Decomposition In DBMS
Last Updated :
18 Mar, 2024
Decomposition refers to the division of tables into multiple tables to produce consistency in the data. In this article, we will learn about the Database concept. This article is related to the concept of Decomposition in DBMS. It explains the definition of Decomposition, types of Decomposition in DBMS, and its properties.
What is Decomposition in DBMS?
When we divide a table into multiple tables or divide a relation into multiple relations, then this process is termed Decomposition in DBMS. We perform decomposition in DBMS when we want to process a particular data set. It is performed in a database management system when we need to ensure consistency and remove anomalies and duplicate data present in the database. When we perform decomposition in DBMS, we must try to ensure that no information or data is lost.
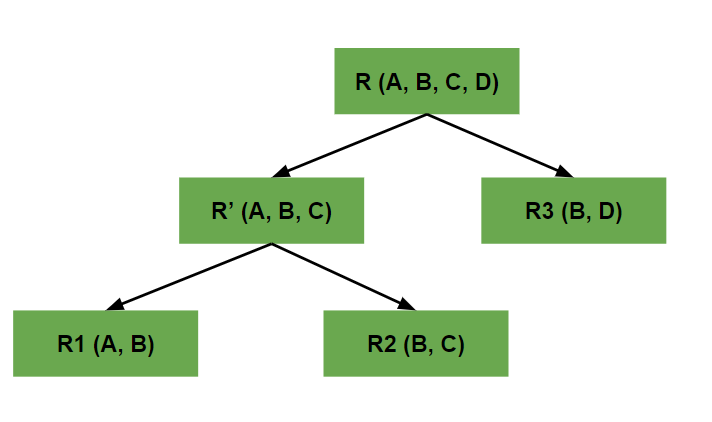
Decomposition in DBMS
Types of Decomposition
There are two types of Decomposition:
- Lossless Decomposition
- Lossy Decomposition

Types of Decomposition
Lossless Decomposition
The process in which where we can regain the original relation R with the help of joins from the multiple relations formed after decomposition. This process is termed as lossless decomposition. It is used to remove the redundant data from the database while retaining the useful information. The lossless decomposition tries to ensure following things:
- While regaining the original relation, on information should be lost.
- If we perform join operation on the sub-divided relations, we must get the original relation.
Example:
There is a relation called R(A, B, C)
Now we decompose this relation into two sub relations R1 and R2
R1(A, B)
R2(B, C)
After performing the Join operation we get the same original relation
Lossy Decomposition
As the name suggests, lossy decomposition means when we perform join operation on the sub-relations it doesn’t result to the same relation which was decomposed. After the join operation, we always found some extraneous tuples. These extra tuples genrates difficulty for the user to identify the original tuples.
Example:
We have a relation R(A, B, C)
Now , we decompose it into sub-relations R1 and R2
R1(A, B)
R2(B, C)
Now After performing join operation
|
A
|
B
|
C
|
|
1
|
2
|
1
|
|
2
|
5
|
3
|
|
2
|
3
|
3
|
|
3
|
5
|
3
|
|
3
|
3
|
3
|
Properties of Decomposition
- Lossless: All the decomposition that we perform in Database management system should be lossless. All the information should not be lost while performing the join on the sub-relation to get back the original relation. It helps to remove the redundant data from the database.
- Dependency Preservation: Dependency Preservation is an important technique in database management system. It ensures that the functional dependencies between the entities is maintained while performing decomposition. It helps to improve the database efficiency, maintain consistency and integrity.
- Lack of Data Redundancy: Data Redundancy is generally termed as duplicate data or repeated data. This property states that the decomposition performed should not suffer redundant data. It will help us to get rid of unwanted data and focus only on the useful data or information.
Conclusion
Decomposition is an important term in Database Management system. It refers to the method of splitting the realtions into multiple relation so that database operations are performed efficiently. There are two types of decomposition one is lossless and the other is lossy decomposition. The properties of Decomposition helps us to maintain consistency, reduce redundant data and remove the anomalies.
Frequently Asked Questions on Decomposition in DBMS – FAQs
What is the condition in Dependency Preservation?
In Dependency Preservation, the condition is that the every dependency should get satisfied by at least one table which is in decomposed form.
Why do we use decomposition in DBMS?
Decomposition in DBMS is used to remove the redundant data, inconsistent data.
What is the condition to term a decomposition as a lossless decomposition?
To term a decomposition as a lossless decomposition, there should be natural joins between all the decompositions.
List the advantages of Decomposition in DBMS.
Here are some of the advantages that Decomposition offers:
- It helps to reduce the data redundancy.
- It enhances the efficiency of the database.
- It helps to reduce the storage space requirements.
- It helps to prevent the data inconsistencies.
Which factors associated with the bad design get reduced after performing decomposition of design?
After performing decomposition of design, factors like Anomalies, Inconsistencies, Redundancies get reduced.
Share your thoughts in the comments
Please Login to comment...