Google Cloud Platform (GCP) is a Cloud Service Provider that offers different service models like Iaas(Infrastructure as a service), Paas(Platform as a service), and Saas(Software as a service). Cloud SQL is a relational Database service offered by Google. Users can run MySQL, SQL Server, and PostgreSQL databases on GCP without having the headache of managing the infrastructure. In other words, Cloud SQL is fully managed by Google. Go through GCP account/project creation and Identity and Access Management before moving to this article to have a GCP account and relevant permission in place.
Configure SQL Instance
Step 1: Create an instance for MySQL DB in GCP. Create a MySQL DB With Cloud SQLOnce, the Cloud SQL instance is successfully created, and you can see an instance in GCP.
.jpg)
Step 2: By following default configurations, a highly available (multi-zonal) Cloud SQL instance will be created which will have Automatic backups enabled, point-in-time recovery enabled, and Instance Deletion protection enabled.
The default configuration allows multi-zone deployment (i.e., deployment to any zone other than primary)
Primary and Secondary Cloud SQL Instance
Given architecture diagram shows a primary Cloud SQL instance in us-central1-f and a secondary(stand-by) instance in us-central1-b. In case of a zonal failure, the stand-by instance is promoted to become a primary instance i.e., the instance is us-central1-b becomes a primary instance.
.png)
.jpg)
Step 3: Confirm the deployment status of the Primary instance and the zone to which the instance is deployed.

Primary instance deployed to us-central1-f
Step 4: Trigger instance failover by Clicking on FAILOVER in the top right corner, to test a zonal failure. In case of a Zonal failure, Cloud SQL will automatically fail over to the stand-by instance present in a different zone in the same region. This is done to validate HA within the same region

Trigger a failover manually to validate HA within a region.
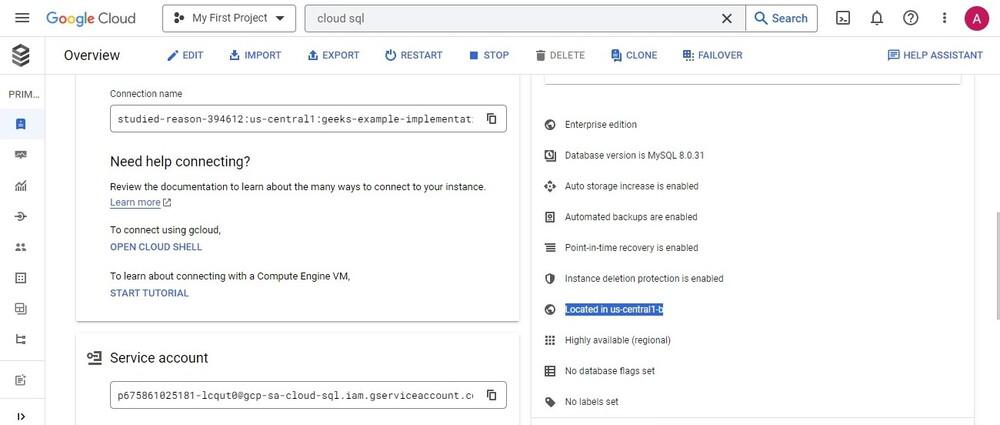
The primary Instance zone is updated to us-central1-b
So, as expected on triggering a manual failover the secondary instance got promoted to become the primary instance. The primary instance is now in us-central1-b.
What Happens If the Whole Region Goes Down?
In this scenario, the primary instance and standby instance both will go down. Regional failures are not common but are possible. A higher level of redundancy is required to resolve region failures. Cross-region High Availability can be enabled by creating a read replica in a different region. In case of a region failure, the read replica can be promoted to a primary instance, thereby ensuring cross-region HA.
Standby Instance
Given architecture diagram explains a primary instance a standby instance in us-central1 and a read replica and a DR (Disaster Recovery) read replica in us-east1. In case of a regional failure, the DR read replica is promoted to be the primary instance.

When the original primary instance in Region 1 goes down, the DR replica is promoted as the primary instance, but another read replica replication is stopped since it was sourced from the Primary instance in Region 1, thereby making it non-useful. Let’s Create a read-replica in a different region than a primary instance for Cross region HA (High Availability). Click on three dots from the Actions section and click on Create read replica option.

Create a read replica in different regions.
Choose Multi zones for zonal availability for the DR replica as well.
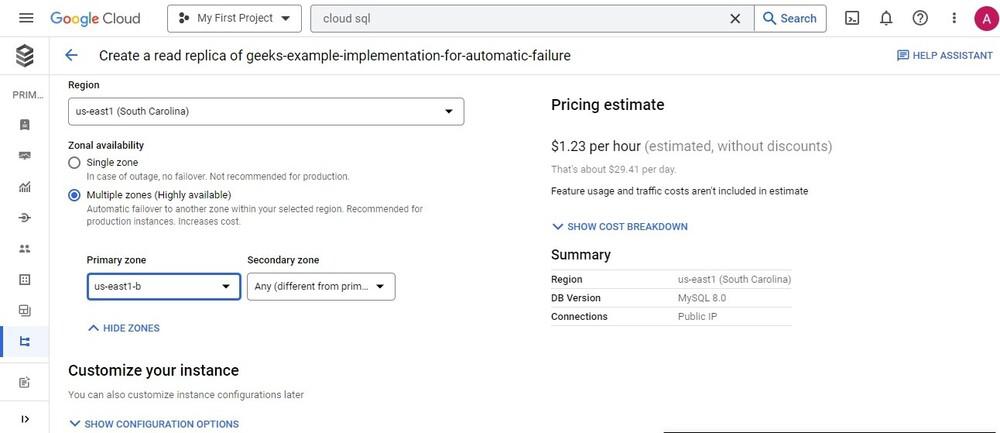
Make read-replica as HA (keep primary and secondary zone)
Multiple Read Replicas
If there are multiple read replicas, they are dependent on the primary instance for replication. In case of a region failure, the DR replica gets promoted to become a primary instance, but what about other read replicas?? All other read replicas have to be re-created and any applications that are accessing this replica have to update the endpoint.
The Given architecture diagram shows how in case of a regional failure, for replicas other than the DR (Disaster Recovery) replica, replication is stopped, thereby making them inoperable for read-only applications.

TrobuleShooting
Cascading replica: Instead of creating multiple replicas from the primary instance, read replicas can be sourced from Disaster recovery read replicas. In this way, the read replica for our read-only applications was already configured as a Cascading Replica of the DR read replica (newly promoted primary instance), it is already utilizing that instance as a source for replication. So, to sum up, no need to create other downstream replicas in case of regional failure since they are not sourced from a Primary instance but a DR read replica. The updated architecture diagram shows that the read replica in us-central1-f is sourcing data from the DR (Disaster Recovery) read replica rather than the primary instance in us-central1. In case of a regional failover in this architecture, the read-replica is not impacted, thereby continuing the replication from the DR replica (newly promoted Primary instance)

Steps To Create DR Replicas
Step 1: Select the DR (Disaster Recovery) read replica and open it. To Create a read replica out of the DR read replica point in time recovery has to be enabled. Click on Enable Replication
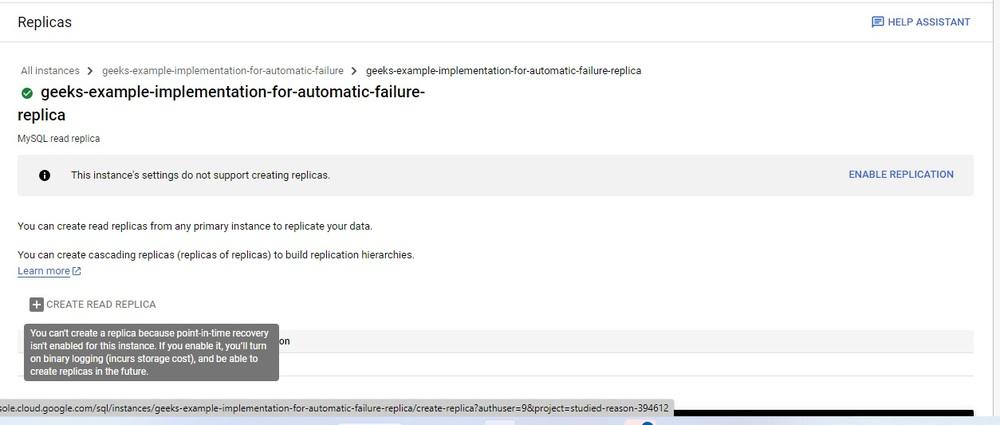
Step2: Click on Enable and Restart
-min.jpg)
Step 3: Click on CREATE READ REPLICA to start creating read replica sourcing from disaster recovery read replica.
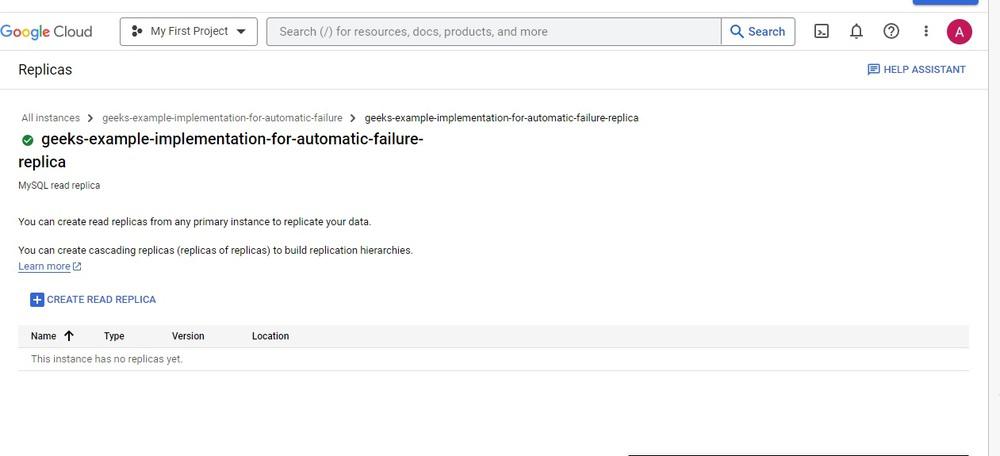
Step4: Make the Read replica to be Highly Available by making it multi-zonal
Let’s promote a DR read replica to a primary instance to simulate a regional failure by clicking on PROMOTE REPLICA option.
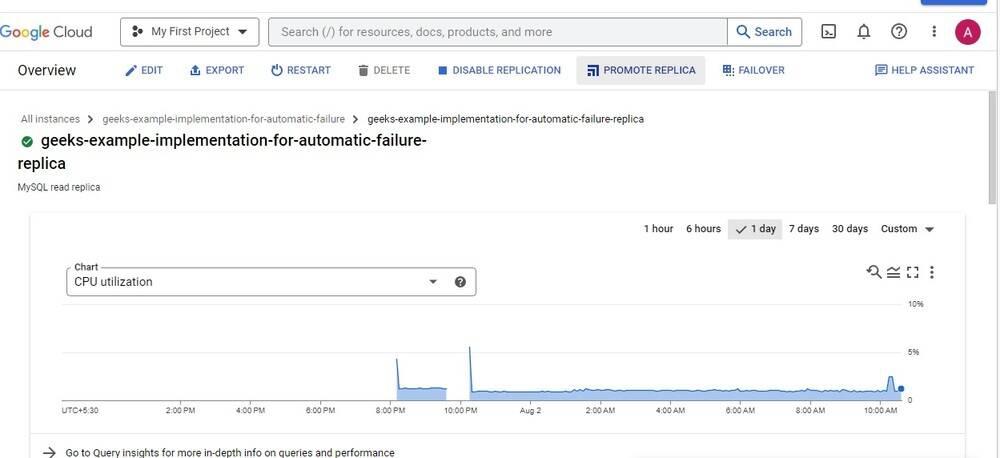
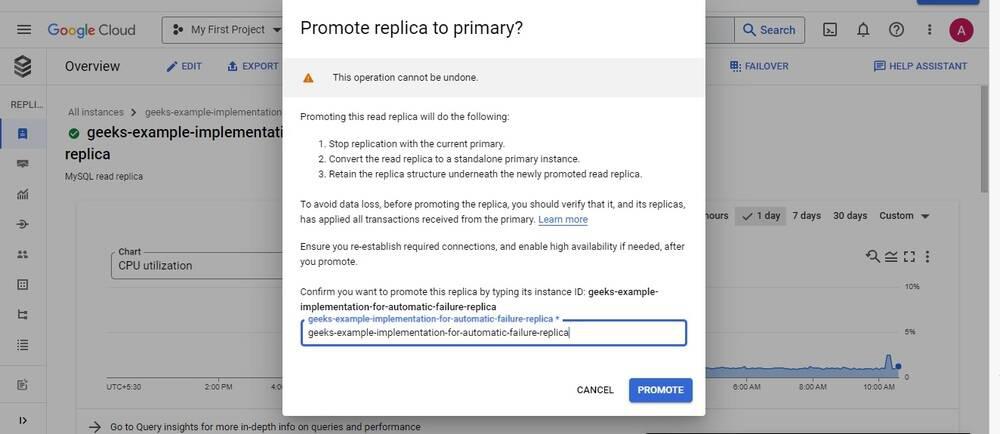
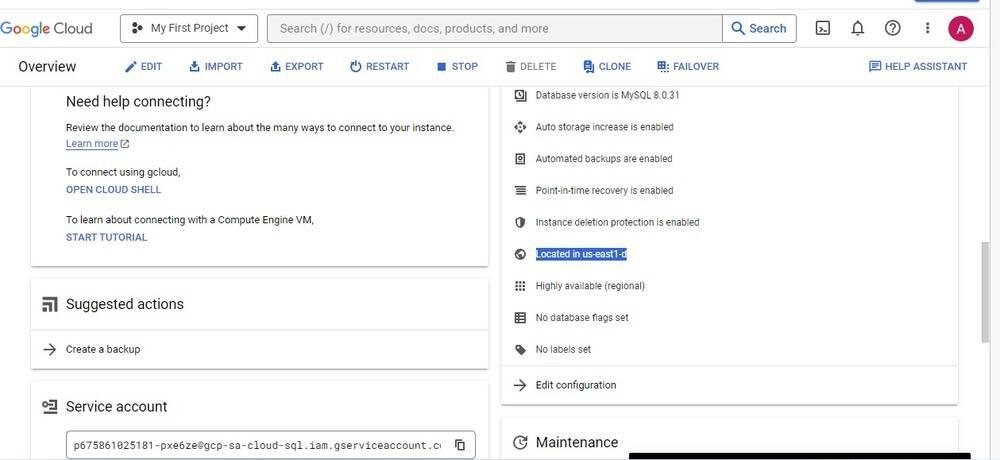
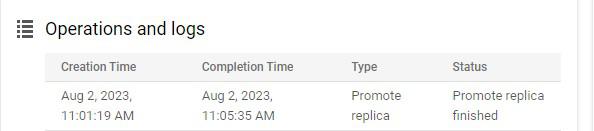
From the above screenshots, you can clearly see that on triggering the manual promotion of a DR read replica, it got promoted to the primary instance. The primary instance is now available in the us-east1-d. Promoting a read replica is an irreversible process and can’t be undone.
Automating the Process
You must have some automation in place to effectively reduce downtimes in case of a region failure. Automation of the process would cut down the cost by expediting the failover process. An automation script can be written that does automation of conducting a cross-region failover in Google Cloud SQL using HA Replicas and Cascading Replicas
- Provide the right GCP Project that the instance resides in
- Instance ID capture of the Primary Instance in the region that is down.
- Instance ID capture of the DR Read Replica that you want to failover to
- Instantiating the failover by promoting the DR Instance in the new region to the primary HA Cloud SQL instance
- Providing the connection details for the newly promoted HA Instance
- Replace the original Primary Instance with an HA Read Replica in the Same Region/Zone for future failovers
Conclusion
Cloud SQL provides native Highly available architecture within a single region. In case of zonal failure, Cloud SQL will automatically manage the failover by making the secondary zone instance to be primary without switching the IP. However, In case of a regional failover, read replicas are to be created in a different zone than the primary instance. Read replicas are promoted as primary HA in case of region failure. Cascading replicas are required since multiple read replicas being sourced from primary instances incorporate a dependency on the primary instance, if the primary instance goes down, these read replicas have to be deleted and re-created. In this scenario, the application fetching data from these read-replica will have to suffer some downtime, since new read-replica creation and endpoint update might take some time. To resolve this, Cascading read replicas can be created, A Cascading read-replica is a read-replica sourcing from another read-replica. The DR read replica can act as a source for other read replicas being created. This way, in case of a regional failure, no application will suffer a downtime since all the read replicas will be sourced from DR read replicas (which will be promoted to the Primary instance in case of regional failover). It’s highly recommended to incorporate these features in your architecture for a Highly available, fault-tolerant architecture that allows automatic failover, reducing downtime for the architecture implemented in GCP.
FAQs On Cloud SQL for MySQL with automatic failover on GCP
1. What Is Cloud SQL With Automatic Failover?
Cloud SQL is a managed GCP service offered by Google. Automatic failover is additional functionality that switches the primary instance to the backup instance in case of a failover.
2. How Does Automatic Failover Work?
In case of a zonal/regional failover and the primary instance goes down, the standby instance is promoted to become a primary instance thereby preventing downtime.
3. Why Is Automatic Failover Important?
It promotes the high availability of the cloud SQL instance by promoting the standby instance to the primary instance in case of a failover.
Share your thoughts in the comments
Please Login to comment...