CAPTCHA, reCAPTCHA and Related Things
Last Updated :
21 Apr, 2020
The word CAPTCHA stands for the Completely Automated Public Turing test to tell Computers and Humans Apart How many of you’ve got had to fill out some kind of web form where you have been asked to read a distorted sequence of characters as shown below
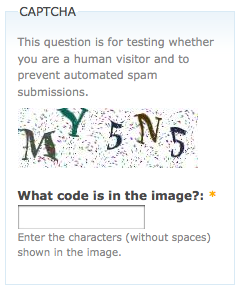
How many of you found it annoying? Luis von Ahn invented the term called a CAPTCHA and the reason is it’s there is to make sure that you, the entity filling out the form, are a human, and not some sort of computer program written to submit the form millions of times. For example, in the case of Ticketmaster, the reason you have to type these distorted characters is to prevent scalpers to write a program that can buy millions of tickets at a time.
This project was something that Luis von Ahn, Manuel Blum, Nicholas J. Hopper, and John Langford did at Carnegie Mellon about ten years ago and is used everywhere. Then they did a project after a few years later, which is sort of the next evolution of captchas. This is the project that they called reCAPTCHA, which is something that they started there at Carnegie Mellon, then they turned it into a start-up company, and then about a year and a half ago, Google acquired this company. To know how to generate a CAPTCHA, please refer Program to generate CAPTCHA and verify user.
Problem with CAPTCHA and Evolution of reCAPTCHA
This project started with the subsequent realization that it seems that approximately 200 million captchas are typed a day by people around the world. So, here’s the thing that whenever you type a captcha, essentially, you waste 10 seconds of some time and if you multiply that by 200 million you get that humanity as an entire is wasting about 500,000 hours a day typing these annoying captchas. Even, we can’t get rid of captchas, as the security of the web sort of depends on them.
But then Luis von Ahn and his team started thinking that “Is there any way in which they can use this effort for something good for Humanity?” Suppose a person is typing a captcha, during those 10 seconds, his brain is doing something amazing that computers cannot do. So, nowadays while a human being is typing a captcha not only he is authenticating himself as a human but also, he is helping them to digitize books.
reCAPTCHA(reversed CAPTCHA)
A lot of projects try to digitize books. Google has one, the web archive has one, Amazon, with the Kindle, is trying to digitize books. The way it works is, you start with a book, and then you scan it. Scanning a book is like taking a digital photograph of each page of the book. It gives you a picture of each page of the book. The next step within the process is that the PC must be ready to decipher all of the words during this image. That is done using a technology called OCR(Optical Character Recognition), which takes a picture of text and tries to figure out what the text is in there. Now, the matter is that OCR isn’t perfect, especially for older books, where the ink has faded, and therefore the pages have turned yellow, OCR cannot recognize tons of the words. For things that were written quite 50 years ago, the computer even cannot recognize about 30 percent of the words. So, what they’re doing now is they’re taking all of the words that the computer cannot recognize and they’re getting people to read them and typing a captcha on the internet. So next time you type a captcha, these words that you’re typing are words that are coming from books that are being digitized that the computer could not recognize.
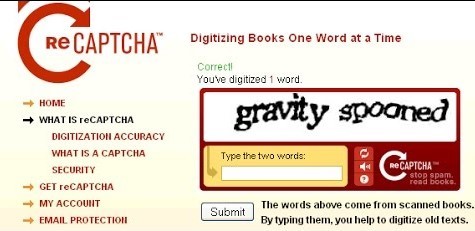
So, this is often how the system works, and since they released it about 3 or 4 years ago, tons of internet sites started switching from the old captcha, where people wasted the time, to the new captcha, where people are helping to digitize books. So, for instance, Ticketmaster, whenever you purchase tickets on Ticketmaster, you help to digitize a book. Facebook, whenever you add a friend or poke somebody you help digitize a book. About 350,000 websites are using reCAPTCHA. And actually, the amount of web sites that are using reCAPTCHA is so high that the amount of words that we’re digitizing per day is extremely large. It’s about 100 million each day, which is that the equivalent of about two and a half million books a year. And this is often all being done one word at a time by just people typing captchas on the web.
Related Things to CAPTCHA
1. No CAPTCHA reCAPTCHA: Google rolling out a replacement API that radically simplifies the reCAPTCHA experience. They’re calling it the “No CAPTCHA reCAPTCHA”. On websites using this new API, a big number of users are going to be ready to securely and simply verify they’re human without actually having to unravel a CAPTCHA. Instead, with just one click, they’ll confirm they’re not a robot. And this is how it looks:
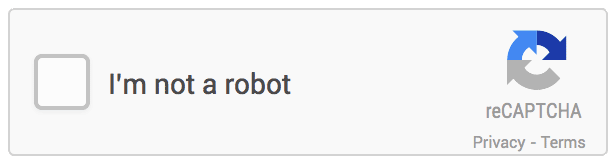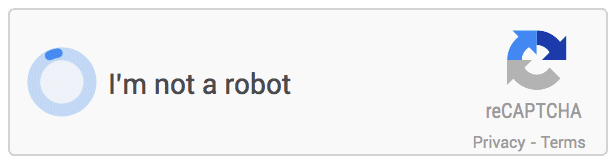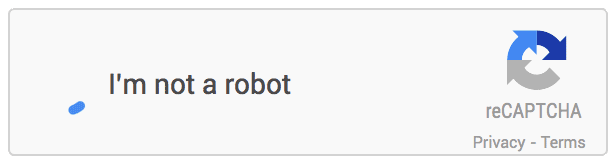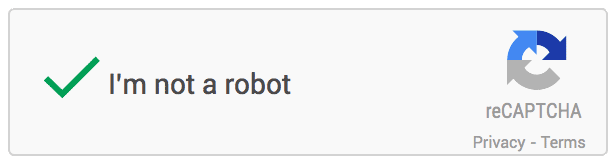
2. SQUIGL-PIX: To solve this CAPTCHA, a user has got to read and understand an instruction written in natural language. A user has to understand what to trace, then find an object on one of the given pictures and trace it. If he/she traces the right object, we may say that the instructions had been understood properly. And this is how it looks:

3. ESP-PIX: Instead of typing letters, you can authenticate yourself as a person by recognizing what object is common during a set of images. This was the primary example of a CAPTCHA supported image recognition. And this is how it looks:

Applications of CAPTCHAs:
- Preventing Comment Spam in Blogs.
- Protecting Email Addresses From Scrapers.
- Protecting Website Registration.
- Preventing Dictionary Attacks.
- Worms and Spam.
- Search Engine Bots.
- Online Polls.
Share your thoughts in the comments
Please Login to comment...