Geohashing and Quadtrees for Location Based Services
Last Updated :
05 Apr, 2024
In location-based services (LBS), efficiency and accuracy are very important. Geohashing and Quadtrees stand out as key tools for achieving these goals. Geohashing provides a unique way to encode geographic coordinates, while Quadtrees offers a hierarchical structure for spatial data organization. In this article, we’ll see how these techniques work and how they are applied in location-based services.

Important Topics for Geohashing and Quadtrees for Location Based Services
What are Location-Based Services (LBS)?
Location-based services (LBS) are services and applications that utilize the geographical location of a mobile device or user to provide personalized and context-aware information, entertainment, or functionality. LBS leverages technologies such as GPS, Wi-Fi, cellular networks, and IP addresses to determine the location of the device or user.
Key components and concepts of Location-based Services include:
- Geolocation: The process of determining the geographical location of a device or user. This can be done using GPS, cell tower triangulation, Wi-Fi positioning, or IP geolocation.
- Personalization: LBS uses location information to tailor content, recommendations, and advertisements based on the user’s current or past locations.
- Proximity-based Services: LBS can deliver notifications, promotions, or information based on the user’s proximity to certain locations, such as nearby restaurants, stores, or attractions.
- Navigation and Mapping: Location-based navigation and mapping services provide turn-by-turn directions, real-time traffic information, and points of interest based on the user’s current location.
- Privacy and Security: LBS raises concerns about privacy and security due to the collection and processing of location data. Regulations and technologies such as geofencing and anonymization are used to protect user privacy.
What is Geohashing?
Geohashing is a method used to encode geographic coordinates (latitude and longitude) into a short string of characters, which allows for easy sharing, storage, and retrieval of location-based data. It was first proposed by computer scientist and blogger, Randall Munroe, in 2008. The method divides the world into a grid of equally-sized cells, each identified by a unique hash string. Geohashes are designed such that nearby geographic locations will have similar hash strings, allowing for efficient searches of nearby points.
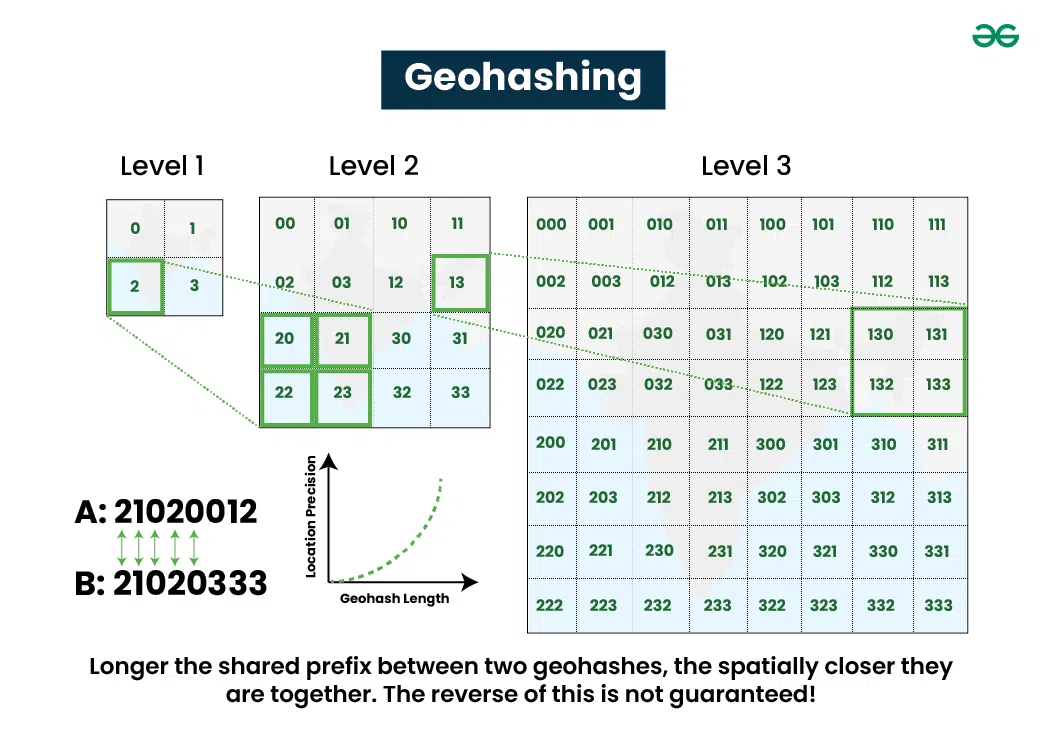
Key components and concepts of Geohashing include:
- Geohash String: This is the encoded string representing a geographic location. It’s generated by interleaving bits from the latitude and longitude of the location and converting them into a base-32 encoding, typically using letters and numbers.
- Precision: Geohashes of different lengths represent different levels of precision. Longer hashes provide more precision but are longer in length.
- Neighboring Cells: Adjacent geohash cells share a common prefix in their hash strings. This property allows for efficient range queries and proximity searches.
- Applications: Geohashing is used in various applications, such as geocaching, location-based games, spatial indexing in databases, and location-based services.
Benefits of Geohashing
- Efficient Spatial Indexing: Both Geohashing and Quadtrees offer hierarchical indexing systems for organizing geographic data efficiently.
- Adaptive Precision: Quadtrees provide variable precision based on data density, while Geohashing offers fixed precision, enabling efficient representation of spatial data at different levels of detail.
- Efficient Queries: Geohashing facilitates quick proximity searches, while Quadtrees excel in range queries and spatial subdivision, allowing for efficient spatial queries within specific geographic areas.
- Dynamic Adaptation: Quadtrees can adapt to changing data distributions over time, complementing Geohashing’s fixed-size representation of geographic coordinates.
- Compact Representation and Space Partitioning: Geohashing offers compact representation of coordinates, reducing storage and bandwidth needs, while Quadtrees partition space efficiently, aiding in managing complex spatial data distributions.
Challenges of Geohashing
- Fixed Precision: Geohashing offers fixed precision based on the length of the hash string. While this provides simplicity, it may not always be suitable for applications requiring variable levels of precision.
- Spatial Distribution: Geohashing may face challenges with spatial distribution, especially in areas with varying data densities. This can lead to uneven distribution of hash codes, affecting query performance.
- Overhead in Search Operations: Geohashing may require additional computational overhead in search operations, especially for large-scale spatial datasets or complex proximity queries.
What are Quadtrees?
A quadtree is a tree data structure used to represent and manage spatial data in two dimensions. It recursively subdivides a space into quadrants until each quadrant contains a manageable number of points or reaches a specified level of detail. Quadtree structures are widely used in computer graphics, geographic information systems (GIS), image processing, and spatial indexing.

Key concepts of Quadtrees include:
- Node Structure: Each node in a quadtree represents a rectangular region of space. It can either be a leaf node, representing a small area with actual data points, or an internal node, representing a larger area that is further subdivided into quadrants.
- Subdivision: When a quadrant contains too many points or exceeds a specified threshold, it’s subdivided into four smaller quadrants. This process continues recursively until each quadrant meets the desired criteria.
- Spatial Queries: Quadtree structures efficiently support spatial queries, such as range searches, nearest neighbor searches, and point containment checks.
- Applications: Quadtree structures are used in various applications, including collision detection in computer graphics, spatial indexing in GIS databases, image compression, and mesh generation.
Benefits of Quadtrees
- Adaptive Precision: Quadtrees offer adaptive precision, allowing for variable levels of detail based on the density and distribution of spatial data. This makes them suitable for efficiently representing and querying spatial information at different scales.
- Efficient Spatial Subdivision: Quadtrees efficiently partition space into quadrants recursively, facilitating spatial indexing and range queries in dynamic environments.
- Space Optimization: Quadtrees optimize space utilization by dynamically adjusting the tree structure based on data distribution, reducing storage overhead in sparse regions.
- Dynamic Adaptation: Quadtrees dynamically adapt to changes in spatial data distribution, maintaining efficient spatial indexing and query performance in evolving environments.
Challenges of Quadtrees
- Complexity: Quadtrees can introduce complexity in implementation and maintenance due to the recursive nature of the data structure and the need for efficient tree traversal algorithms.
- Balancing Efficiency and Precision: Achieving a balance between efficiency and precision in spatial subdivision can be challenging, especially in scenarios with highly variable data densities.
- Memory Overhead: Quadtrees may incur memory overhead, particularly in scenarios with large-scale spatial datasets or deep tree structures, impacting performance and scalability.
Comparison between Geohashing and Quadtrees
Geohashing and Quadtrees are spatial indexing techniques used to represent geographic data, they have different characteristics and strengths. Geohashing provides fixed precision and efficient proximity searches, whereas Quadtrees offer adaptive precision and are well-suited for range queries and spatial subdivision.
- Data Structure:
- Geohashing: Geohashing is based on encoding geographic coordinates into a single string using a hierarchical grid system. It divides the Earth’s surface into a grid of rectangles, each identified by a unique string hash.
- Quadtrees: Quadtrees are a tree data structure used to represent and partition two-dimensional space recursively. Each node in the tree represents a square region of space, which is further divided into four quadrants.
- Precision:
- Geohashing: Geohashing provides a fixed level of precision based on the length of the hash string. Longer hashes offer higher precision but result in longer strings.
- Quadtrees: Quadtrees can adapt to the density and distribution of data, providing variable precision. They can be recursively subdivided to achieve finer levels of detail in areas with high data density.
- Spatial Queries:
- Geohashing: Geohashing is well-suited for proximity searches and spatial indexing, where it efficiently identifies nearby locations based on hash similarity.
- Quadtrees: Quadtrees excel in range queries and spatial subdivision. They can efficiently identify points within a specified region by traversing the tree structure.
- Scalability:
- Geohashing: Geohashing can scale well for indexing large datasets, as it provides a fixed-size representation of geographic coordinates.
- Quadtrees: Quadtrees can adapt to varying data densities and spatial distributions, making them suitable for dynamic datasets and scenarios where spatial data is non-uniformly distributed.
- Complexity:
- Geohashing: Geohashing typically involves simpler algorithms for encoding and decoding geographic coordinates into hash strings.
- Quadtrees: Quadtrees can involve more complex algorithms for tree construction, insertion, and traversal, particularly as the tree grows and adapts to changes in data density.
Integration of Geohashing and Quadtrees in Location-Based Services:
In Location-Based Services, Geohashing and Quadtrees can complement each other: Geohashing can be used for quick location encoding and decoding, facilitating efficient storage and retrieval of location-based information. Quadtrees can aid in spatial indexing and querying, enabling fast and scalable spatial analysis and search operations.
The integration of Geohashing and Quadtrees in location-based services (LBS) can provide a powerful framework for efficiently indexing and querying geographic data. Here’s how they can be integrated:
- Hierarchical Indexing:
- Geohashing provides a hierarchical grid-based indexing system where geographic coordinates are encoded into hash strings representing rectangular grid cells.
- Quadtrees also offer a hierarchical structure, dividing the geographic space into quadrants recursively.
- Initial Geohashing:
- Geographic coordinates can be initially encoded into Geohash strings to represent locations.
- Each Geohash string corresponds to a particular rectangular grid cell in the Geohash grid.
- Quadtrees for Spatial Subdivision:
- Quadtrees can be used to further partition areas with high data density or spatial complexity.
- As data density increases in specific regions, Quadtrees can recursively divide those regions into smaller quadrants, accommodating finer levels of spatial detail.
- Combining Geohash and Quadtree Indexing:
- At the highest level, Geohashes can be used to quickly identify coarse regions of interest.
- Within each coarse region identified by Geohashing, Quadtrees can be employed to provide more precise spatial indexing.
- This combined approach leverages the efficiency of Geohashing for initial spatial indexing while using Quadtrees to adaptively refine the spatial representation as needed.
- Spatial Queries and Optimization:
- Spatial queries in location-based services, such as proximity searches or range queries, can benefit from the integration of Geohashing and Quadtrees.
- Geohashing facilitates quick identification of coarse regions of interest, narrowing down the search space.
- Quadtrees enable precise spatial queries within those regions, accommodating varying data densities and providing finer-grained results.
- Dynamic Adaptation:
- The integration of Geohashing and Quadtrees allows for dynamic adaptation to changes in data distribution and density over time.
- As new data points are added or removed, the Quadtrees can adjust their structure to maintain efficient spatial indexing and query performance.
Use Cases and Real-World Examples
- Navigation Apps: Services like Google Maps use LBS to provide real-time navigation, traffic updates, and location-based recommendations.
- Location-Based Advertising: Retailers use LBS to deliver targeted advertisements and promotions to users based on their current location.
- Emergency Response: LBS assist emergency services in locating and responding to incidents more efficiently, improving public safety.
What is Hilbert Curve?
The Hilbert curve is a space-filling curve that traverses a two-dimensional grid in a manner that preserves locality. It was introduced by the German mathematician David Hilbert in 1891 as a way to create a continuous path that covers every point in a square grid with minimal movement. The Hilbert curve has applications in computer graphics, spatial indexing, data compression, and image processing.

Some of Key properties of the Hilbert Curve include:
- Space-filling: The Hilbert curve fills the entire area of a square grid without intersecting itself. It visits every point in the grid exactly once, creating a continuous path.
- Locality Preservation: Nearby points in the grid are visited sequentially along the curve, preserving spatial locality. This property is useful for spatial indexing and data clustering applications.
- Ordering: The Hilbert curve imposes a natural ordering on the points in the grid. Points that are close to each other in the curve are also close to each other in the grid.
Applications of Hilbert Curve
Some of the applications of Hilbert Curve include:
- Spatial indexing: Efficient organization and retrieval of geographical data, such as points of interest or landmarks.
- Nearest neighbor search: Quick identification of nearby locations based on the user’s current location.
- Route optimization and navigation: Efficient route planning algorithms for navigation applications.
- Geofencing: Swift determination of whether a location falls within predefined virtual boundaries.
- Location-based advertising and marketing: Targeted delivery of advertisements or promotions based on user proximity to specific locations.
Hilbert Curve or Quadtrees for Spatial Indexing: Which is better?
While both Hilbert curves and Quadtrees are used for spatial indexing, Hilbert curves offer certain advantages over Quadtrees in specific scenarios:
- Space-filling Nature: Hilbert curves are space-filling curves, meaning they traverse the entire space without intersecting themselves. This property ensures that nearby points in the curve correspond to nearby locations in the spatial domain. In contrast, Quadtrees partition space into quadrants recursively, potentially leading to fragmentation and inefficiencies in representing spatial data, especially in regions with varying data densities.
- Efficient Range Queries: Hilbert curves facilitate efficient range queries due to their space-filling nature. Queries along the curve can exploit spatial locality, leading to efficient retrieval of spatial data within specified ranges. Quadtrees, while efficient for some range queries, may suffer from performance degradation with increasing tree depth or imbalanced data distributions.
- Compact Representation: Hilbert curves provide a compact representation of spatial data. The curve itself can serve as an index, requiring less storage space compared to the hierarchical structure of Quadtrees. This compactness can be advantageous, especially in scenarios with limited storage resources or when transmitting spatial data over networks.
- Ease of Implementation: Implementing algorithms for constructing and traversing Hilbert curves may be simpler compared to managing Quadtrees, especially for large-scale spatial datasets. The recursive nature of Quadtrees introduces complexity in insertion, deletion, and traversal operations, whereas Hilbert curves have well-defined algorithms for construction and navigation.
- Adaptability: While Quadtrees offer adaptive precision by recursively subdividing space, Hilbert curves provide a fixed-level precision based on the curve’s order. However, in certain applications where adaptive precision is not a requirement or where space partitioning is not critical, the fixed-level precision of Hilbert curves may suffice.
Share your thoughts in the comments
Please Login to comment...