Logistic Regression is a widely used classification algorithm in machine learning. However, to enhance its performance further specially when dealing with features of different scales, employing feature scaling ensemble techniques becomes imperative.
In this guide, we will dive depth into logistic regression, its significance and how feature sealing ensemble methods can augment its efficiency.
What is Logistic Regression?
Logistic regression is a statistical method used for solving binary classification problems, where the objective is to categorize instances into one of two classes: typically denoted as 0 or 1. In the context of machine learning, the input data comprises an m x n matrix, where m represents the number of observations and n denotes the number of features, each containing numerical values. The target variable, or dependent feature, is represented by a vector of size m, with each element having two potential outcomes.
Despite its name logistic regression is primarily a classification algorithm rather than a regression one. It predicts the probability that a given input belongs to a particular category by fitting a logistic function or sigmoid function to the observed data.
The logistic function also known as sigmoid function is used to convert the predicted values into probabilities. It maps any real valued number to a value between 0 and 1. This allows us to classify data points based on a threshold (e.g., anything above 0.5 probability is classified as positive).
What is Feature Scaling?
Feature scaling is a data preprocessing technique that standardizes the range of features within a dataset. This is important because features with vastly different scales can influence algorithms in unintended ways. For instance, during training, a model might prioritize features with larger values even if they are less informative. Scaling ensures all features contribute equally to the model’s learning process.
There are several common scaling techniques:
- Standardization (z-score normalization): This method transforms features by subtracting the mean and then dividing by the standard deviation. The resulting features have a mean of 0 and a standard deviation of 1.
- Min-Max Scaling: Here, features are scaled to a specific range, typically between 0 and 1 or -1 and 1. This is simpler than standardization but can be sensitive to outliers.
- Robust Scaling: This technique focuses on the median and interquartile range (IQR) of the data. It is less affected by outliers compared to standardization or min-max scaling.
Choosing the appropriate scaling technique depends on the data and the specific algorithm being used.
Introduction to Feature Scaling Ensemble
A feature scaling ensemble leverages the benefits of both feature scaling and ensemble learning. Ensemble learning combines predictions from multiple models to improve overall accuracy and robustness. In this context, we create multiple logistic regression models, each trained on data preprocessed with a different scaling technique.
The motivation behind this approach is to exploit the strengths of various scaling methods. For instance, some scalers might handle outliers better, while others might be more efficient for specific algorithms like logistic regression with regularization. By combining predictions from these diverse models, we aim to achieve better overall performance compared to a single logistic regression model with any one scaling technique.
Logistic Regression Implementation
In this implementation we will find prediction of the logistic regression model without feature scaling and then compare the accuracy of the model with integrating feature scaling techniques.
We have imported all necessary libraries in the implementation required for the tutorial.
Python3
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.pipeline import Pipeline
dataset = load_breast_cancer()
x = dataset.data
y = dataset.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print("Accuracy with no feature scaling :", accuracy_score(y_pred, y_test))
Output:
Accuracy with no feature scaling : 0.9649122807017544
For more refer to: Implementation of logistic regression from scratch
Logistic Regression with Min-Max Scaler
Min-Max scaling makes sure that all features are on a similar scale, typically between 0 and 1. It does this by subtracting the minimum value of the feature and then dividing by the difference between the maximum and minimum values. This ensures that the minimum value becomes 0 and the maximum value becomes 1, while other values are proportionally scaled in between.
Python3
scaler = MinMaxScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
model = LogisticRegression()
model.fit(x_train_scaled, y_train)
y_pred = model.predict(x_test_scaled)
print("Accuracy after applying Min-Max scaler :", accuracy_score(y_pred, y_test))
Output:
Accuracy after applying Min-Max scaler : 0.9824561403508771
Logistic Regression with Standard Scaler
Standardization or z-score normalization centers the data around 0 and scales it to have a standard deviation of 1 by subtracting the mean of the feature from each value and then dividing by the standard deviation. This ensures that the mean of the features becomes 0 and the standard deviation becomes 1, making the data more gaussian like.
Python3
# initializing scaler object
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
model = LogisticRegression()
model.fit(x_train_scaled, y_train)
y_pred = model.predict(x_test_scaled)
print("Accuracy after applying Standard scaler :", accuracy_score(y_pred, y_test))
Output:
Accuracy after applying Standard scaler : 0.9736842105263158
Logistic Regression with Robust Scaler
Robust scaling is particularly useful when dealing with outliers or non-normal distributions. It scales based on the median and interquartile range (IQR) rather than the mean and standard deviation. This makes it more robust to the outliers, as the median is less effected by the extreme values. It subtracts the median of the feature and then divides by the IQR, ensuring that the data is sealed proportionally while being less influenced by outliers.
Python3
# initializing scaler object
scaler = RobustScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
model = LogisticRegression()
model.fit(x_train_scaled, y_train)
y_pred = model.predict(x_test_scaled)
print("Accuracy after applying Robust scaler :", accuracy_score(y_pred, y_test))
Output:
Accuracy after applying Standard scaler : 0.9736842105263158
Logistic Regression with Feature Scaling Ensemble
While traditional feature scaling methods work well in many cases, they might not suffice when dealing with complex datasets containing features with vastly different scales or non-linear relationships. Feature scaling ensemble techniques offer a more sophisticated approach to address these challenges.
Ensemble methods combine multiple models to produce better predictive performance than any of the individual models alone. This approach aims to harness the strengths of different scaling methods while mitigating their respective weaknesses.
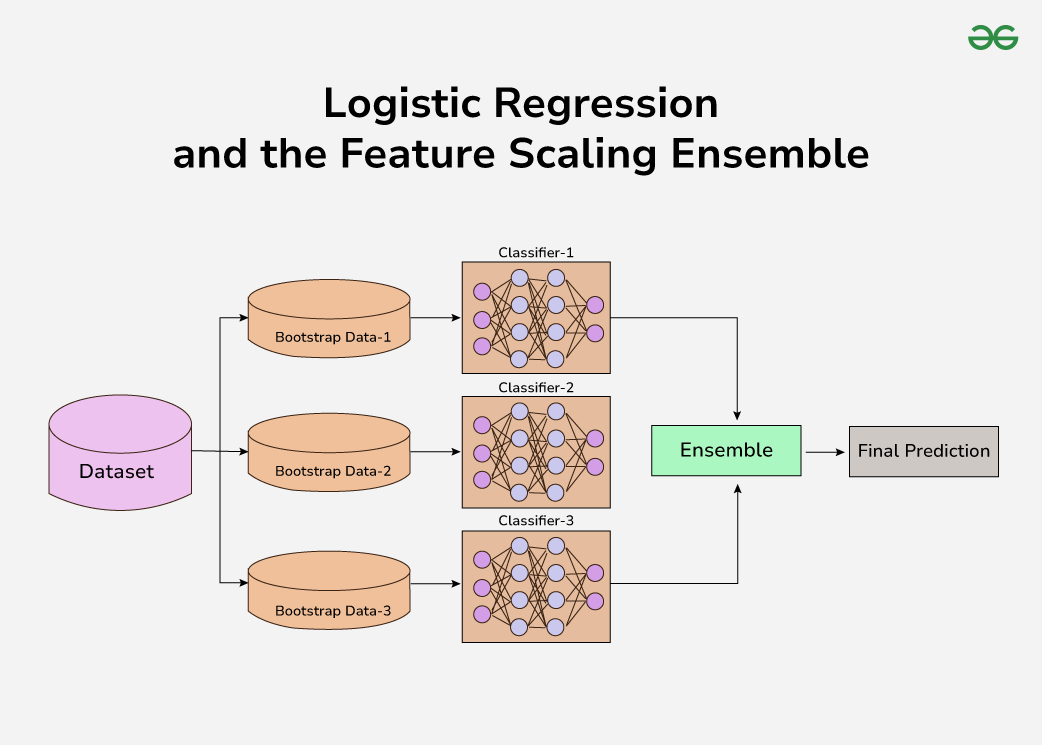
The classifier 1, 2 and 3 are Logistic Regression with Min-Max Scaler, Standard Scaler and Robust Scaler respectively. In this implementation, we aim to enhance the predictive performance of logistic regression by employing a feature scaling ensemble approach called Voting Classifier. Traditional logistic regression models may suffer from suboptimal performance when features exhibit varying scales. Feature scaling ensemble addresses this issue by leveraging multiple scaling techniques tailored to different subsets of features.
The use of pipelines facilitates a streamlined workflow by encapsulating feature scaling and logistic regression modeling within a single entity. Pipelines ensure consistency in preprocessing steps across training and testing datasets, simplifying code maintenance and reducing the risk of data leakage.
Python3
# Define pipelines for different scaling techniques
minmax_pipeline = Pipeline([
('scaler', MinMaxScaler()),
('clf', LogisticRegression())
])
standard_pipeline = Pipeline([
('scaler', StandardScaler()),
('clf', LogisticRegression())
])
robust_pipeline = Pipeline([
('scaler', RobustScaler()),
('clf', LogisticRegression())
])
Utilizing Voting Classifier for Aggregation
To consolidate the predictions from individual logistic regression models trained on scaled feature subsets, we employ a voting classifier. The voting classifier aggregates the predictions using either a hard or soft voting strategy. Hard voting selects the class with the most frequent prediction across all models, while soft voting considers the probability scores from each model, providing a more nuanced decision.
- Hard Voting: Hard voting is effective when the models in the ensemble have relatively high individual accuracies and diverse decision boundaries.
- Soft Voting: Soft voting considers the confidence levels (probability scores) of individual model predictions, resulting in a more nuanced decision. This strategy is beneficial when the models in the ensemble provide probability estimates, enabling a finer-grained aggregation of predictions.
Python3
# Initialize Voting Classifier with Logistic Regression models
voting_classifier_hard = VotingClassifier(estimators=[('model_minmax', minmax_pipeline), (
'model_standard', standard_pipeline), ('model_robust', robust_pipeline)], voting='hard')
voting_classifier_soft = VotingClassifier(estimators=[('model_minmax', minmax_pipeline), (
'model_standard', standard_pipeline), ('model_robust', robust_pipeline)], voting='soft')
Training and predictions of the Voting Classifier
Python3
voting_classifier_hard.fit(x_train, y_train)
voting_classifier_soft.fit(x_train, y_train)
y_pred_voting_hard = voting_classifier_hard.predict(x_test)
y_pred_voting_soft = voting_classifier_soft.predict(x_test)
accuracy_voting_hard = accuracy_score(y_test, y_pred_voting_hard)
accuracy_voting_soft = accuracy_score(y_test, y_pred_voting_soft)
print("Accuracy of hard Voting Classifier:", accuracy_voting_hard)
print("Accuracy of soft Voting Classifier:", accuracy_voting_soft)
Output:
Accuracy of hard Voting Classifier: 0.9736842105263158
Accuracy of soft Voting Classifier: 0.9824561403508771
Advantages of Feature Scaling Ensemble
- Improved Model Performance: By leveraging multiple feature scaling techniques, feature scaling ensemble methods can better handle diverse datasets, leading to enhanced model performance.
- Robustness to Data Characteristics: Feature scaling ensemble techniques are adaptable to different data distributions and are resilient to outliers, making them suitable for a wide range of real-world scenarios.
- Reduced Risk of Overfitting: Proper feature scaling can prevent overfitting by ensuring that the optimization process converges smoothly and that the model generalizes well to unseen data.
Disadvantages of Feature Scaling Ensemble
Potential downsides of the Feature Scaling Ensemble approach with Logistic Regression:
- Increased Computational Cost: Training multiple logistic regression models with different scaling techniques requires more computational resources compared to a single model. This can be a significant factor for large datasets or computationally expensive models.
- Interpretability Challenges: Combining predictions from multiple models can make it more difficult to interpret the reasons behind specific classifications. Understanding feature importance becomes less straightforward compared to a single model.
- Overfitting Potential: Ensemble methods, in general, are more prone to overfitting if not carefully tuned. With feature scaling ensembles, there’s a risk of overfitting to the specific scaling characteristics of the training data, potentially leading to poor performance on unseen data.
Conclusion
Logistic regression remains a powerful tool for classification tasks, offering simplicity and interpretability. However, to unleash its full potential, adequate preprocessing steps such as feature scaling are essential, particularly when dealing with datasets containing features of varying scales and distributions. Feature scaling ensemble techniques provide a robust approach to address these challenges, offering improved model performance, adaptability to different data characteristics, and reduced risk of overfitting.
By incorporating feature scaling ensemble methods into logistic regression pipelines, practitioners can ensure more reliable and effective classification outcomes across a wide array of applications.
Share your thoughts in the comments
Please Login to comment...