In SQL (Structured Query Language), the distinction between UNION and UNION ALL holds significant importance. These operators are used to combine the results of two or more SELECT queries. UNION eliminates duplicate rows from the combined result set, presenting unique records, while UNION ALL remains all rows, including duplicates.
In this article, We will learn about the UNION and UNION ALL in SQL along with their examples and their differences, and so on.
UNION Operator
UNION Operator in SQL is used to combine the set of one or more SELECT statements as the resulting. The UNION operator removes duplicates from the combined result from the set of SELECT statements.
The conditions for a UNION statement are that the columns in the SELECT statement need to be in the same order, and the data types should be compatible. It is important to match the number of columns and their data types across different SELECT statements.
Syntax:
SELECT column1, column2, column3
FROM table1
UNION
SELECT column1, column2, column3
FROM table2;
Explanation: In the Above query, It combines the results of two SELECT statements using the UNION operator. It retrieves data from columns “column1,” “column2,” and “column3” from both “table1” and “table2,” eliminating duplicate rows from the result set.
UNION ALL Operator
UNION ALL operator in SQL is also used to combine the set of one or more select statements as the result. The difference between UNION and UNION ALL is that in the UNION ALL operator there are duplicates in the result sets of SELECT statements whereas in the UNION operator, there are no duplicate values. The UNION ALL is faster than the UNION statement because in UNION ALL there is no additional step of eliminating duplicates.
Syntax:
SELECT column1, column2, column3
FROM table1
UNION ALL
SELECT column1, column2, column3
FROM table2;
Explanation: In the Above query, It combines the results of two SELECT statements using the UNION ALL operator. It retrieves columns “column1,” “column2,” and “column3” from “table1” and appends the same columns from “table2” to the result set.
Examples of UNION and UNION ALL Operator
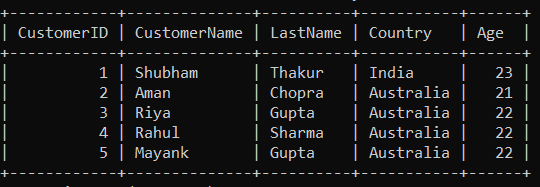
To understand the UNION and UNION ALL Operator, We meed some table on which we will perform various operations. Here we have two table called Customer which consists of CustomerID, CustomerName, LastName, Country, Age as Columns. After inserting some data into the Customer Table, the table looks like:

Customer Table
Examples of UNION Operator
Example 1: Twice Fetch and Combine Record for employees whose CustomerID lie between 1 and 5
Let’s retrieve and combine rows with CustomerID between 1 and 5 from the “customer” table using the UNION operator. However, it repeats the same SELECT statement for the second part of the UNION. As UNION does not duplicate values so only rows from 1 to 5 are fetched.
Query:
SELECT ∗ FROM customer
WHERE CustomerID between 1 and 5
UNION
SELECT ∗ from customer
WHERE CustomerID between 1 and 5;
Output:
Output of Union Example 1
Explanation:
- The first SELECT statement retrieves all columns (*) from the customer table where the CustomerID is between 1 and 5.
- As the first statement is identical to the second one, so it will retrive all columns from the customer table where the CustomerID is between 1 and 5.
- The UNION operator is used to combine the result sets of the two SELECT statements. UNION includes all rows, excluding duplicates, from both result sets.
- The output will be a combined result set of rows from the customer table where CustomerID is between 1 and 5, but it will not contain the duplicate rows from the two SELECT statement.
Example 2: Fetch and Combine Record for Employees Whose CustomerID lie between 1 to 5 and 3 to 10
Le’s retrieves and combines rows with CustomerID between 1 and 5 in the first SELECT statement and between 3 and 10 in the second SELECT statement from the “customer” table using the UNION operator. The query provide a unique result set containing distinct rows based on the conditions.
Query:
SELECT ∗ FROM customer
WHERE CustomerID between 1 and 5
UNION
SELECT ∗ FROM customer
WHERE CustomerID between 3 and 10;
Output:

Output of UNION Example 2
Explanation: The final output will contain, an overlap between the ranges specified in the two SELECT statements (from 3 to 5). This means that any customer with a CustomerID between 3 and 5 will appear in both result sets. However, since the UNION operator is used (instead of UNION ALL), duplicate rows will be removed from the final result set.
Examples of UNION ALL Operator
Example 1: Twice Fetch and Combine Record for employees whose CustomerID lie between 1 and 5
Let’s retrieves rows with CustomerID between 1 and 5 from the “customer” table and combines them with duplicate rows using the UNION ALL operator. The result set fetch all rows meeting the specified conditions, allowing duplicates in the output.
Query:
SELECT ∗ FROM customer
WHERE CustomerID between 1 and 5
UNION ALL
SELECT ∗ FROM customer
WHERE CustomerID between 1 and 5;
Output:

Output of UNION ALL Example 1
Explanation:
- The first SELECT statement retrieves all columns (*) from the customer table where the CustomerID is between 1 and 5.
- As the first statement is identical to the second one, so it will retrive all columns from the customer table where the CustomerID is between 1 and 5.
- The UNION ALL operator is used to combine the result sets of the two SELECT statements. UNION ALL includes all rows, including duplicates, from both result sets.
- The output will be a combined result set of rows from the customer table where CustomerID is between 1 and 5, with potential duplicates if any rows satisfy the conditions in both SELECT statements.
Example 2: Fetch and Combine Record for Employees Whose CustomerID lie between 1 to 5 and 4 to 10
In this example the row from 1 to 5 is printed and repeating row 4 and 5 again, row 4 to 10 is printed.
Let’s retrieves rows with CustomerID between 1 and 5 from the “customer” table and combines them with rows having CustomerID between 4 and 10, including duplicates, using the UNION ALL operator.
QUERY:
SELECT ∗ FROM customer
WHERE CustomerID between 1 and 5
UNION ALL
SELECT ∗ from customer
WHERE CustomerID between 4 and 10;
Output:

Output of UNION ALL Example 2
Explanation: The final output will contain, an overlap between the ranges specified in the two SELECT statements (from 4 to 5). This means that any customer with a CustomerID between 4 and 5 will appear in both result sets.
Difference Between UNION and UNION ALL
UNION and UNION ALL both are use to combine the result of two select command, but there is difference in both union and union all. The key difference are discussed a blow:
|
Duplication Handling
|
The UNION removes duplicate rows from the result set, presenting only unique records.
|
The UNION ALL remains all rows, including duplicates, without any elimination.
|
|
Performance Impact
|
The UNION involves the additional step of identifying and eliminating duplicates, potentially impacting performance.
|
The UNION ALL generally performs faster, as it does not have the overhead of duplicate removal.
|
|
Result Set Structure
|
The UNION creates a distinct result set with unique records.
|
The UNION ALL produces a result set that includes all rows from the combined queries.
|
|
Syntax
|
The syntax for both UNION and UNION ALL is similar, with the key difference lying in the choice of the operator.
|
The syntax for both UNION and UNION ALL is similar, with the key difference lying in the choice of the operator.
|
|
Use Case
|
The UNION is suitable when the emphasis is on unique records and the removal of duplicates is essential.
|
The UNION ALL is preferred when retaining all rows, including duplicates, is acceptable or even desired.
|
|
Data Volume
|
For large datasets, UNION may not be efficient due to its complex processing with duplicate checks.
|
For large datasets, UNION ALL may be more efficient due to its simplified processing without duplicate checks.
|
|
Query Optimization
|
The UNION may involve additional processing to identify and eliminate duplicates, potentially leading to a longer execution time.
|
The UNION ALL, being less restrictive, may result in quicker query execution.
|
|
Resource Utilization
|
The UNION consumes additional resources to identify and remove duplicate rows, impacting memory usage.
|
The UNION ALL is generally more resource-efficient as it bypasses the duplicate elimination step.
|
|
Compatibility
|
Both UNION and UNION ALL are widely supported across various relational database management systems (RDBMS).
|
Both UNION and UNION ALL are widely supported across various relational database management systems (RDBMS).
|
|
Consideration for Result Accuracy
|
If eliminating duplicates is crucial for the accuracy of the result set, then UNION is the appropriate choice.
|
When duplicate records are acceptable or necessary, and performance is a priority, UNION ALL is the preferred option.
|
Conclusion
Aftre reading whole article, Now you have good understanding UNION and UNION ALL Operator along with their examples and differences also. The UNION removes duplicate rows from the result set while the UNION ALL remains all rows, including duplicates, without any elimination. Also Both UNION and UNION ALL are widely supported across various relational database management systems (RDBMS).
Share your thoughts in the comments
Please Login to comment...