How to Scrape Data From Local HTML Files using Python?
Last Updated :
21 Apr, 2021
BeautifulSoup module in Python allows us to scrape data from local HTML files. For some reason, website pages might get stored in a local (offline environment), and whenever in need, there may be requirements to get the data from them. Sometimes there may be a need to get data from multiple Locally stored HTML files too. Usually HTML files got the tags like <h1>, <h2>,…<p>, <div> tags etc., Using BeautifulSoup, we can scrap the contents and get the necessary details.
Installation
It can be installed by typing the below command in the terminal.
pip install beautifulsoup4
Getting Started
If there is an HTML file stored in one location, and we need to scrap the content via Python using BeautifulSoup, the lxml is a great API as it meant for parsing XML and HTML. It supports both one-step parsing and step-by-step parsing.
The Prettify() function in BeautifulSoup helps to view the tag nature and their nesting.
Example: Let’s create a sample HTML file.
Python3
import sys
import urllib.request
original_stdout = sys.stdout
outputHtml = webPageResponse.read()
with open('samplehtml.html', 'w') as f:
sys.stdout = f
print(outputHtml)
sys.stdout = original_stdout
|
Output:
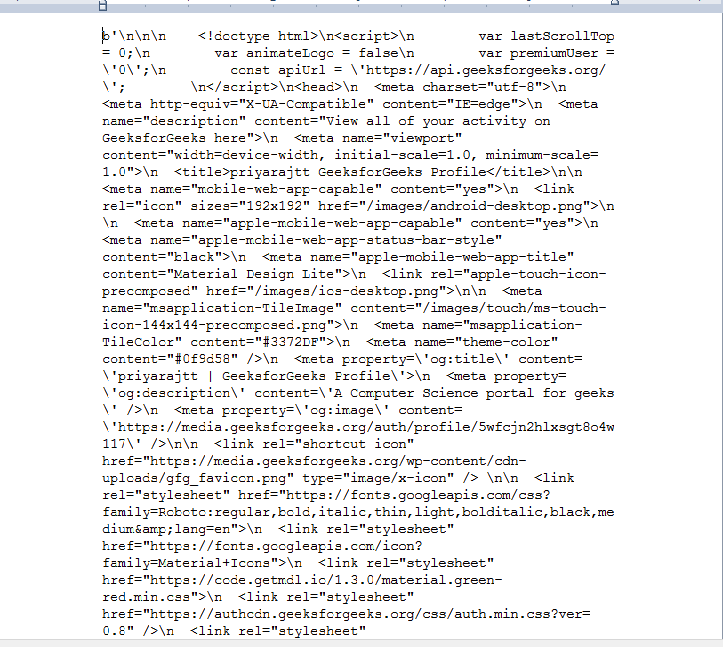
Now, use prettify() method to view tags and content in an easier way.
Python3
from bs4 import BeautifulSoup
HTMLFileToBeOpened = open("samplehtml.html", "r")
contents = HTMLFileToBeOpened.read()
beautifulSoupText = BeautifulSoup(contents, 'lxml')
print(beautifulSoupText.body.prettify())
|
Output :
In this way can get HTML data. Now do some operations and some insightful in the data.
Example 1:
We can use find() methods and as HTML contents dynamically change, we may not be knowing the exact tag name. In that time, we can use findAll(True) to get the tag name first, and then we can do any kind of manipulation. For example, get the tag name and length of the tag
Python3
from bs4 import BeautifulSoup
HTMLFileToBeOpened = open("samplehtml.html", "r")
contents = HTMLFileToBeOpened.read()
beautifulSoupText = BeautifulSoup(contents, 'lxml')
for tag in beautifulSoupText.findAll(True):
print(tag.name, " : ", len(beautifulSoupText.find(tag.name).text))
|
Output:
Example 2 :
Now, instead of scraping one HTML file, we want to do for all the HTML files present in that directory(there may be necessities for such cases as on daily basis, a particular directory may get filled with the online data and as a batch process, scraping has to be carried out).
We can use “os” module functionalities. Let us take the current directory all HTML files for our examples
So our task is to get all HTML files to get scrapped. In the below way, we can achieve. Entire folder HTML files got scraped one by one and their length of tags for all files are retrieved, and it is showcased in the attached video.
Python3
import os
from bs4 import BeautifulSoup
directory = os.getcwd()
for filename in os.listdir(directory):
if filename.endswith('.html'):
fname = os.path.join(directory, filename)
print("Current file name ..", os.path.abspath(fname))
with open(fname, 'r') as file:
beautifulSoupText = BeautifulSoup(file.read(), 'html.parser')
for tag in beautifulSoupText.findAll(True):
print(tag.name, " : ", len(beautifulSoupText.find(tag.name).text))
|
Output:
Share your thoughts in the comments
Please Login to comment...