CQRS – Command Query Responsibility Segregation Design Pattern
Last Updated :
14 Mar, 2024
The Command Query Responsibility Segregation (CQRS) design pattern has emerged as a powerful architectural pattern for building complex and scalable software systems. By separating the responsibilities of reading and writing data, CQRS allows for more flexible and efficient designs, particularly in domains with high-performance and scalability requirements. In this article, we will explore the key concepts of CQRS, its benefits and challenges, and how it can be implemented in real-world applications.

Important Topics for the CQRS Design Pattern
What is the CQRS Design Pattern?
CQRS(Common Querry Responsibility Segregation) is a type of design pattern that separates the responsibility of handling commands and queries into different components. CQRS architectural pattern mainly focuses on separating the way of reading and writing the data. It separates the read and update operations on a datastore into two separate models: Queries and Commands, respectively.
- As software systems grow in complexity, it becomes increasingly challenging to manage the data that they handle.
- In such scenarios, traditional approaches to database design, which assume that there is one model for handling both reads and writes, can be inadequate.
- Implementing CQRS in our application can maximize its performance, scalability, and security.
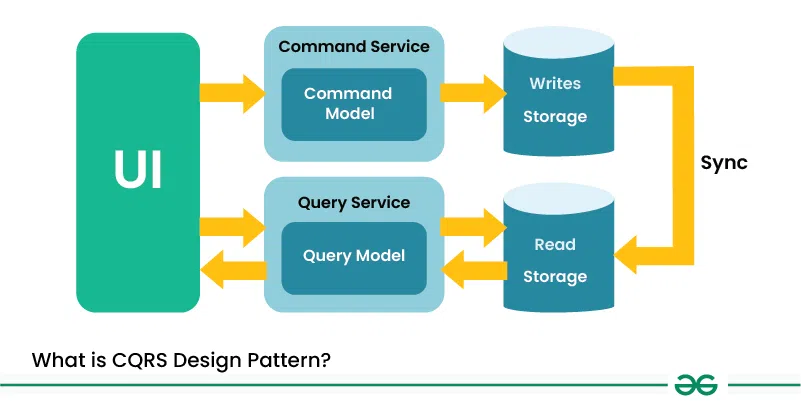
Basic Architecture of CQRS Design Pattern
1. Commands
Commands are instructions that indicate a desired change in the state of an entity. these commands execute operations such as Insert, Update, and Delete. they do not return data, but instead, change the application server’s state. each command is an object containing the name of the operation along with the necessary data to perform that operation.
2. CommandHandlers
CommandHandlers interpret these commands and return an event. this event can be a successful event or a failure event depending on the outcome of the command. If the command is successful, a successful event is created; however, if the command fails, a failure event is created.
3. Queries
Queries are used to retrieve information from a database. Queries objects just return data and make no modifications to it. Queries will solely comprise data retrieval methods. They are used to read data from the database and return it to the client for display in the user interface. The QueryHandlers interpret the queries and return query values.
When to use CQRS Design Pattern?
CQRS is employed in situations when using a single database and model to handle both reads and writes is inefficient. E-commerce websites, financial systems, and real-time analytics are examples of applications that require great scalability, performance, and data complexity.
- One of the primary benefits of using the CQRS is that it simplifies the design of complex systems by separating the concerns of commands and queries.
- This separation allows developers to optimize each model for its specific responsibilities and requirements.
- The command model can be optimized for high write performance and data integrity, while the query model can be optimized for high read performance and fast access to data.
How to Sync Databases with CQRS Design Pattern?
Synchronizing databases in a system that follows the CQRS (Command Query Responsibility Segregation) pattern can be challenging due to the separation of the write and read sides of the application.
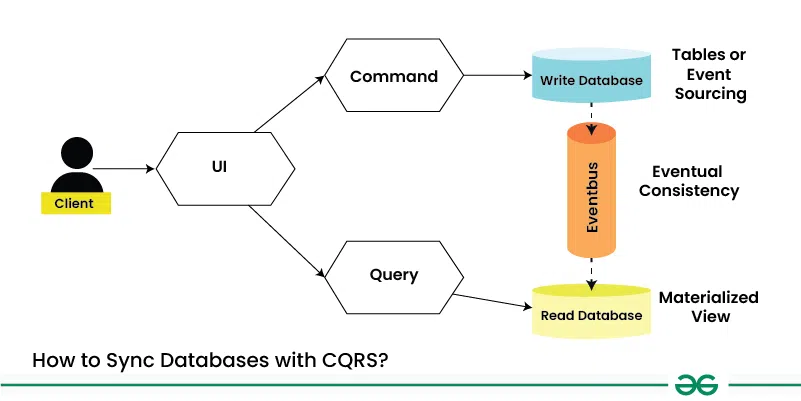
1. Event Sourcing
Event sourcing involves capturing all changes to an application’s state as a sequence of events. These events are stored in an event store and can be replayed to rebuild the state of the application at any point in time. In a CQRS architecture, the write model generates events when commands are processed, and the read model subscribes to these events to update its state.
- Benefits: Event sourcing provides a complete audit trail of all changes to the application’s state, which can be useful for debugging and compliance purposes. It also enables scalability and fault tolerance, as events can be replayed to rebuild the state in case of failure.
- Challenges: Event sourcing introduces complexity, as developers need to design the events and event handlers carefully to ensure consistency and correctness. It also requires additional infrastructure for storing and replaying events.
2. Messaging Systems
Messaging systems such as Kafka, RabbitMQ, or ActiveMQ can be used to decouple the synchronization process between the write and read sides of the application. The write model publishes events to a message queue, and the read model consumes these events to update its state.
- Benefits: Messaging systems provide a flexible and scalable way to synchronize databases, as they can handle large volumes of events and distribute them across multiple consumers. They also enable asynchronous communication, which can improve overall system performance.
- Challenges: Implementing messaging systems can introduce complexity, as developers need to ensure that messages are processed in the correct order and that data consistency is maintained. It also requires additional infrastructure for managing and monitoring the message queues.
Example of CQRS Design Pattern

Let’s understand CQRS Design Pattern through the example of E-commerce Website.
In our Ordering E-commerce microservices architecture, we’re introducing a new approach to database design using the CQRS pattern. We’ve decided to split our databases into two separate parts to better manage our data and improve performance.
- Firstly, we’ll have a write database that focuses on handling all write operations, such as creating and updating orders. This database will be optimized for transactional consistency and relational data modeling, making it suitable for managing the core data changes.
- Secondly, we’ll introduce a read database dedicated to handling read operations, such as querying for order details and order history. This database will be designed for high performance and scalability, using a NoSQL database like MongoDB or Cassandra.
Synchronization
To keep these two databases in sync, we’ll implement a messaging system using Apache Kafka. Kafka’s publish/subscribe model will allow us to propagate changes from the write database to the read database in real-time, ensuring that the data remains consistent across both databases.
Tech-Stack
For the tech stack, we’re considering using MySQL or PostgreSQL for the write database due to their strong support for ACID transactions and relational data modeling. For the read database, we’re leaning towards using MongoDB or Cassandra for their scalability and ability to handle large volumes of data efficiently.
By adopting the CQRS pattern and splitting our databases in this way, we believe we can improve the performance and scalability of our Ordering microservices, providing a better experience for our users.
Use Cases of CQRS Design Pattern
The CQRS (Command Query Responsibility Segregation) design pattern is particularly useful in several scenarios where the separation of read and write operations can bring significant benefits. Some common use cases include:
- Complex Domain Logic: When the domain logic of an application is complex and involves different processing requirements for reading and writing data, CQRS can help simplify the implementation by separating the two concerns.
- Performance Optimization: CQRS allows you to optimize read and write operations independently. This can be beneficial in scenarios where read operations significantly outnumber write operations, allowing you to scale the read side of the application independently for improved performance.
- Scalability: CQRS enables you to scale the read and write sides of your application independently based on their specific requirements. This can be useful in scenarios where the read and write workloads vary greatly.
- Event Sourcing: CQRS is often used in conjunction with event sourcing, where events are stored as a log and used to reconstruct the current state of the application. This approach can be beneficial in scenarios where you need to track changes to data over time and maintain a full audit trail.
- Reporting and Analytics: CQRS can be particularly useful in scenarios where you need to generate complex reports or perform analytics on your data. By separating the read side of the application, you can optimize it for reporting purposes without impacting the write side.
- Consistency Requirements: CQRS can be beneficial in scenarios where you have different consistency requirements for read and write operations. For example, you may want to provide eventual consistency for read operations while maintaining strong consistency for write operations.
Benefits of using Command Query Responsibility Segregation(CQRS) Design Pattern
Below are the benefits of CQRS Design Pattern:
- Improved Scalability: Each model can be optimized for a particular use case by splitting the duties of commands and queries. As a result, it is possible to optimize the query model for high read performance while the command model can be enhanced for high write performance. The system can scale more effectively and handle more complicated business rules thanks to this separation.
- Improved performance: The system can outperform a conventional strategy that employs a single model for both reads and writes by tailoring each model to its particular use case. The command model can be created to guarantee data consistency and integrity while the query model can be created to offer quick access to data.
- Maintainability: CQRS can also improve maintainability by making the system easier to understand and modify. Separating the responsibilities of commands and queries can make the codebase more modular and easier to reason about. This can make it easier to make changes to the system and add new features without introducing bugs or breaking existing functionality.
Challenges of using Command Query Responsibility Segregation(CQRS) Design Pattern
Below are the challenges of CQRS Design Pattern:
- Complexity: Implementing CQRS can introduce additional complexity to your system, especially if you’re not familiar with the pattern. Managing separate read and write models, coordinating data synchronization, and ensuring consistency between the two can be challenging tasks.
- Consistency: Maintaining consistency between the read and write models can be challenging, especially in distributed systems where data updates may not be immediately propagated. Ensuring eventual consistency without sacrificing performance or scalability requires careful design and implementation.
- Data Synchronization: Keeping the read and write models in sync can be a non-trivial task, especially when dealing with large volumes of data or complex data transformations. Using techniques like event sourcing or message queues can help, but they also introduce their own set of challenges.
- Performance Overhead: Implementing CQRS can introduce performance overhead, especially if not done carefully. For example, using event sourcing for the write model can impact write performance, while keeping the read model updated in real-time can impact read performance.
- Operational Complexity: Managing multiple databases or data stores (one for read and one for write) can increase operational complexity. This includes tasks like backup and restore, monitoring, and ensuring high availability and data durability.
Share your thoughts in the comments
Please Login to comment...