In this article, we will learn How to create a list of Files, Folders, and Sub Folders and then export them to Excel using Python. We will create a list of names and paths using a few folder traversing methods explained below and store them in an Excel sheet by either using openpyxl or pandas module.
Input: The following image represents the structure of the directory.
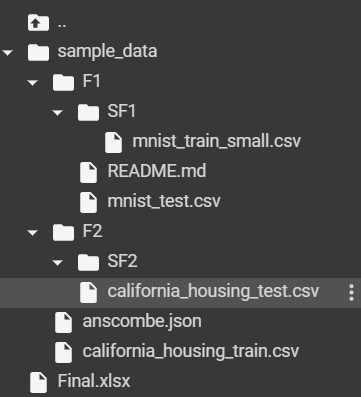
NOTE:SF2 is an empty directory
Traversing files, folder, and subfolders
The following Functions are methods for traversing folders and stores the name and path of files/folders in lists.
Method 1: Using append_path_name(path, name_list, path_list, glob)
An important function that is used in the following folder traversing functions. The purpose of the function is to check if the given path is of Windows or Linux os as the path separator is different and appends the names and paths of files or folders to name_list and path_list respectively.
Note: Windows uses “\” and Linux uses “/” as path separator, since python treats “\” as an invalid character, we need to use “\\” instead of “\” in the path.
Approach:
- The function will first find if the path contains “\\” using :
# Returns the count if it finds
# any "\\" in the given path.
path.find("\\")
Note: If it returns any number greater than zero, it means the current os is Windows and the first block of code will be executed or else the second block of code will be executed representing Linux os.
- We will split the path according to the current os and store it in a temporary list.
# Windows
temp = path.split("\\")
# Linux
temp = path.split("/")
- We will append the name and path of files or folders to the name_list and path_list respectively.
# temp[-1] gets the last value present in
# the temporary list that represents
# the file or folder name.
name_list.append(temp[-1])
path_list.append(path)
- If the glob variable is True, the parent path will be joined with a regex expression that is required for recursive traversing in glob.iglob() method.
# Windows
path = os.path.join(path, "**\\*")
# Linux
path = os.path.join(path, "**/*")
Example:
Python3
import os
def append_path_name(path, name_list, path_list, glob):
if path.find("\\") > 0:
temp = path.split("\\")
name_list.append(temp[-1])
path_list.append(path)
if glob == True:
path = os.path.join(path, "**\\*")
return path, name_list, path_list
else:
temp = path.split("/")
name_list.append(temp[-1])
path_list.append(path)
if glob == True:
path = os.path.join(path, "**/*")
return path, name_list, path_list
return name_list, path_list
name_list, path_list = append_path_name("/content/sample_data", [], [], False)
print(name_list)
print(path_list)
|
Output:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Method 2: Using find_using_os_walk(path, name_list, path_list)
This method generates the file names in a directory tree by walking the tree either top-down or bottom-up in the given path.
Syntax : os.walk(path)
Approach:
1. Initiate a for loop using os.walk(path) method, it generates a tuple containing the path of the current directory in root and the file list in files.
for root, _, files in os.walk(path):
2. Call the append_path_name function to store the names and paths of directories bypassing the current directory path.
name_list, path_list = append_path_name(
root, name_list, path_list, False)
3. Iterate the files and store the names and paths of the files found inside a folder.
# Joins the folder path and the
# file name to generate file path
file_path = os.path.join(root, file_name)
# Appends file name and file path to
# name_list and path_list respectively.
name_list.append(file_name)
path_list.append(file_path)
Example:
Python3
import os
def find_using_os_walk(path, name_list, path_list):
for root, _, files in os.walk(path):
name_list, path_list = append_path_name(
root, name_list, path_list, False)
for file_name in files:
file_path = os.path.join(root, file_name)
name_list.append(file_name)
path_list.append(file_path)
return name_list, path_list
name_list, path_list = find_using_os_walk("/content/sample_data", [], [])
print(name_list)
print(path_list)
|
Output:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Method 3: Using find_using_scandir(path, name_list, path_list)
This Function returns an iterator of os.DirEntry objects corresponding to the entries in the directory given by path.
Syntax : os.scandir(path)
Approach:
1. Call the append_path_name function to store the names and paths of directories by passing the current directory path.
name_list, path_list = append_path_name(
path, name_list, path_list, False)
2. Initiate a for loop using os.scandir(path) method that returns an object containing the current name and path of the file/folder.
for curr_path_obj in os.scandir(path):
3. If the current path is a directory then the function calls itself to recursively traverse the folders and store the folder names and paths from step 1.
if curr_path_obj.is_dir() == True:
file_path = curr_path_obj.path
find_using_scandir(file_path, name_list, path_list)
4. Else the file names and paths are stored in name_list and path_list respectively.
file_name = curr_path_obj.name
file_path = curr_path_obj.path
name_list.append(file_name)
path_list.append(file_path)
Example:
Python3
import os
def find_using_scandir(path, name_list, path_list):
name_list, path_list = append_path_name(
path, name_list, path_list, False)
for curr_path_obj in os.scandir(path):
if curr_path_obj.is_dir() == True:
file_path = curr_path_obj.path
find_using_scandir(file_path, name_list, path_list)
else:
file_name = curr_path_obj.name
file_path = curr_path_obj.path
name_list.append(file_name)
path_list.append(file_path)
return name_list, path_list
name_list, path_list = find_using_scandir("/content/sample_data", [], [])
print(name_list)
print(path_list)
|
Output:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Method 4: Using find_using_listdir(path, name_list, path_list)
This Function Gets the list of all files and directories in the given path.
Syntax : os.listdir(path)
Approach:
1. Call the append_path_name function to store the names and paths of directories by passing the current directory path.
name_list, path_list = append_path_name(
path, name_list, path_list, False)
2. Initiate a for loop using os.listdir(path) method that returns a list of files and folder names present in the current path.
for curr_name in os.listdir(path):
3. Join the name of folder or file with the current path.
curr_path = os.path.join(path, curr_name)
4. If the current path is a directory then the function calls itself to recursively traverse the folders and store the folder names and paths from step 1.
if os.path.isdir(curr_path) == True:
find_using_listdir(curr_path, name_list, path_list)
5. Else the file names and paths are stored in name_list and path_list respectively.
name_list.append(curr_name)
path_list.append(curr_path)
Code for the above-mentioned function:
Python3
import os
def find_using_listdir(path, name_list, path_list):
name_list, path_list = append_path_name(path,
name_list, path_list, False)
for curr_name in os.listdir(path):
curr_path = os.path.join(path, curr_name)
if os.path.isdir(curr_path) == True:
find_using_listdir(curr_path, name_list, path_list)
else:
name_list.append(curr_name)
path_list.append(curr_path)
return name_list, path_list
name_list, path_list = find_using_listdir("/content/sample_data", [], [])
print(name_list)
print(path_list)
|
Output:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Method 5: Using find_using_glob(path, name_list, path_list)
This Function returns an iterator that yields the same values as glob() without actually storing them all simultaneously.
Syntax : glob.iglob(path, recursive=True)
Approach:
1. Call the append_path_name function to store the name and path of parent directory and also return the modified path required for glob method since the last parameter is True.
path, name_list, path_list = append_path_name(
path, name_list, path_list, True)
2. Initiate a for loop using glob.iglob(path, recursive=True) method that recursively traverses the folders and returns the current path of file/folder.
for curr_path in glob.iglob(path, recursive=True):
3. Call the append_path_name function to store the names and paths of files/folders by passing the current path.
name_list, path_list = append_path_name(
curr_path, name_list, path_list, False)
Code for the above-mentioned function:
Python3
import glob
def find_using_glob(path, name_list, path_list):
path, name_list, path_list = append_path_name(
path, name_list, path_list, True)
for curr_path in glob.iglob(path, recursive=True):
name_list, path_list = append_path_name(
curr_path, name_list, path_list, False)
return name_list, path_list
name_list, path_list = find_using_glob("/content/sample_data", [], [])
print(name_list)
print(path_list)
|
Output:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Storing data in Excel Sheet
Method 1: Using openpyxl
This module is used to read/write data to excel. It has a wide range of features but here we will use it to just create and write data to excel. You need to install openpyxl via pip in your system.
pip install openpyxl
Approach:
1. Import the required modules
# imports workbook from openpyxl module
from openpyxl import Workbook
2. Create a workbook object
work_book = Workbook()
3. Get the workbook active sheet object and initiate the following variables with 0.
row, col1_width, col2_width = 0, 0, 0
work_sheet = work_book.active
4. Iterate the rows to the maximum length of name_list as these many entries will be written to the excel sheet
while row <= len(name_list):
5. Get the cell objects of column 1 and column 2 of the same row and store the values of name_list and path_list to the respective cells.
name = work_sheet.cell(row=row+1, column=1)
path = work_sheet.cell(row=row+1, column=2)
# This block will execute only once and
# add the Heading of column 1 and column 2
if row == 0:
name.value = "Name"
path.value = "Path"
row += 1
continue
# Storing the values from name_list and path_list
# to the specified cell objects
name.value = name_list[row-1]
path.value = path_list[row-1]
6. (Optional) Adjusting the width of cells in Excel sheet using openpyxl’s column dimensions.
col1_width = max(col1_width, len(name_list[row-1]))
col2_width = max(col2_width, len(path_list[row-1]))
work_sheet.column_dimensions["A"].width = col1_width
work_sheet.column_dimensions["B"].width = col2_width
7. Save the workbook with a file name after the iteration is over with a filename.
work_book.save(filename="Final.xlsx")
Example:
Python3
def create_excel_using_openpyxl(name_list, path_list,
path):
work_book = Workbook()
work_sheet = work_book.active
row, col1_width, col2_width = 0, 0, 0
while row <= len(name_list):
name = work_sheet.cell(row=row+1, column=1)
path = work_sheet.cell(row=row+1, column=2)
if row == 0:
name.value = "Name"
path.value = "Path"
row += 1
continue
name.value = name_list[row-1]
path.value = path_list[row-1]
col1_width = max(col1_width, len(name_list[row-1]))
col2_width = max(col2_width, len(path_list[row-1]))
work_sheet.column_dimensions["A"].width = col1_width
work_sheet.column_dimensions["B"].width = col2_width
row += 1
work_book.save(filename="Final.xlsx")
create_excel_using_openpyxl(name_list, path_list, path)
|
Output:
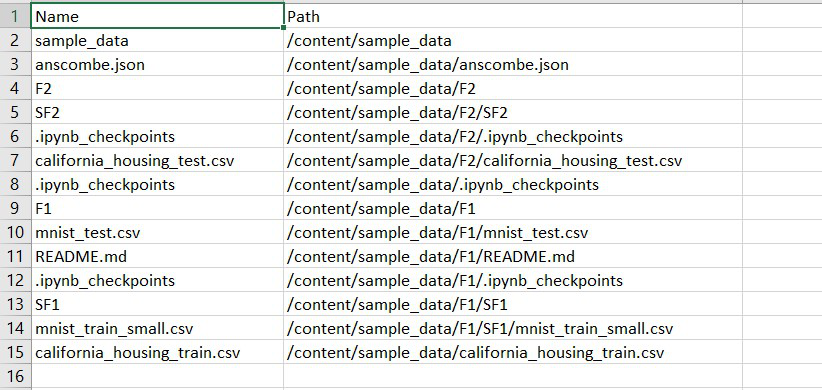
Method 2: Using pandas
1. Create a frame (a dictionary) with the keys as ‘Name’ and ‘Path’ and values as name_list and path_list respectively:
frame = {'Name': name_list,
'Path': path_list
}
2. Before exporting we need to create a dataframe called df_data with columns as Name and Path.
df_data = pd.DataFrame(frame)
3. Export the data to excel using the following code:
df_data.to_excel('Final.xlsx', index=False)
Code for the above-mentioned function:
Python3
def create_excel_using_pandas_dataframe(name_list,
path_list, path):
frame = {'Name': name_list,
'Path': path_list
}
df_data = pd.DataFrame(frame)
df_data.to_excel('Final.xlsx', index=False)
create_excel_using_pandas_dataframe(name_list,
path_list, path)
|
Output:
Share your thoughts in the comments
Please Login to comment...