DFD Based Threat Modelling | Set 2
Last Updated :
29 Sep, 2022
Prerequisite – Threat Modelling, DFD Based Threat modelling | Set 1
Visual representation using DFD:
DFD is iterative in nature. Thus modelling a system involves the construction of different levels of DFD. This means to accurately reflect the system, DFD must be organized in a hierarchical way. Following the various shapes that are used in a DFD:
1 Process –
Each process in a DFD is given a unique number where the subprocess will have a number prefixed with the parent process number. Process means an entity that performs a specific task on a given data. Following is the shape for a process:
2 Multiple process –
This means the process has a subprocess and the subprocess number is prefixed by the parent process number. For example, the parent process number is 1. Then subprocess will have number 1.1 and subprocess will have number 1.1.1 and so on. Shape for Multiple process is as follows:
3 External entity –
It can only interact at the Entry point or exit point and is located outside the system. It may only interact with process or multiple processes. It can be either source of data or a destination of data. Below is the shape for an external entity used in DFD:

4 Data store –
It is the place where data is stored or from where data is retrieved. It can only interact with process or multiple processes. Shape for Data Store is as follows:

5 Data flow –
This is used to show the movement of data between the elements. Below is the shape for Data Flow:
6 Trust boundary –
It is a boundary between trust levels or privileges. Following is the shape for trust boundary:

DFD starts with an overall context level diagram that represents the whole system as single multiple processes. Each node is then a more detailed DFD representing other processes.
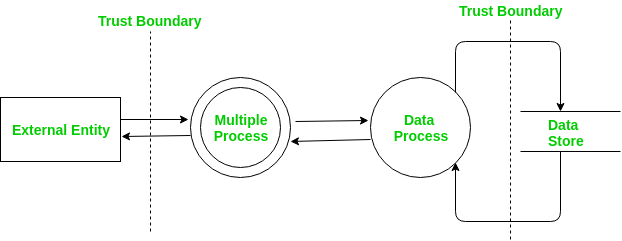
Determining threats –
This is the last step in threat modelling a system. After creating a DFD, the next step is to identify the goals adversary might have in the system. These goals are then used to determine the threat paths, locate entry/exit points and follow the data through the system to understand what data is supplied to which node.
Before going forward we will first understand what a threat path is. A threat path is a sequence of process nodes that perform some sort of security-critical operation and are thus vulnerable to an attack. All the process nodes where there is a change or action on behalf of data are susceptible to threats.
Following are the series of steps conducted in this phase.
Threat profile –
This is the security design specification that describes the following two things: first the possible goals of an adversary in the system and second and most important the vulnerabilities that exist due to these goals.
Each identified threat should either be prevented or mitigated. The threat profiles encompass following key areas:
- Identify the threats –
Threat identification is a very important step towards building a secure system. Identifying threats is a 3 step process where the first step involves analyzing each entry/exit point, the second step involves identifying the nature and type of critical processing occurring at entry/exit points and the third and the last step involves thinking and describing how entry/exit point might be attacked. Identifying threats is not an easy process to do. It involves asking questions like:
Is it possible for an adversary to gain access to assets without being audited or by skipping access controls or by acting as another user?
How an adversary can use or manipulate data to retrieve information from the system or edit information in the system or modify/control the system or gain additional privileges or cause the system to fail or become unusable.
These are just the basic questions. It requires a lot of brainstorming on the part of the security team to identify as many possible threats.
The next step in identifying threats is threats classification. STRIDE is one of the methods that we use in conjunction with DFD for threat classification. We have discussed STRIDE in the previous article.
- Investigate and analyse the threats –
After identifying threats next step is to conduct an in-depth analysis of identified threats to determine vulnerable areas and valid attack paths.
Threat trees are used for this purpose. There are two ways to express a threat tree: one is the graphical way, another is using the textual representation.
The basic structure of a threat tree consists of a root node and child nodes. Each child node represents a condition needed for the adversary to find and identify the threats. The procedure to identify the vulnerabilities involve beginning at a node with no child and then traversing is done in a bottom-up manner up to the root.
Another step in analyzing threats involves determining the risk of threats and threat conditions. This is done by using DREAD Model. We have discussed this model in the previous article.
- Mitigate the vulnerabilities caused by the threats –
Till this point, all threats have been identified and resolved. If any threat remains still unresolved then it will result in a vulnerability. Upon completion of the threat tree, attack paths are identified. If any attack path is not mitigated, it will result in Vulnerability. A threat modelling document consisting of threats, threat trees, vulnerabilities and mitigation’s This threat document will be used in the design phase as a security specification document and in the testing phase as a base to identify the vulnerable areas of the system.
Share your thoughts in the comments
Please Login to comment...