In SQL, rows and columns are the fundamental building blocks of a database. Rows represent individual records, while columns represent the attributes or characteristics of those records. However, there may be instances where we need to convert rows to columns in order to better analyze and manipulate data. This process is known as “pivoting” and can be done efficiently using SQL. In this article, we will explore the concept of converting rows to columns in SQL and provide step-by-step instructions on how to do it.
Pivot in SQL
In SQL, the PIVOT operation is a powerful tool for transforming rows into columns. It’s particularly useful when you want to aggregate data and present it in a more structured format. The PIVOT operation involves specifying an aggregate function and creating new columns based on unique values from a specified column.
Main Concept:
The main concept behind converting rows to columns in SQL is to transpose the data. This means that we will be changing the orientation of the data from a vertical format (rows) to a horizontal format (columns). This can be achieved using the PIVOT function in SQL. The syntax for the PIVOT function is as follows:
Syntax:
SELECT
[non-pivoted column(s)],
[pivoted column1],
[pivoted column2],
...
FROM
[table_name]
PIVOT
(
aggregate_function(column_name)
FOR [pivot_column] IN ([value1], [value2], [value3], ...)
) AS [alias_name];
Explanation:
Let’s break down the syntax and understand each component:
- SELECT: This is used to specify the columns we want to retrieve from the table.
- [non-pivoted column(s)]: Columns that remain unchanged and appear in the final result.
- [pivot_column]: The column whose unique values will become new columns in the result.
- FROM: This specifies the table from which we want to retrieve data.
- PIVOT: This is the keyword that tells SQL we want to pivot the data.
- aggregate_function: This is used to perform an aggregate function on the data, such as SUM, COUNT, or AVG.
- aggregate_function(column_name): The aggregate function to be applied to the values in the pivoted column.
- column_name: This is the column on which we want to perform the aggregate function.
- pivot_column: This is the column that will become the new column headers.
- [value1], [value2], [value3], … : The unique values from the pivot column that will be transformed into new columns.
- [alias_name]: An alias for the resulting pivoted table.
Examples of Efficient Row to Column Conversion in SQL
Example 1: Pivoting Sales Data for Products by Month
Let’s say we have a table called “Sales” with the following data:
“We can create the ‘Sales‘ table using the following SQL code, which defines the table structure with columns such as ‘Product,’ ‘Month,’ and ‘Sales,’ specifying appropriate data types for each column to store information about sales’ marks in different subjects.”
CREATE TABLE Sales (
Product VARCHAR(50),
Month VARCHAR(3),
Sales INT
);
INSERT INTO Sales (Product, Month, Sales)
VALUES
('A', 'Jan', 100),
('A', 'Feb', 200),
('A', 'Mar', 300),
('B', 'Jan', 150),
('B', 'Feb', 250),
('B', 'Mar', 350);
Sales table:

Sales Table
We want to pivot this data to show the total sales for each product in each month. The query would look like this:
SELECT Product, Jan, Feb, Mar
FROM sales
PIVOT
(
SUM(Sales)
FOR Month IN (Jan, Feb, Mar)
) AS SalesByMonth;
Output:
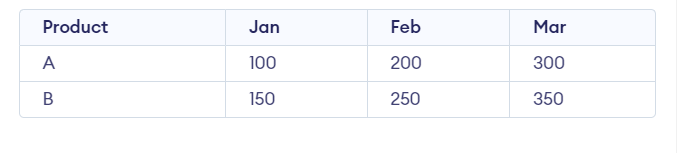
Sales data Output
Output:
The output of this SQL query presents a pivoted view of sales data for each product across different months. The columns represent months (Jan, Feb, Mar), and the corresponding values indicate the total sales for each product in the respective months. This transformation facilitates a clearer analysis of sales performance over time.
Example 2: Pivoting Student Marks by Subject
Let’s take another example where we have a table called “students” with the following data:
“We can create the ‘Students‘ table using the following SQL code, which defines the table structure with columns such as ‘Student,’ ‘Subject,’ and ‘Marks,’ specifying appropriate data types for each column to store information about students’ marks in different subjects.”
CREATE TABLE Students (
Student VARCHAR(50),
Subject VARCHAR(50),
Marks INT
);
INSERT INTO Students (Student, Subject, Marks)
VALUES
('John', 'Math', 90),
('John', 'Science', 80),
('John', 'English', 95),
('Jane', 'Math', 85),
('Jane', 'Science', 75),
('Jane', 'English', 90);

Students Table
We want to pivot this data to show the marks for each subject for each student. The query would look like this:
SELECT Student, Math, Science, English
FROM students
PIVOT
(
MAX(Marks)
FOR Subject IN (Math, Science, English)
) AS MarksBySubject;
Output:

Students data output
Explanation:
The output of this SQL query presents a pivoted view of student marks data, showcasing the scores for each subject (Math, Science, English) across different students. Each row represents a student, and the columns display the maximum marks achieved in the respective subjects. This pivot simplifies the analysis of individual student performance in different subjects.
Conclusion
In Conclusion, when working with databases in SQL, sometimes it’s helpful to change the way we look at our data. Pivoting is like turning data on its side, making it easier to understand and analyze. The PIVOT operation in SQL is a useful tool for doing this. In simple terms, it’s like taking information organized in rows (like a list) and turning it into columns (like a table). This is handy when we want to see totals or specific details in a more structured way.
Share your thoughts in the comments
Please Login to comment...