Difference Between Distinct and Group By in PL/SQL
Last Updated :
12 Mar, 2024
In PL/SQL, knowing the difference between DISTINCT and GROUP BY is important for working with data effectively. Although DISTINCT and GROUP BY might seem similar, they serve different purposes. In this article, we’ll explore DISTINCT and GROUP BY Clause with the syntax and various examples along the difference between them for better understanding.
What is the DISTINCT Clause?
The DISTINCT clause is used to retrieve unique values from a specific column or combination of columns in a result set. It eliminates duplicate rows and ensures that only distinct values are returned. DISTINCT can improve query performance by reducing the amount of data that needs to be processed and returned. This can lead to faster query execution times, especially when dealing with large datasets.
Syntax:
SELECT DISTINCT column1, column2
FROM table_name;
Explanation: This query selects unique combinations of values from specified columns in the table.
What is GROUP BY Clause?
The GROUP BY clause is used in conjunction with aggregate functions like SUM, AVG, COUNT, MIN, and MAX to group the result set by one or more columns. It is used to divide the rows returned from the SELECT statement into groups based on the specified columns.
Syntax:
GROUP BY: SELECT column1, aggregate_function(column2) FROM table_name GROUP BY column1;
Explanation: This query groups rows based on the values in column1 and applies the aggregate function to column2 for each group.
Examples of DISTINCT and GROUP BY Clause
To understand DISTINCT and GROUP BY Clause in PL/SQL we need a table on which we will perform various operations and queries. Here we will consider a table called employees which contains employee_id, employee_name, salary, age and department_name as Columns.
Query:
-- Create table with new fields
CREATE TABLE employees (
employee_id INT,
employee_name VARCHAR(50),
department_name VARCHAR(50),
salary DECIMAL(10, 2),
age INT
);
-- Insert values into the table
INSERT INTO employees (employee_id, employee_name, department_name, salary, age)
SELECT 1, 'John', 'Sales', 62000, 30 FROM DUAL
UNION ALL
SELECT 2, 'Alice', 'IT', 68000, 35 FROM DUAL
UNION ALL
SELECT 3, 'Bob', 'Sales', 65000, 28 FROM DUAL
UNION ALL
SELECT 4, 'Emma', 'HR', 48000, 40 FROM DUAL
UNION ALL
SELECT 5, 'Alice', 'Marketing', 62000, 32 FROM DUAL
UNION ALL
SELECT 6, 'Jane', 'IT', 65000, 29 FROM DUAL;
-- Show table
SELECT * FROM EMPLOYEES;
After Inserting some records into the employees, the table looks:
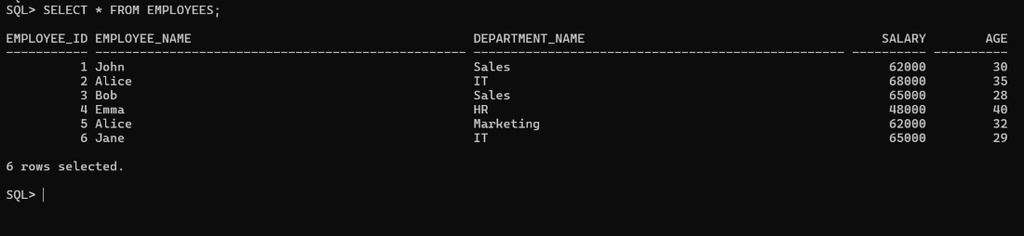
Employee table
Example of DISTINCT Clause
Example 1: Find Distinct Department Names
Suppose we have a table named employees with duplicate entries. To fetch unique department names, we use the DISTINCT clause.
Query:
SELECT DISTINCT department_name
FROM employees;
Output:

Explanation: This query retrieves unique department names from the employees table. Each department name appears only once in the output.
Example 2: Find Distinct employee Names
Query:
SELECT DISTINCT employee_name
FROM employees;
Output:

Explanation: This query retrieves unique employee names from the employees table. Each employee name appears only once in the output.
Example of GROUP BY Clause
Example 1: Calculating Sum of Salaries of employees According to Deparment
Calculating the sum of salaries of employees of each department using SUM() function.
Query:
SELECT department_name, SUM(salary) AS total_salary
FROM employees
GROUP BY department_name;
Output:

Explanation: This query calculates the total salary for each department by summing up the salaries of all employees within each department.
Example 2: Calculating Average Age of employees According to Department
Calculating the average age of employees of each department using AVG() function.
Query:
SELECT department_name, AVG(age) AS avg_age
FROM employees
GROUP BY department_name;
Output:

Explanation: This query calculates the average age of employees in each department by averaging the ages of all employees within each department.
Difference Between DISTINCT and GROUP BY
The Differnce between “DISTINCT” and “GROUP BY” is as follows:
|
DISTINCT
|
GROUP BY
|
|
Retrieve unique values from one or more columns in the result set.
|
Group rows based on specified columns in the result set.
|
|
Eliminates duplicate rows from the result set, ensuring each value appears only once.
|
Allows for the application of aggregate functions like SUM(), AVG(), COUNT(), etc., to calculate summary information for each group.
|
|
Operates on individual columns or combinations of columns specified in the SELECT statement.
|
Rows with identical values in the specified columns are grouped together.
|
|
Has a simple syntax and is easy to use in SQL queries.
|
GROUP BY can operate on multiple columns and allows for complex grouping criteria.
|
|
Results in a single column or multiple columns with unique values.
|
Results in multiple groups, each with its own summary information based on the aggregated data.
|
|
Does not perform any calculations or aggregations on the data that focuses on uniqueness.
|
Can be combined with conditional expressions or CASE statements for more complex aggregations.
|
|
Often used to filter out duplicate records when querying databases.
|
Suitable for summarizing data based on certain criteria, such as department-wise sales totals or average test scores per student.
|
|
Generally faster for small result sets as it only needs to eliminate duplicates without any calculations.
|
May be slower, especially with large data sets, due to the grouping and potential aggregations involved.
|
|
Ideal for obtaining a list of unique values from specific columns, such as unique product names or customer IDs.
|
Essential for performing complex analyses, such as identifying trends or patterns within data sets.
|
Conclusion
Overall, understanding the differences between DISTINCT and GROUP BY clauses in PL/SQL is crucial for efficient data manipulation. DISTINCT is used to retrieve unique values from columns, eliminating duplicates and ensuring each value appears only once. On the other hand, GROUP BY is used to group rows based on specified columns, allowing for the application of aggregate functions to calculate summary information for each group. While DISTINCT is suitable for obtaining unique values, GROUP BY is essential for performing complex analyses and summarizing data based on certain criteria.
Share your thoughts in the comments
Please Login to comment...