Concurrency Control in Distributed Transactions
Last Updated :
17 Apr, 2024
Concurrency control mechanisms provide us with various concepts & implementations to ensure the execution of any transaction across any node doesn’t violate ACID or BASE (depending on database) properties causing inconsistency & mixup of data in the distributed systems. Transactions in the distributed system are executed in “sets“, every set consists of various sub-transactions. These sub-transactions across every node must be executed serially to maintain data integrity & the concurrency control mechanisms do this serial execution.
Types of Concurrency Control Mechanisms
There are 2 types of concurrency control mechanisms as shown below diagram:

Types of Concurrency Control Mechanism
Pessimistic Concurrency Control (PCC)
The Pessimistic Concurrency Control Mechanisms proceeds on assumption that, most of the transactions will try to access the same resource simultaneously. It’s basically used to prevent concurrent access to a shared resource and provide a system of acquiring a Lock on the data item before performing any operation.
Optimistic Concurrency Control (OCC)
The problem with pessimistic concurrency control systems is that, if a transaction acquires a lock on a resource so that no other transactions can access it. This will result in reducing concurrency of the overall system.
The Optimistic Concurrency control techniques proceeds on the basis of assumption that, 0 or very few transactions will try to access a certain resource simultaneously. We can describe a system as FULLY OPTIMISTIC, if it uses No-Locks at all & checks for conflicts at commit time. It has following 4-phases of operation:
- Read Phase: When a transaction begins, it reads the data while also logging the time-stamp at which data is read to verify for conflicts during the validation phase.
- Execution Phase: In this phase, the transaction executes all its operation like create, read, update or delete etc.
- Validation Phase: Before committing a transaction, a validation check is performed to ensure consistency by checking the last_updated timestamp with the one recorded at read_phase. If the timestamp matches, then the transaction will be allowed to be committed and hence proceed with the commit phase.
- Commit phase: During this phase, the transactions will either be committed or aborted, depending on the validation check performed during previous phase. If the timestamp matches, then transactions are committed else they’re aborted.
Pessimistic Concurrency Control Methods
Following are the four Pessimistic Concurrency Control Methods:
Isolation Level
The isolation levels are defined as a degree to which the data residing in Database must be isolated by transactions for modification. Because, if some transactions are operating on some data let’s say transaction – T1 & there comes another transaction – T2 and modifies it further while it was under operation by transaction T1 this will cause unwanted inconsistency problems. Methods provided in this are: Read-Uncomitted, Read-Comitted, Repeatable Read & Serializable.
Two-Phase Locking Protocol
The two-phase locking protocol is a concurrency technique used to manage locks on data items in database. This technique consists of 2 phases:
Growing Phase: The transaction acquires all the locks on the data items that’ll be required to execute the transaction successfully. No locks will be realease in this phase.
Shrinking Phase: All the locks acquired in previous phase will be released one by one and No New locks will be acquired in this phase.
Distributed Lock Manager
A distributed lock a critical component in the distributed transaction system, which co-ordinates the lock acquiring, and releasing operations in the transactions. It helps in synchronizing the transaction and their operation so that data integrity is maintained.
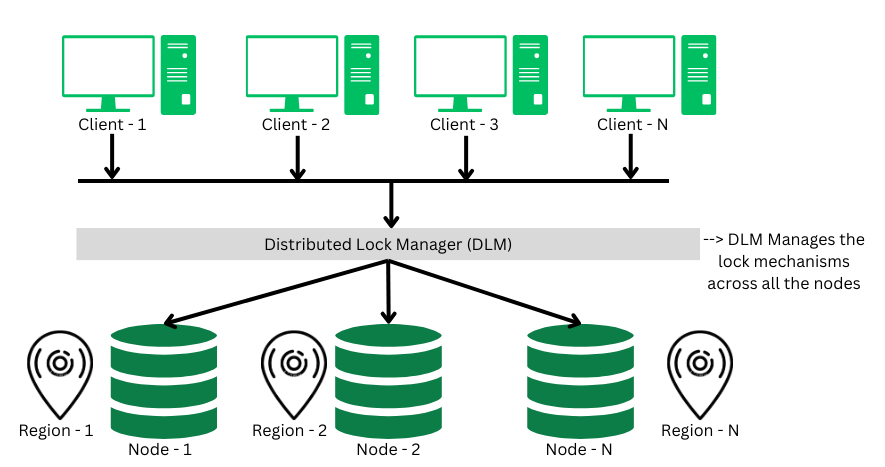
Distributed Lock Manager (DLM)
Multiple Granularity Lock
A lock can be acquired at various granular level like: table level, row/record level, page level or any other resource’s level. In transaction system a transaction can lock a whole table, or a specific row while performing some changes on it. This lock acquiring when done by various transactions simultaneously, this phenomena is called as multiple granularity locking.
Optimistic Concurrency Control Methods
Below are four Optimistic Concurrency Control Methods:
Timestamp Based (OCC)
In a timestamp based concurrency technique, each transaction in the system is assigned a unique timestamp which is taken as soon as the transaction begins, and its verified again during the commit phase. If there’s new updated timestamp from a different transaction then based on some policy defined by the System Adminstrator the transaction will either be restarted or aborted. But if the times stamp is same & never modified by any other transaction then it will be committed.
Example: Let’s say we have two transaction T1 and T2, they operate on data item – A. The Timestamp concurrency technique will keep track of the timestamp when the data was accessed by transaction T1 first time.
|
Transaction
|
Data item and operation
|
Most_recent_Timestamp
|
Initial_timestamp of data item (A)
|
|
T1
|
Read(A)
|
12:00PM
|
12:00PM
|
|
T2
|
Write(A)
|
12:15PM
|
12:00PM
|
|
T1
|
Write(A)
|
12:30PM
|
12:00PM
|
Now, let’s say this transaction T1 is about to commit, before committing, it will check the initial timestamp with the most recent timestamp. In our case, the transaction T1 won’t be committed because a write operations by transaction T2 was performed.
if(Initial_timestamp == Most_recent_timestamp)
then ‘Commit’
else
‘Abort’
In our case, transaction will be aborted because T2 modified the same data item at 12:15PM.
Multi-Version Concurrency Control (MVCC)
In MVCC, every data item has multiple versions of itself. When a transaction starts, it reads the version that is valid at the start of the transaction. And when the transaction writes, it creates a new version of that specific data item. That way, every transaction can concurrently perform their operations.
Example: In a banking system two or more user can transfer money without blocking each other simultaneously.
A similar technique to this is : Immutable Data Structures. Every time a transaction performs a new operation, new data item will be created so that way transactions do not have to worry about consistency issues.
Snapshot Isolation
Snapshot isolation is basically a snapshot stored in an isolated manner when our database system was purely consistent. And this snapshot is read by the transactions at the beginning. Transaction ensures that the data item is not changed while it was executing operations on it. Snapshot isolation is achieved through OCC & MVCC techniques.
Conflict Free Replicated Data Types (CRDTs)
CRDTs is a data structure technique which allows a transaction to perform all its operation and replicate the data to some other node or current node. After all the operations are performed, this technique offers us with merging methods that allows us to merge the data across distributed nodes (conflict-free) and eventually achieving consistent state (eventually consistent property).
Conclusion
The above mentioned concurrency methods are applicable in various scenarios. These methods help us maintain consistency, data integrity, improve reliability & maintain the proper flow of execution across different nodes in a distributed environment system where multiple transactions are executed simultaneously.
- Concurrency control is a mechanism put in place to take care of concurrent transaction execution.
- There are 2 types of concurrency mechanism: Pessimistic Concurrency control methods, that are applicable for ACID database and the Optimistic Concurrency control methods, applicable for BASE database.
- These methods help us achieve a level of isolation, between concurrently executing transactions so they do not interfere with each other.
- The locking mechanism is one of the foundations of these methods that allows them to acquire a lock on the resource before performing any operation.
FAQs on Concurrency Control in Distributed Transactions
Q.1: How does concurrency control handle system failure ?
Answer:
The system is resilient to failure because of concurrency methods for example if the system encounters node failure or network issue then the concurrency methods will either abort the transaction or commit them on restart by reading the logs ensuring data consistency.
Q.2: Is it appropriate to use “WITH NOLOCK” on a table in distributed system ?
Answer:
WITH NOLOCK is a functionality provided to override, the default isolation levels. In a distributed environment, it may not be relevant to use it because of multiple nodes performing various different transaction execution.
Q.3: Can concurrency control guarantee “Serializability” ?
Answer:
Yes, Concurrency control methods guarantee seriablizability while allowing concurrent execution of transactions, all the while maintaining data consistency by provisioning data access control in such a way that each transaction is executed serially.
Share your thoughts in the comments
Please Login to comment...