The need for efficient and concise URL management has become a big matter in this technical age. URL shortening services, such as bit.ly, and TinyURL, play a massive role in transforming lengthy web addresses into shorter, shareable links. As the demand for such services grows, it has become vital to undertand the System Design of URL Shortner and mastering the art of designing a scalable and reliable URL-shortening system, to gain a crucial skill for software engineers.
.jpg)
This article gets into the System Design of URL Shortner (URL Shortening Service), which will help in architecting a robust system that can seamlessly generate and redirect short URLs while ensuring scalability, durability, and high availability.
Important Topics for System Design of URL Shortner (URL Shortening Service)
How Would You Design a URL Shortener Service Like TinyURL?
URL shortening services like bit.ly or TinyURL are very popular to generate shorter aliases for long URLs. You need to design this kind of web service where if a user gives a long URL then the service returns a short URL and if the user gives a short URL then it returns the original long URL.
For example, shortening the given URL through TinyURL:
https://www.geeksforgeeks.org/system-design-interview-bootcamp-guide/
We get the result given below:
http://bit.ly/3uQqImU
When you’re asked this question in your interviews don’t jump into the technical details immediately. Most of the candidates make mistakes here and immediately they start listing out some bunch of tools, databases, and frameworks. In this kind of question, the interviewer wants a high-level design idea where you can give the solution for the scalability and durability of the service.
1. Requirements for System Design of URL Shortner Service
1.1 Functional requirements of URL Shortening service
- Given a long URL, the service should generate a shorter and unique alias for it.
- When the user hits a short link, the service should redirect to the original link.
- Links will expire after a standard default time span.
1.2 Non-Functional requirements URL Shortening service
- The system should be highly available. This is really important to consider because if the service goes down, all the URL redirection will start failing.
- URL redirection should happen in real-time with minimal latency.
- Shortened links should not be predictable.
2. Capacity estimation for System Design of URL Shortner
Let’s assume our service has 30M new URL shortenings per month. Let’s assume we store every URL shortening request (and associated shortened link) for 5 years. For this period the service will generate about 1.8 B records.
30 million * 5 years * 12 months = 1.8B
Note: Let’s consider we are using 7 characters to generate a short URL. These characters are a combination of 62 characters [A-Z, a-z, 0-9] something like http://ad.com/abXdef2.
2.1 Data Capacity Modeling
Discuss the data capacity model to estimate the storage of the system. We need to understand how much data we might have to insert into our system. Think about the different columns or attributes that will be stored in our database and calculate the storage of data for five years. Let’s make the assumption given below for different attributes…
- Consider the average long URL size of 2KB ie for 2048 characters.
- Short URL size: 17 Bytes for 17 characters
- created_at- 7 bytes
- expiration_length_in_minutes -7 bytes
The above calculation will give a total of 2.031KB per shortened URL entry in the database.
If we calculate the total storage then for 30 M active users
total size = 30000000 * 2.031 = 60780000 KB = 60.78 GB per month. In a Year of 0.7284 TB and in 5 years 3.642 TB of data.
Note: We need to think about the reads and writes that will happen on our system for this amount of data. This will decide what kind of database (RDBMS or NoSQL) we need to use.
3. Low Level Design for System Design of URL Shortner

3.1 URL Encoding Techniques to create Shortened URL
To convert a long URL into a unique short URL we can use some hashing techniques like Base62 or MD5. We will discuss both approaches.
1. Base62 Encoding
- Base62 encoder allows us to use the combination of characters and numbers which contains A-Z, a-z, 0–9 total( 26 + 26 + 10 = 62).
- So for 7 characters short URL, we can serve 62^7 ~= 3500 billion URLs which is quite enough in comparison to base10 (base10 only contains numbers 0-9 so you will get only 10M combinations).
- We can generate a random number for the given long URL and convert it to base62 and use the hash as a short URL id.
If we use base62 making the assumption that the service is generating 1000 tiny URLs/sec then it will take 110 years to exhaust this 3500 billion combination.
Python3
def to_base_62(deci):
s = '012345689abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
hash_str = ''
while deci > 0:
hash_str = s[deci % 62] + hash_str
deci /= 62
return hash_str
print to_base_62(999)
|
Javascript
function to_base_62(deci) {
var hash_str, s;
s = "012345689abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
hash_str = "";
while (deci > 0) {
var b = parseInt(deci % 62);
var a = s[b] ? s[b]: "";
hash_str = hash_str+a;
deci = parseInt(deci/62);
console.log("b",b,"a",a, "deci", deci);
}
return hash_str;
}
to_base_62(64);
|
2. MD5 Encoding
MD5 also gives base62 output but the MD5 hash gives a lengthy output which is more than 7 characters.
- MD5 hash generates 128-bit long output so out of 128 bits we will take 43 bits to generate a tiny URL of 7 characters.
- MD5 can create a lot of collisions. For two or many different long URL inputs we may get the same unique id for a short URL and that could cause data corruption.
- So we need to perform some checks to ensure that this unique id doesn’t exist in the database already.
3.2 Efficient Database Storage & Retrieval of TinyURL
Let’s discuss the mapping of a long URL into a short URL in our database:
1. Using Base62 Encoding
Assume we generate the Tiny URL using base62 encoding then we need to perform the steps given below:
- The tiny URL should be unique so firstly check the existence of this tiny URL in the database (doing get(tiny) on DB). If it’s already present there for some other long URL then generate a new short URL.
- If the short URL isn’t present in DB then put the long URL and TinyURL in DB (put(TinyURL, long URL)).
This technique works with one server very well but if there will be multiple servers then this technique will create a race condition.
- When multiple servers will work together, there will be a possibility that they all can generate the same unique id or the same tiny URL for different long URLs
- Even after checking the database, they will be allowed to insert the same tiny URLs simultaneously in the database and this may end up corrupting the data.
We can use putIfAbsent(TinyURL, long URL) or INSERT-IF-NOT-EXIST condition while inserting the tiny URL but this requires support from DB which is available in RDBMS but not in NoSQL.
2. Using MD5 Approach
- Encode the long URL using the MD5 approach and take only the first 7 chars to generate TinyURL.
- The first 7 characters could be the same for different long URLs so check the DB (as we have discussed in Technique 1) to verify that TinyURL is not used already
This approach saves some space in the database but how?
- If two users want to generate a tiny URL for the same long URL then the first technique will generate two random numbers and it requires two rows in the database
- In the second technique, both the longer URL will have the same MD5 so it will have the same first 43 bits
- This means we will get some deduping and we will end up with saving some space since we only need to store one row instead of two rows in the database.
Note: We can use putIfAbsent but NoSQL doesn’t support this feature. So let’s move to the third technique to solve this problem.
3. Using Counter Approach
Using a counter is a good decision for a scalable solution because counters always get incremented so we can get a new value for every new request.
Single server approach:
- A single host or server (say database) will be responsible for maintaining the counter.
- When the worker host receives a request it talks to the counter host, which returns a unique number and increments the counter. When the next request comes the counter host again returns the unique number and this goes on.
- Every worker host gets a unique number which is used to generate TinyURL.
Now Let’s Discuss a problem:
If the counter host goes down for some time then it will create a problem, also if the number of requests will be high then the counter host might not be able to handle the load. So challenges are a Single point of failure and a single point of bottleneck.
what if there are multiple servers?
You can’t maintain a single counter and returns the output to all the servers. To solve this problem we can use multiple internal counters for multiple servers which use different counter ranges.
For example: Server 1 ranges from 1 to 1M, server 2 ranges from 1M to 10M, and so on.
But still there are some problems with this architecture such as:
- If one of the counters goes down then for another server it will be difficult to get the range of the failure counter and maintain it again.
- If one counter reaches its maximum limit then resetting the counter will be difficult because there is no single host available for coordination among all these multiple servers.
- The architecture will be messed up since we don’t know which server is the master or which one is a slave and which one is responsible for coordination and synchronization.
Now let’s discuss the solution
To solve this problem we can use a distributed service Zookeeper to manage all these tedious tasks and to solve the various challenges of a distributed system like a race condition, deadlock, or particle failure of data.
Zookeeper is basically a distributed coordination service that manages a large set of hosts. It keeps track of all the things such as the naming of the servers, active servers, dead servers, and configuration information of all the hosts. It provides coordination and maintains the synchronization between the multiple servers.
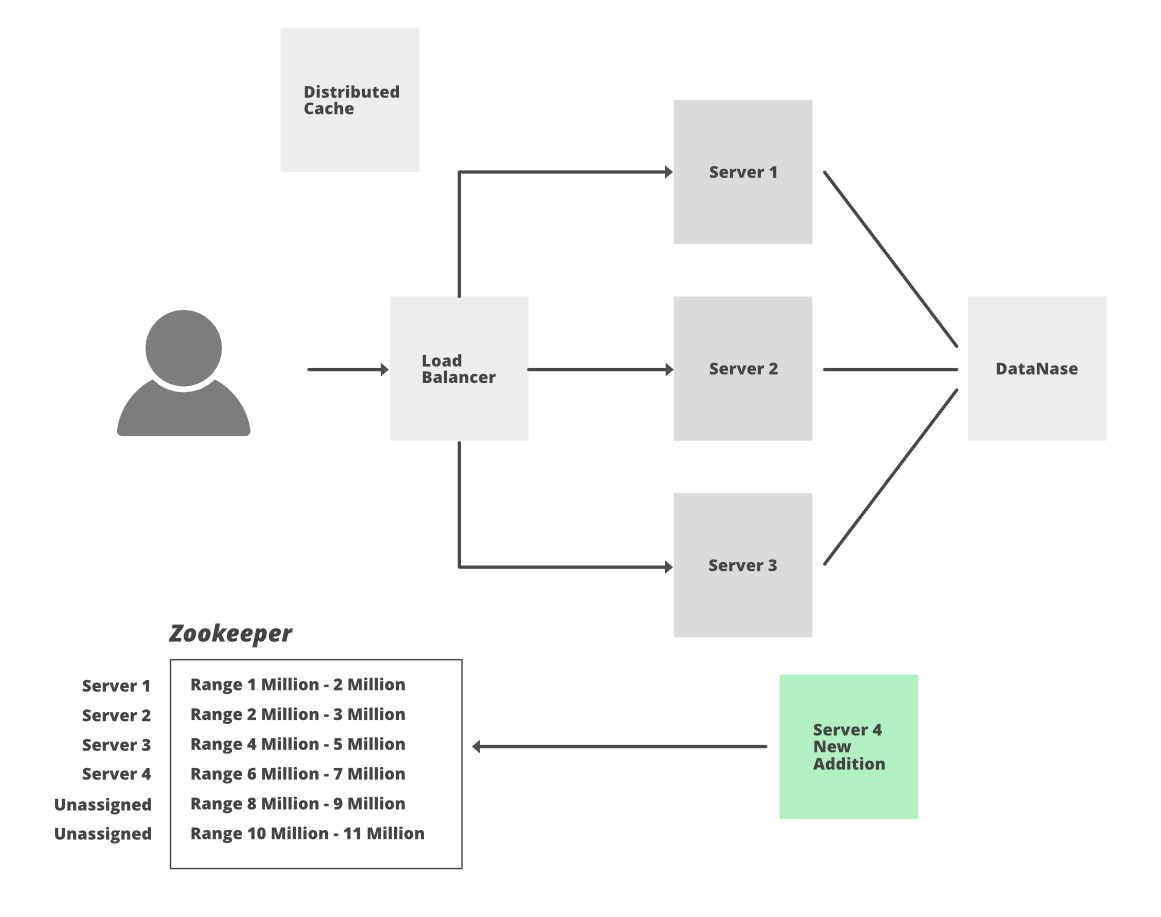
Let’s discuss how to maintain a counter for distributed hosts using Zookeeper.
- From 3.5 trillion combinations take 1st billion combinations.
- In Zookeeper maintain the range and divide the 1st billion into 1000 ranges of 1 million each i.e. range 1->(1 – 1,000,000), range 2->(1,000,001 – 2,000,000)…. range 1000->(999,000,001 – 1,000,000,000)
- When servers will be added these servers will ask for the unused range from Zookeepers.
- Suppose the W1 server is assigned range 1, now W1 will generate the tiny URL incrementing the counter and using the encoding technique.
- Every time it will be a unique number so there is no possibility of collision and also there is no need to keep checking the DB to ensure that the URL already exists or not.
- We can directly insert the mapping of a long URL and a short URL into the DB.
- In the worst case, if one of the servers goes down then we will only lose a million combinations in Zookeeper (which will be unused and we can’t reuse it as well) but since we have 3.5 trillion combinations we should not worry about losing this combination.
- If one of the servers will reach its maximum range or limit then again it can take a new fresh range from Zookeeper.
- The addition of a new server is also easy. Zookeeper will assign an unused counter range to this new server.
- We will take the 2nd billion when the 1st billion is exhausted to continue the process.
4. High-level Design of a URL-Shortening Service
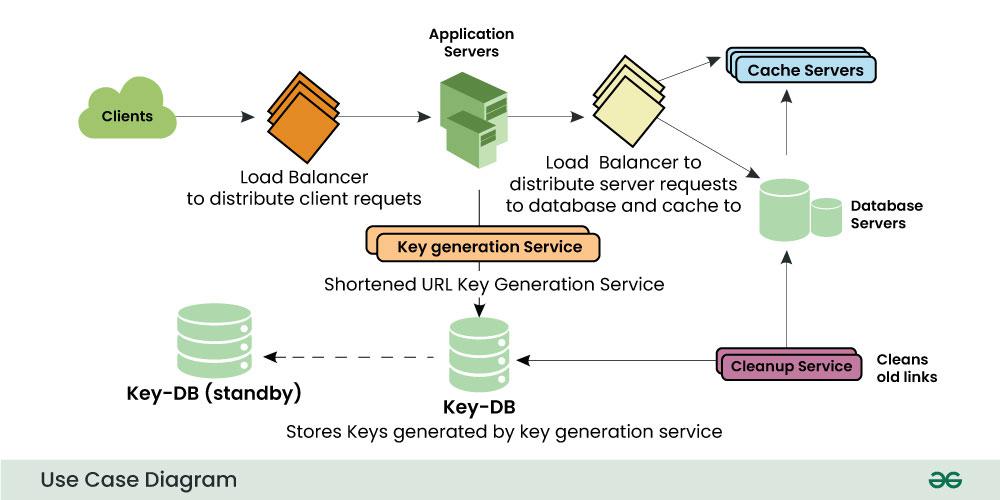
4.1 User Interface/Clients
The user interface allows users to enter a long URL and receive a shortened link. This could be a simple web form or a RESTful API.
4.2 Application Server
The application server receives the long URL from the user interface and generates a unique, shorter alias or key for the URL. It then stores the alias and the original URL in a database. The application server also tracks click events on the shortened links.
4.3 Load Balancer
To handle a large number of requests, we can use a load balancer to distribute incoming traffic across multiple instances of the application server. We can add a Load balancing layer at three places in our service:
- Between Clients and Application servers
- Between Application Servers and database servers
- Between Application Servers and Cache servers
4.4 Database
The database stores the alias or key and the original URL. The database should be scalable to handle a large number of URLs and clicks. We can use NoSQL databases such as MongoDB or Cassandra, which can handle large amounts of data and can scale horizontally.
As soon as a key is used, it should be marked in the database to ensure it doesn’t get used again. If there are multiple servers reading keys concurrently, we might get a scenario where two or more servers try to read the same key from the database
4.5 Caching
Since reading from the database can be slow and resource-intensive, we can add a caching layer to speed up read operations. We can use in-memory caches like Redis or Memcached to store the most frequently accessed URLs.
4.6 Cleanup Service
This service helps in cleaning the old data from the databases
4.7 Redirection
When a user clicks on a shortened link, the application server looks up the original URL from the database using the alias or key. It then redirects the user to the original URL using HTTP 301 status code, which is a permanent redirect.
4.8 Analytics
The application server should track click events on the shortened links and provide analytics to the user. This includes the number of clicks, the referrer, the browser, and the device used to access the link.
4.9 Security
The service should be designed to prevent malicious users from generating short links to phishing or malware sites. It should also protect against DDoS attacks and brute force attacks. We can use firewalls, rate-limiting, and authentication mechanisms to ensure the security of the service.
5. Database
Let us explore some of the choices for System Design of Databases of URL Shortner:
- We can use RDBMS which uses ACID properties but you will be facing the scalability issue with relational databases.
- Now if you think you can use sharding and resolve the scalability issue in RDBMS then that will increase the complexity of the system.
- There are 30M active users so there will be conversions and a lot of Short URL resolution and redirections.
- Read and write will be heavy for these 30M users so scaling the RDBMS using shard will increase the complexity of the design.
You may have to use consistent hashing to balance the traffics and DB queries in the case of RDBMS and which is a complicated process. So to handle this amount of huge traffic on our system relational databases are not fit and also it won’t be a good decision to scale the RDBMS.
So let’s take a look at NoSQL Database:
- The only problem with using the NoSQL database is its eventual consistency.
- We write something and it takes some time to replicate to a different node but our system needs high availability and NoSQL fits this requirement.
- NoSQL can easily handle the 30M of active users and it is easy to scale. We just need to keep adding the nodes when we want to expand the storage.
Conclusion
Overall, a URL shortening service is a simple but useful application that can be built using a variety of technologies and architectures. By following the above architecture, we can build a scalable, reliable, and secure URL-shortening service.
Share your thoughts in the comments
Please Login to comment...