Data Distribution in Cassandra
Last Updated :
18 Nov, 2019
In this article we will discussed Data distribution in Cassandra and how data distributes over cluster. So, let’s have a look.
In Cassandra data distribution and replication go together. In Cassandra distribution and replication depending on the three thing such that partition key, key value and Token range.
Cassandra Table:
In this table there are two rows in which one row contains four columns and its values. 2nd row contains two columns (column 1 and column 3) and its values. In this table column 1 having the primary key.

Figure – Cassandra Table
Now, let’s take an example of how user data distributes over cluster.
| E_id |
E_name |
E_sal |
| 101 |
Ashish |
90000 |
| 102 |
Aayush |
95000 |
| 103 |
Rahul |
70000 |
| 104 |
Abi |
60000 |
Below given ring architecture of given four nodes has token range and each row has its own token id so, with the help of partitioner we will generate token values and assigned them and distribute over cluster accordingly.
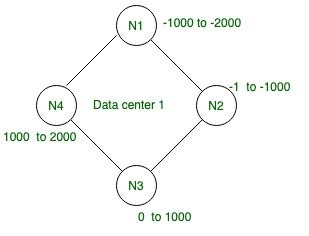
Figure – Data Center with Random token range
Token: Tokens are hash values and Murmur3 Hash Algorithm is use for hashing in Cassandra that partitioners use to determine where to store rows on each node in the ring.
for Example: let’s take random hash value for each row for given data in above table.
| Partition key |
Murmur3 Hash value |
| Ashish |
1500 |
| Aayush |
-800 |
| Rahul |
-1500 |
| Abi |
700 |
Let’s have a look for better understanding.
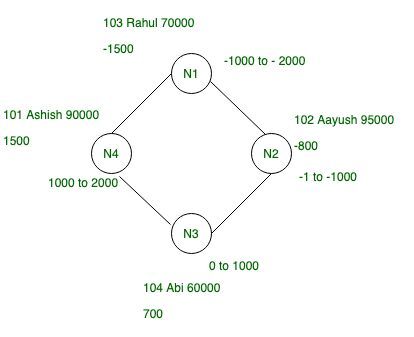
Figure – Example of Data Distribution in Cassandra
Replication Factor: In Cassandra replication factor is very important which indicates the total number of replicas across the cluster.
Let’s take RF = 2 which simply means that there are two copies of each rows. There is no primary or master replica in Cassandra.
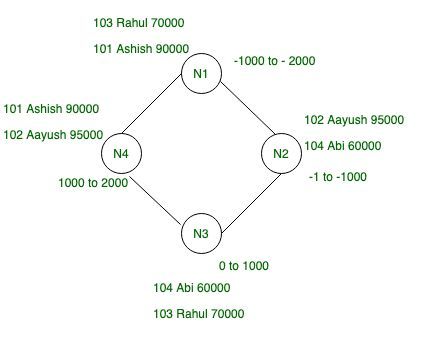
Figure – Example of data distribution when RF = 2
Share your thoughts in the comments
Please Login to comment...