Prerequisite – File Organisation
Data is not static as it is constantly changing and these changes need to be reflected in their files. The function that keeps files current is known as updating.
Update Files:
Three specific files are associated while updating a file.
- The permanent data file, called the master file contains the most current file data.
- The transaction file contains changes to be applied to the master file.
- The third file needed in an update program is an error report file. The error report contains a listing of all errors discovered during the update process and is presented to the user for corrective action.
Three basic types of changes occur in all file updates: Adding new data, deleting old data, modify data containing revisions.
To process any of these transactions, we need a key. A key is one or more fields that uniquely identify the data in the file. For example, in a student file, the key would be student ID. In an employee file, the key would be Social Security number.
File updates are of 2 types:
- In a batch update, changes are collected over time and then all changes are applied to the file at once.
- In an online update, the user is directly connected to the computer and the changes are processed one at a time-often as the change occurs.
Sequential File Update:
Assuming a batch, sequential file environment. It is a file that must be processed serially starting at the beginning without any random processing capabilities. A sequential file update actually has two copies of the master file, the old master and the new master.
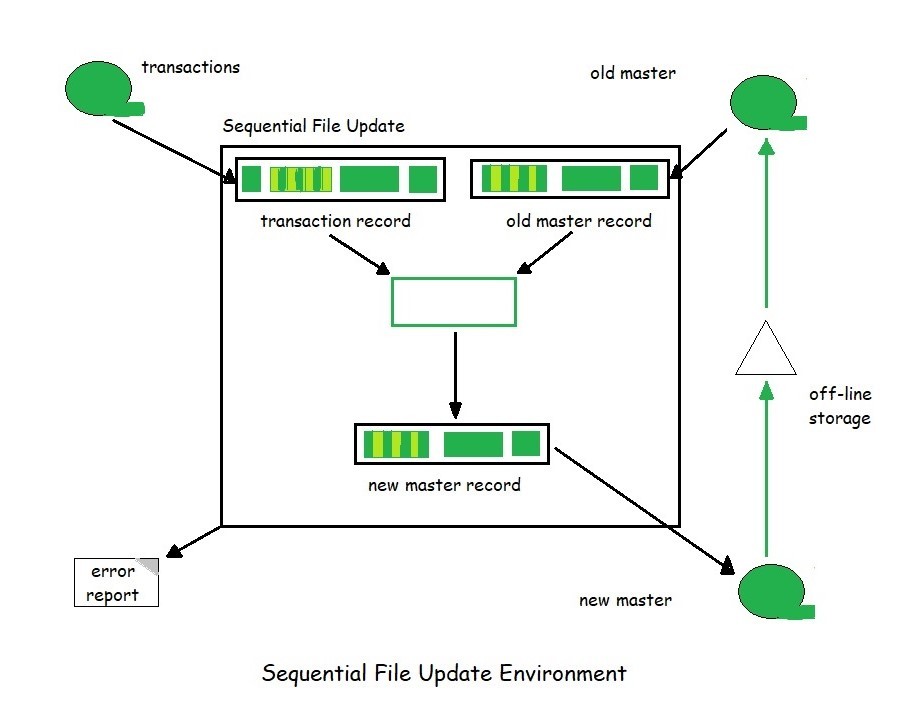
In the above figure, we see the four files we discussed above. Tape symbol for the files because it is the classic symbol for sequential files. After the update program completes, the new master file is sent to off-line storage, where it is kept until it is needed again. When the file is to be updated, the master file is retrieved from the off-line storage and used as the old master.
Generally, at least three copies of a master file are retained in off-line storage, in case it becomes necessary to regenerate an unreadable file. This retention cycle is known as the grandparent system because three generations of the file are always available: the grandparent, the parent and the child.
The Update Program Design:
The update process requires that we match the keys on the transaction and master file and, assuming that there are no errors, one of the following three actions/rules are followed:
- If the transaction file key is less than the master file key, the transaction is added to the new master.
- If the transaction file key is equal to the master file key, either
- (a). The contents of the master file are changed if the transaction is a revise transaction, or
- (b). The data is removed from the master file if the transaction is a delete.
- If the transaction file key is greater than the master file key, the old master file record is written to the new master file.
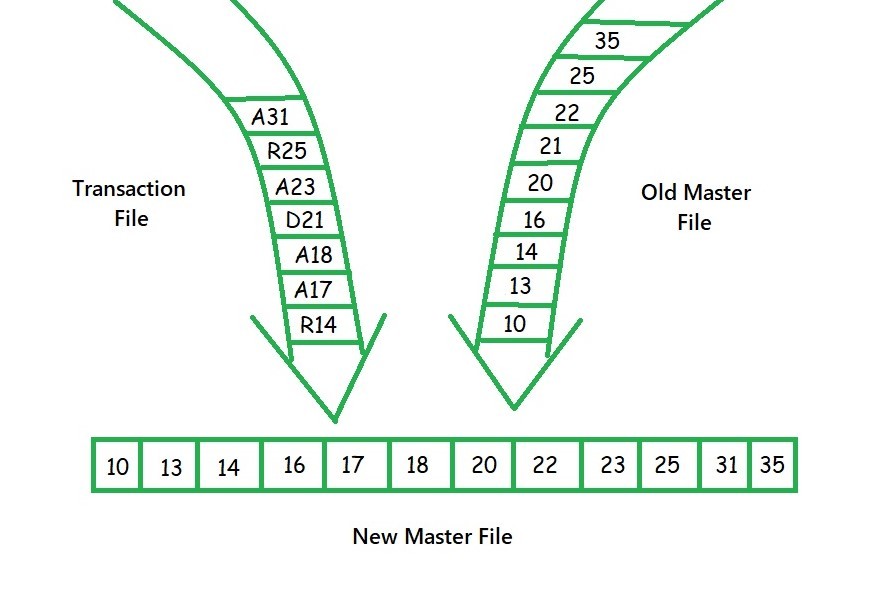
This updating process is shown in Figure above. In the transaction file, the transaction codes are A for add, D for delete, and R for revise. The process begins by matching the keys for the first record on each file, in this case,
14 > 10
Thus, Rule 3 is used, and the master record is written to the new master record. Then 14 and 13 are matched, which results in 13 being written to the new master. In the next match, we have
14 == 14
Thus, according to Rule 2a, the data is used in the transaction file to change the data in the master file. However, the new master file is not written at this time. More transactions may match the master file, and they too need to be processed. After writing 16 to the new master, the situation is
17 < 20
According to Rule 1, 17 must be added to the new master file. To do transactions are copied to the new master file, but not written yet.
The processing continues until the delete transaction is read, at which the following situation occurs
21 == 21
and since the transaction is a delete, according to Rule 2b, 21 is dropped from the new master file. To do this, the next master record and transaction record is read without writing the new master. The processing continues in a similar fashion until all records on both files have been processed.
Update Errors:
Two general classes of errors can occur in an update program. The first being bad data implying that attributes which are not a part of the data. The second class of errors is file errors. File errors occur when the data on the transaction file are not in synchronization with the data on the master file.
3 different situations can occur:
- An add transaction matches a record with the same key on the master file. Master files do not allow duplicate data to be present. When the key on an add transaction matches a key on the master file, therefore, the transaction is rejected as invalid and it is reported on the error report.
- A revise transaction’s key does not match a record on the master file. In this case, user is trying to change data that do not exist. This is also a file error and must be reported on the error report.
- A delete transaction’s key does not match a record on the master file. In this case, user is trying to delete data that do not exist, and this must also be reported as an error.
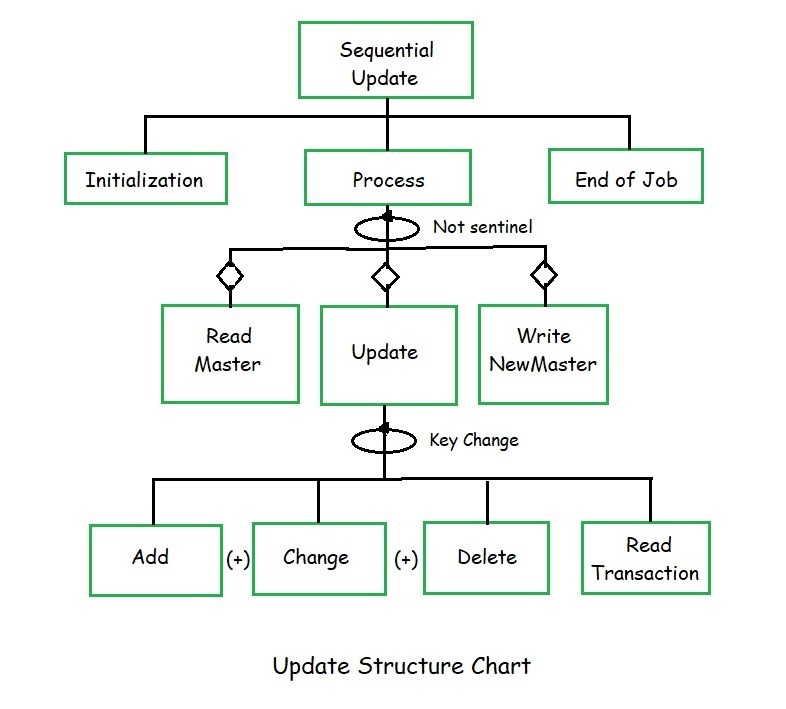
Update Logic:
Initialization is a function that opens the files and otherwise prepares the environment for processing. The mainline processing is done in Process. End of Job is a function that closes the files and displays any end of job messages.
Pseudocode for File Update:
1 read first record from transaction file
2 read first record from old master file
3 select next entity to be processed
4 loop current entity not sentinel
1 if current entity equals old master entity
1 copy old master to new master work area
2 read old master file
2 end if
3 if current entity equals transaction entity
1 update new master work area
4 end if
5 if current entity equals new master entity
1 write new master file
6 end if
7 select next entity to be processed
5 end loop
The first three statements contain initialization logic for Process. The driving force behind the update logic is that in each while loop, all the data is processed for one entity. To determine which entity, the next (statements and 4.7) are processed, the current entry is determined by comparing the current transaction key to the current master key. The current key is the smaller.
Before comparing the keys, however the first record must be read in each file. This is known as priming the files and is seen in statements 1 and 2. The loop statement in Algorithm contains the driving logic for the entire program. It is built on a very simple principle: As long as data are present in either the transaction file or the master file, the loop continues. When a file has been completely read, its key is set to a sentinel value. When both files are at their end, therefore, both of their keys will be sentinels. Then, what is selected as the next entity to be processed, it will be a sentinel, which is the event that terminates the while loop.
Three major processing functions take place in the while loop.
- First, it is determined if the entity on the old master file needs to be processed. If it does, it is moved to the new master output area and the next entity is read from the old master file. The key on the old master can match the current key in two situations: a change or delete transaction exists for the current entity. This logic is seen in statement 4.1.
- The second major process handles transactions that match the current entity. It calls a function that determines the type of transaction being processed (add, change, or delete) and handles it accordingly. If it is an add, it moves the new entity data to the new master area. If it is a change, it updates the data in the new master area. And if it is a delete, it clears the key in the new master area so that the record will not be written. To handle multiple transactions in the update function, it reads the next transaction and continues if its key matches the current entity.
- The last major process writes the new master when appropriate. If the current entity matches the key in the new master file area, then the record needs to be written to the file. This will be the case unless a delete transaction was processed.
Share your thoughts in the comments
Please Login to comment...