machine (SVM) estimator.
The algorithm iteratively chooses the most significant features based on the given estimator by using the fit method on the SequentialFeatureSelector object with the training data.
from sklearn.feature_selection import SequentialFeatureSelector
# Forward Feature Selection
sfs = SequentialFeatureSelector(estimator=svm, n_features_to_select=5, direction='forward')
sfs.fit(X_train, y_train)
selected_features = sfs.get_support(indices=True) # Selected feature indices
Backward Feature Selection
Backward feature selection, in contrast to forward feature selection, begins with every feature included and eliminates each feature one at a time. The least amount of model performance loss determines which feature should be eliminated. This method keeps going until the model’s performance does not improve with additional feature removal.
With limited computational resources, backward feature selection might be helpful because it starts with the entire feature set and gradually eliminates less significant characteristics.
from sklearn.feature_selection import SequentialFeatureSelector
# Backward Feature Selection
sfs = SequentialFeatureSelector(estimator=svm, n_features_to_select=5, direction='backward')
sfs.fit(X_train, y_train)
# Selected feature indices
selected_features = sfs.get_support(indices=True)
Recursive Feature Selection
Recursively eliminating features from the entire feature set is the process of recursive feature selection. Either the coefficient magnitude or feature relevance might serve as the selection criterion. The model is retrained using the remaining features after the least significant feature is eliminated at each phase. This method keeps going until the target feature count is reached or until removing more features noticeably impairs the performance of the model.
Recursive feature selection helps you find the most important characteristics while making the model’s computations less difficult. The example implementation demonstrates how to do recursive feature selection using scikit-learn’s.
from sklearn.feature_selection import RFECV
# Recursive Feature Selection
rfecv = RFECV(estimator=svm, step=1, cv=5)
rfecv.fit(X_train, y_train)
# Selected feature indices
selected_features = rfecv.support_
print(f"Selected feature indices - {selected_features}")
Implementing Optimal Feature Selection for SVMs
Implementing optimal feature selection for Support Vector Machines (SVMs) involves finding a subset of features that maximizes classification performance. Steps for Optimal Feature Selection for SVMs are below:
Step 1: Data Preparation
Here, we will be using the Breast Cancer Wisconsin (Diagnostic) dataset available in scikit-learn.
Python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# Load the dataset
data = load_breast_cancer()
X = data.data
y = data.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 2: SVM Classifier Initialization
Initializing the SVM classifier with the desired kernel using the scikit learn library. Here we will be using the ‘Linear’ kernel.
Python
from sklearn.svm import SVC
# Initialize SVM classifier
svm = SVC(kernel='linear')
Step 3: Feature Selection
From the various techniques, in this tutorial we will use the Recursive Feature Elimination (RFE) to select optimal features.
Python
from sklearn.feature_selection import RFE
from sklearn.feature_selection import RFECV
# Initialize RFE and fit to SVM model
rfecv = RFE(estimator=svm, n_features_to_select=10, step=1)
rfecv.fit(X_train, y_train)
# Selected feature indices
selected_features = rfecv.support_
Step 4: Model Training
Training the SVM model using the selected features.
Python
# Use selected features for training and testing
X_train_selected = X_train[:, selected_features]
X_test_selected = X_test[:, selected_features]
# Train SVM model with selected features
svm_selected = SVC(kernel='linear')
svm_selected.fit(X_train_selected, y_train)
Step 5: Model Evaluation
Python
# Evaluate model performance
accuracy = svm_selected.score(X_test_selected, y_test)
print("Accuracy with selected features:", accuracy)
Output:
Accuracy with selected features: 0.9473684210526315
Step 6: Visualizing
Python
import matplotlib.pyplot as plt
# Visualize the selected features
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(rfecv.support_) + 1), rfecv.support_)
plt.xlabel('Feature Index')
plt.ylabel('Selected')
plt.title('Recursive Feature Elimination')
plt.show()
Output:
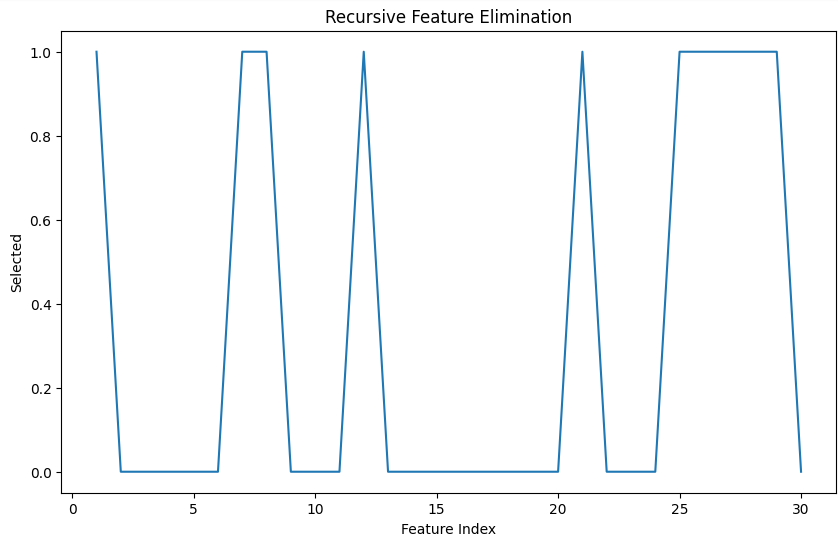
Visualization of the selected features
The above plot shows the optimal features selected for training. The x-axis denotes the features and y-axis denotes the confidence of a feature for optimal training. Here, some features have confidence of one meaning they are optimal and hence selected for training. Rest have zero confidence and hence not selected.
By following these procedures, you can enhance the accuracy and generalization capabilities of the model and efficiently carry out optimal feature selection for SVMs. For improved performance, you can optionally adjust the SVM hyperparameters or the chosen features like changing the number of features to be selected, kernel function, etc.
Why Recursive Feature Elimination is Used?
There are several reasons why RFE is commonly used:
- Ranking Features: RFE ranks features by their importance or relevance to the model’s performance. It does this by recursively removing the least significant features and retraining the model until the desired number of features is reached. By iteratively evaluating features, RFE provides a ranking that can help identify the most informative features for the model.
- Automatic Feature Selection: RFE automates the feature selection process, making it easier and less time-consuming for practitioners. Instead of manually trying different subsets of features, RFE systematically evaluates feature importance and selects the most relevant ones based on the model’s performance.
- Integration with SVMs: RFE works well with SVMs because SVMs inherently rely on a subset of training data points, known as support vectors, to define the decision boundary. Similarly, RFE focuses on selecting a subset of features that are most relevant for classification. This synergy between RFE and SVMs makes them a powerful combination for feature selection and classification tasks.
- Cross-Validation: Many implementations of RFE, such as the one provided by scikit-learn, incorporate cross-validation during the feature selection process. Cross-validation helps assess the generalization performance of the model and ensures that the selected features are not only relevant to the training data but also to unseen data.
- Reduction of Overfitting: By iteratively eliminating less important features, RFE helps prevent overfitting by focusing on the most discriminative features. Overfitting occurs when a model captures noise in the training data, leading to poor performance on unseen data. RFE’s feature selection process can mitigate this risk by selecting only the most relevant features.
Conclusion
The process of selecting optimal features is crucial in improving the interpretability, computational efficiency, and reduction of overfitting in Support Vector Machines (SVMs).
Share your thoughts in the comments
Please Login to comment...