What Is Cross-Entropy Loss Function?
Last Updated :
03 Jan, 2024
Cross-entropy loss also known as log loss is a metric used in machine learning to measure the performance of a classification model. Its value ranges from 0 to 1 with lower being better. An ideal value would be 0. The goal of an optimizer tasked with training a classification model with cross-entropy loss would be to get the model as close to 0 as possible. In this article, we will delve into binary and multiclass cross-entropy losses and how to interpret
the cross-entropy loss function.
What is Cross Entropy Loss?
In machine learning for classification tasks, the model predicts the probability of a sample belonging to a particular class. Since each sample can belong to only a particular class, the true probability value would be 1 for that particular class and 0 for the other class(es). Cross entropy measures the difference between the predicted probability and the true probability.
The Cross-Entropy Loss is derived from the principles of maximum likelihood estimation when applied to the task of classification. Maximizing the likelihood is equivalent to minimizing the negative log-likelihood. In classification, the likelihood function can be expressed as the product of the probabilities of the correct classes:
Binary Cross-Entropy Loss and Multiclass Cross-Entropy Loss are two variants of cross-entropy loss, each tailored to different types of classification tasks. Let us see them in detail.
Binary Cross Entropy Loss
Binary Cross-Entropy Loss is a widely used loss function in binary classification problems. For a dataset with N instances, the Binary Cross-Entropy Loss is calculated as:

- where
- yi – truel label for instance i
- pi – predicted probability, for instance, i by the model
Multiclass Cross Entropy Loss
Multiclass Cross-Entropy Loss, also known as categorical cross-entropy or softmax loss, is a widely used loss function for training models in multiclass classification problems. For a dataset with N instances, Multiclass Cross-Entropy Loss is calculated as

- where
- C is the number of classes.
- yi,j are the true labels for class j for instance i
- pi,j is the predicted probability for class j for instance i
Why not MCE for all cases?
A natural question that comes to mind when studying the cross-entropy loss is why we don’t use cross entropy loss for all cases. This is because of the way the outputs are stored for these two tasks.
In binary classification, the output layer utilizes the sigmoid activation function, resulting in the neural network producing a single probability score (p) ranging between 0 and 1 for the two classes.
The unique approach in binary classification involves not encoding binary predicted values as different for class 0 and class 1. Instead, they are stored as single values, which efficiently saves model parameters. This decision is motivated by the notion that, for a binary problem, knowing one probability implies knowledge of the other. For instance, consider a prediction of (0.8, 0.2); it suffices to store the 0.8 value, as the complementary probability is inherently 1 – 0.8 = 0.2. On the other hand, in multiclass classification, the softmax activation is employed in the output layer to obtain a vector of predicted probabilities (p).
Consequently, the standard definition of cross-entropy cannot be directly applied to binary classification problems where computed and correct probabilities are stored as singular values.
How to interpret Cross Entropy Loss?
The cross-entropy loss is a scalar value that quantifies how far off the model’s predictions are from the true labels. For each sample in the dataset, the cross-entropy loss reflects how well the model’s prediction matches the true label. A lower loss for a sample indicates a more accurate prediction, while a higher loss suggests a larger discrepancy.
- Interpretability with Binary Classification:
- In binary classification, since there are two classes (0 and 1) it is start forward to interpret the loss value,
- If the true label is 1, the loss is primarily influenced by how close the predicted probability for class 1 is to 1.0.
- If the true label is 0, the loss is influenced by how close the predicted probability for class 1 is to 0.0.
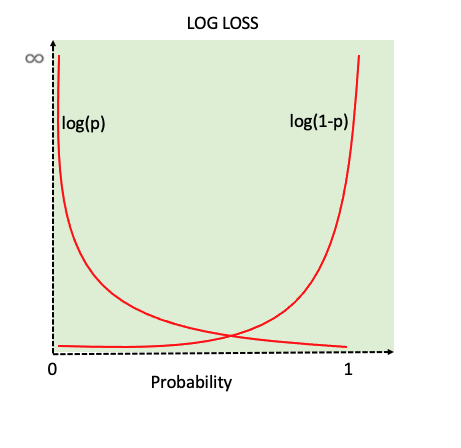
Binary Cross Entropy Loss for a single instance
- Interpretability with Multiclass Classification:
- In multiclass classification, only the true label contributes towards the loss as for other labels being zero does not add anything to the loss function.
- Lower loss indicates that the model is assigning high probabilities to the correct class and low probabilities to incorrect classes.
Key features of Cross Entropy loss
- Probabilistic Interpretation: Cross-entropy loss encourages the model to output predicted probabilities that are close to the true class probabilities.
- Gradient Descent Optimization: The mathematical properties of Cross-Entropy Loss make it well-suited for optimization algorithms like gradient descent. The gradient of the loss concerning the model parameters is relatively simple to compute.
- Commonly Used in Neural Networks: Cross-Entropy Loss is a standard choice for training neural networks, particularly in the context of deep learning. It aligns well with the softmax activation function and is widely supported in deep learning frameworks.
- Ease of Implementation: Comparison Implementing Cross-Entropy Loss is straightforward, and it is readily available in most machine learning libraries.
Comparison with Hinge loss
The main difference between hinge loss and cross-entropy loss lies in their underlying principles from which they are derived.
|
Aims to maximize the margin between the decision boundary and the data points.
| Focuses on modeling the probability distribution of the classes and aims to maximize the likelihood of the correct class.
|
The margin is the gap between the decision boundary and the nearest data point of any class.
| The probability is the model’s prediction of the data point belonging to a particular class.
|
Encourages the model to make predictions with scores that are well-separated for correctly classified instances.
| Encourages the model to output probabilities that align with the true distribution of classes.
|
Implementation
We can implement the Binary Cross-Entropy Loss using Pytorch library ‘torch.nn.BCEloss’
- torch.nn.BCELoss is suitable for binary classification problems and is commonly used in PyTorch for tasks where each input sample belongs to one of two classes.
- The inputs to torch.nn.BCELoss are the predicted probabilities and the target labels.
- The predicted probabilities should be a tensor of shape (batch_size, 1)
- The target labels should be either 0 or 1.
Python3
import torch
import torch.nn as nn
import torch.optim as optim
class Net(nn.Module):
model = Net()
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for inputs, targets in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(torch.sigmoid(outputs), targets)
loss.backward()
optimizer.step()
|
We can implement the Multi-class Cross-Entropy Loss using Pytorch library ‘torch.nn.CrossEntropyLoss’
- torch.nn.CrossEntropyLoss combines the functionalities of the softmax activation and the negative log-likelihood loss.
- The input to this loss function is typically raw output scores from the last layer of a neural network, without applying an explicit activation function like softmax. It expects the raw scores (logits) for each class.
- Internally, CrossEntropyLoss applies the softmax activation function to the raw scores before computing the loss. This ensures that the predicted values are transformed into probabilities, and the sum of probabilities for all classes is equal to 1.
- CrossEntropyLoss supports the use of class weights to handle class imbalance.
- The targets should contain class indices (integers) for each input sample, and the number of classes should match the number of output neurons in the last layer of the network.
Python3
import torch
import torch.nn as nn
import torch.optim as optim
class Net(nn.Module):
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for inputs, targets in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
|
Conclusion
In the article, we saw what cross-entropy loss is, how cross-entropy loss is calculated, how to interpret cross-entropy loss, and how it is different from hinge loss.
Frequently Asked Questions (FAQs)
1. Can Cross-Entropy Loss Be Used in Regression Tasks?
Cross-Entropy Loss is primarily designed for classification tasks and is not suitable for regression. For regression tasks, other loss functions like Mean Squared Error are more appropriate.
Can Cross-Entropy Loss Handle Imbalanced Classes?
Cross-Entropy Loss can be sensitive to imbalanced classes, and there are variants like weighted cross-entropy that assign different weights to different classes to address this issue.
2. How Does Cross-Entropy Loss Compare to Other Loss Functions?
Cross-Entropy Loss is often compared to other loss functions like Mean Squared Error (MSE) or Hinge Loss. The choice depends on the nature of the problem, the desired model behavior, and the type of output.
Share your thoughts in the comments
Please Login to comment...