Boosting algorithms are one of the best-performing algorithms among all the other Machine Learning algorithms with the best performance and higher accuracies. All the boosting algorithms work on the basis of learning from the errors of the previous model trained and tried avoiding the same mistakes made by the previously trained weak learning algorithm.
It is also a big interview question that might be asked in data science interviews. In this article, we will be discussing the main difference between GradientBoosting, AdaBoost, XGBoost, CatBoost, and LightGBM algorithms, with their working mechanisms and their mathematics of them.
Gradient Boosting
Gradient Boosting is the boosting algorithm that works on the principle of the stagewise addition method, where multiple weak learning algorithms are trained and a strong learner algorithm is used as a final model from the addition of multiple weak learning algorithms trained on the same dataset.
In the gradient boosting algorithm, the first weak learner will not be trained on the dataset, it will simply return the mean of the particular column, and the residual for output of the first weak learner algorithm will be calculated which will be used as output or target column for next weak learning algorithm which is to be trained.
Following the same pattern, the second weak learner will be trained and the residuals will be calculated which will be used as an output column again for the next weak learner, this is how this process will continue until we reach zero residuals.
In gradient boosting the dataset should be in the form of numerical or categorical data and the loss function using which the residuals are calculated should be differential at all points.
Python3
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
X, y = make_regression(n_samples=100,
n_features=10,
n_informative=5,
n_targets=1,
random_state=42)
X_train, X_test,\
y_train, y_test = train_test_split(X, y,
test_size=0.2)
gbr = GradientBoostingRegressor()
gbr.fit(X_train, y_train)
y_pred1 = gbr.predict(X_test)
print("Gradient Boosting - R2: ",
r2_score(y_test, y_pred1))
|
Output:
Gradient Boosting - R2: 0.8387570820958865
XGBoost
XGBoost is also a boosting machine learning algorithm, which is the next version on top of the gradient boosting algorithm. The full name of the XGBoost algorithm is the eXtreme Gradient Boosting algorithm, as the name suggests it is an extreme version of the previous gradient boosting algorithm.
The main difference between GradientBoosting is XGBoost is that XGbost uses a regularization technique in it. In simple words, it is a regularized form of the existing gradient-boosting algorithm.
Due to this, XGBoost performs better than a normal gradient boosting algorithm and that is why it is much faster than that also. It also performs better when there is a presence of numerical and categorical features in the dataset.
Python3
from xgboost import XGBRegressor
xgr = XGBRegressor()
xgr.fit(X_train, y_train)
y_pred2 = xgr.predict(X_test)
print("XGBoost - R2: ",
r2_score(y_test, y_pred2))
|
Output:
XGBoost - R2: 0.8730807521630943
AdaBoost
AdaBoost is a boosting algorithm, which also works on the principle of the stagewise addition method where multiple weak learners are used for getting strong learners. Unlike Gradient Boosting in XGBoost, the alpha parameter I calculated is related to the errors of the weak learner, here the value of the alpha parameter will be indirectly proportional to the error of the weak learner.
Once the alpha parameter is calculated, the weightage will be given to the particular weak learners, here the weak learner that are doing mistakes will get more weightage to fill out the gap in error and the weak learners that are already performing well will get fewer weights as they are already a good model.
Python3
from sklearn.ensemble import AdaBoostRegressor
adr = AdaBoostRegressor()
adr.fit(X_train, y_train)
y_pred3 = adr.predict(X_test)
print("AdaBoost - R2: ",
r2_score(y_test, y_pred3))
|
Output:
AdaBoost - R2: 0.796880734337689
CatBoost
In CatBoost the main difference that makes it different and better than others is the growing of decision trees in it. In CatBoost the decision trees which is grown are symmetric. One can easily install this library by using the below command:
pip install catboost
CatBoost is a boosting algorithm that performs exceptionally very well on categorical datasets other than any algorithm in the field of machine learning as there is a special type of method for handling categorical datasets. In CatBoost, the categorical features are encoded on the basis of the output columns. So while training or encoding the categorical features, the weightage of the output column will also be considered which makes it higher accurate on categorical datasets.
Python3
from catboost import CatBoostRegressor
cbr = CatBoostRegressor(iterations=100,
depth=5,
learning_rate=0.01,
loss_function='RMSE',
verbose=0)
cbr.fit(X_train, y_train)
y_pred4 = cbr.predict(X_test)
print("CatBoost - R2: ",
r2_score(y_test, y_pred4))
|
Output:
CatBoost - R2: 0.3405843849282183
LightGBM
LightGBM is also a boosting algorithm, which means Light Gradient Boosting Machine. It is used in the field of machine learning. In LightGBM decision trees are grown leaf wise meaning that at a single time only one leaf from the whole tree will be grown. One can install the required library by using the below command:
pip install lightgbm
LightGBM also works well on categorical datasets and it also handles the categorical features using the binning or bucketing method. To work with categorical features in LightGBM we have converted all the categorical features in the category datatype. Once done, there will be no need to handle categorical data as it will handle it automatically.
In LightGBM, the sampling of the data while training the decision tree is done by the method known as GOSS. In this method, the variance of all the data samples is calculated and sorted in descending order. Data samples having low variance are already performing well, so there will be less weightage given to the samples having low variance while sampling the dataset.
Python3
import lightgbm as lgb
from lightgbm import LGBMRegressor
lgr = LGBMRegressor()
lgr.fit(X_train, y_train)
y_pred5 = lgr.predict(X_test)
print("LightGBM - R2: ",
r2_score(y_test, y_pred5))
|
Output:
LightGBM - R2: 0.8162904225442574
Difference Between Boosting Algorithms
| Algorithms |
Gradient Boosting |
AdaBoost |
XGBoost |
CatBoost |
LightGBM |
| Year |
– |
1995 |
2014 |
2017 |
2017 |
| Handling Categorical Variables |
May require preprocessing like one-hot encoding |
No |
NO |
Automatically handles categorical variables |
No |
| Speed/Scalability |
Moderate |
Fast |
Fast |
Moderate |
Fast |
| Memory Usage |
Moderate |
Low |
Moderate |
High |
Low |
| Regularization |
NO |
No |
Yes |
Yes |
Yes |
| Parallel Processing |
No |
No |
Yes |
Yes |
Yes |
| GPU Support |
No |
No |
Yes |
Yes |
Yes |
| Feature Importance |
Available |
Available |
Available |
Available |
Available |
Which Boosting Algorithm to Use?
Now it is a very basic question, if all of these machine learning algorithms are the best performing, fast, and gives higher accuracies, then which to use?
Well, the answer to these questions can not be a single boosting algorithm among them as all of them are the best-fit solution for a particular type of problem on which we are working.
For example, If you think that there is a need for regularization according to your dataset, then you can definitely use XGBoost, If you want to deal with categorical data, then CatBoost and LightGBM perform very well on those types of datasets. If you need more community support for the algorithm then use algorithms which was developed years back XGBoost or Gradient Boosting.
Comparison Between Different Boosting Algorithms
After fitting the data to the model, all of the algorithms return almost similar kind of results. Here LightGBM seems to perform poorly compared to other algorithms and XGBoost performs well in this case.
To visualize the performance of all the algorithms on the same data, we can also plot the graph between the y_test and y_pred of all the algorithms.
Python3
import matplotlib.pyplot as plt
import seaborn as sns
fig, ax = plt.subplots(figsize=(11, 5))
ax = sns.lineplot(x=y_test, y=y_pred1,
label='GradientBoosting')
ax1 = sns.lineplot(x=y_test, y=y_pred2,
label='XGBoost')
ax2 = sns.lineplot(x=y_test, y=y_pred3,
label='AdaBoost')
ax3 = sns.lineplot(x=y_test, y=y_pred4,
label='CatBoost')
ax4 = sns.lineplot(x=y_test, y=y_pred5,
label='LightGBM')
ax.set_xlabel('y_test', color='g')
ax.set_ylabel('y_pred', color='g')
|
Output:
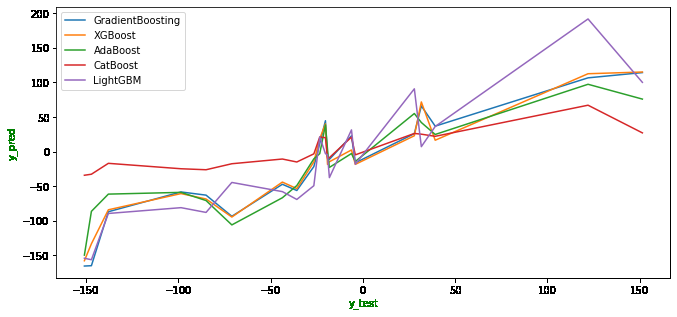
Graph of y_pred v/s y_test
We can see in the above chart, that represents the y_test and y_pred values predicted by every algorithm. Here we can see that LightGBM and CatBoost tend to perform poorly compared to other algorithms as they are predicting the values of y_pred very higher or lower than other algorithms. XGBoost and GradientBoosting perform well on this data, which we can clearly see from the image as their predictions seem like averaging of all the other algorithms from the graph.
Conclusion
In this article, the basic and mathematical difference between gradient boosting, XGBoost, AdaBoost, LightGBM, and CatBoost is discussed with their working mechanisms. Knowledge of these differences and core intuitions will help one to understand the difference between them better and help one to answer these types of questions very efficiently.
Share your thoughts in the comments
Please Login to comment...