Understanding Auto Scaling And Load Balancing Integration In AWS
Last Updated :
26 Feb, 2024
The quantity of computational resources, such as Amazon EC2 instances, is automatically scaled according to changes in demand or predetermined parameters under auto-scaling. It helps guarantee that you have the suitable ability to deal with the responsibility for your application without over- or under-provisioning, which can bring about asset waste or execution issues.
Among the main attributes of auto-scaling are
Utilizing estimations like computer processor usage, network traffic, or custom measurements, scaling strategies can be characterized that determine when to scale in or out.
- Planned Scaling: Program exercises are to be done at foreordained spans.
- Dynamic scaling: This is the process of naturally adjusting the ability to fulfill fluctuating needs.
Integration with AWS Services: To convey approaching traffic, Auto Scaling associates with Versatile Burden Adjusting (ELB), among other AWS administrations

Load balancing
To keep any one case from becoming over-burden, load adjusting partitions approaching application traffic similarly among a few targets, (for example, EC2 occurrences, compartments, or IP addresses). This improves your application’s adaptability, accessibility, and adaptation to internal failure.
AWS provides a range of load balancer types
- The Classic Load Balancer (CLB) is a fundamental load balancer that coordinates traffic as per network-level or application-level information.
- High level substance based directing is made conceivable by the Application Load Balancer (ALB), what capabilities at the application layer.
- Network Load Balancer (NLB): Offers low inactivity and very elite execution load adjusting at the organization level.
Important aspects of load balancing consist of:
- Health Checks: This feature automatically determines an instance’s state of health and routes traffic exclusively to healthy instances.
- SSL/TLS Termination: To offload encryption and decryption from backend instances, SSL/TLS connections are terminated at the load balancer.
- Routing based on paths (for ALB): Uses the URL path to determine which backend services to route requests to.

The following actions are commonly involved in integrating auto scaling and load balancing in AWS
- Create an Auto Scaling Group (ASG): Lay out the circumstances, like the base, wanted, and greatest number of cases, for your assortment. A send off format or send off design with the occurrence type, AMI, and other data ought to be connected.
- Create a Load Balancer: Depending on your application’s requirements, select the appropriate load balancer (CLB, ALB, or NLB). Set up target gatherings (for ALB/NLB), audience members, and wellbeing checks.
- Configure Auto Scaling Group with Load Balancer: Give the Auto Scaling bunch directions on which load balancer(s) to enroll occurrences with. This ensures that the heap balancer’s pool of solid targets is naturally extended to incorporate any extra examples that are conveyed by means of auto scaling.
- Establishing Scaling Policies: Lay out approaches for scaling that start exercises relying upon foreordained limits, for example, computer chip use, network traffic, or different information. Auto Scaling progressively alters the quantity of examples to oblige varieties sought after as the heap balancer courses traffic to occasions.
- Testing and Monitoring: Make that occasions are consequently added to or removed from the heap balancer depending on the situation by widely testing the combination. To maximize both efficiency and affordability, monitor your application’s performance and adjust scaling parameters as necessary.
By combining Auto Scaling and Load Balancing, you can create a robust infrastructure that is flexible and able to automatically respond to changes in demand. This will ensure high accessibility and dependability for your application running on AWS.
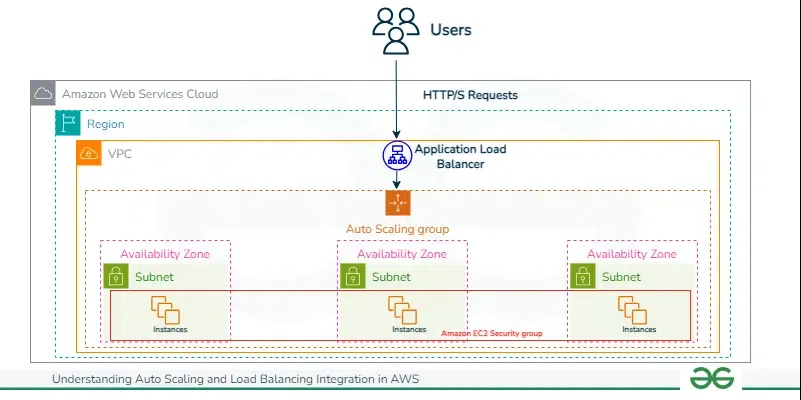
How load balancers and auto-scaling groups cooperate:
- Auto Scaling groups are set up to automatically modify the number of instances according to predetermined metrics or in reaction to variations in demand.
- In order to guarantee peak performance and availability, load balancers split up incoming traffic among several instances.
- The load balancer automatically registers or deregisters instances when an Auto Scaling group launches or ends them, guaranteeing that traffic is spread equally.
Setting up load-based triggers and auto-scaling policies:
- The parameters and procedures for scaling instances are specified by auto-scaling rules. Metrics like CPU usage, network traffic, or bespoke application metrics may serve as the basis for these regulations.
- It is possible to configure triggers to start scaling operations according to preset schedules or thresholds. For Example, you can set Auto Scaling to add instances after more than five minutes of CPU consumption above 70%.
Health Checks and Auto Healing:
- Load balancers inspect an example’s wellbeing to ensure taking care of traffic is prepared.
- Auto Scaling gatherings can be set up to trade out unfortunate examples, ensuring incredible reliability and accessibility consequently.
Setting up and utilizing best practices
- To reduce latency, set up load balancers and auto scaling groups in the same availability zones.
- Utilize metrics and alerts to keep an eye on the functionality and health of your infrastructure and to initiate scalability measures as necessary.
- Employ appropriate security measures, such as SSL termination on load balancers and security groups, to safeguard your infrastructure.
The Differences between Autoscaling and Load balancing
|
Aspect
|
Autoscaling
|
Load Balancing
|
|
Purpose
|
Automatically adjusts the number of instances or resources based on demand to maintain performance and availability.
|
Distributes incoming network traffic across multiple servers to ensures optimal resource utilization and prevent overload.
|
|
Functionality
|
scales resources up or down dynamically based on predefined criteria such as CPU utilization, memory usage, or network traffic.
|
Routes incoming requests to multiple servers or instances based on defined algorithms (e.g., round-robin, least connections) to evenly distribute the workload.
|
|
Target
|
Typically used to manage the number of instances or resources within a computing environment (e.g., virtual machines, containers).
|
Primarily focuses on distributing incoming network traffic among multiple servers or instances.
|
|
Dependency
|
Dependent on metrics such as CPU usage, memory usage, or network traffic to trigger scaling actions.
|
Independent of resource usage metrics; mainly relies on predefined routing algorithms and health checks to distribute traffic.
|
|
Scale Direction
|
can scale both in an upward direction (expanding or diminishing case size) and evenly (adding or eliminating occurrences).
|
Only horizontally scales by distributing traffic across multiple instances or servers.
|
|
Elasticity
|
gives flexibility by powerfully changing assets in light of fluctuating interest, guaranteeing ideal execution and cost productivity.
|
improves accessibility and adaptation to non-critical failure by uniformly conveying traffic, yet doesn’t innately change assets in light of interest.
|
|
Resource Allocation
|
ensures efficient resource utilization by optimizing resource allocation by adding or removing instances based on workload.
|
prevents an instance or server from becoming overloaded by evenly distributing incoming requests among the available resources
|
|
Impact on Application State
|
Autoscaling might possibly affect application state in the event that occasions are added or taken out, requiring state the board techniques like meeting diligence or conveyed storage.
|
Load adjusting ordinarily doesn’t influence application state straightforwardly, as it basically centers around directing approaching solicitations without altering the application’s hidden state.
|
|
Failure Handling
|
mitigates disappointments by supplanting undesirable cases with sound ones, consequently keeping up with administration accessibility and strength.
|
Enhances fault tolerance by directing traffic away from failed or unhealthy instances, preventing disruption to the overall system.
|
|
Deployment Environment
|
utilized frequently in cloud environments with dynamically provisional resources like serverless platforms, virtual machines, and containers.
|
can be utilized in both on-premises and cloud conditions, giving adaptability in framework sending.
|
|
Cost Management
|
empowers cost advancement by scaling assets in view of genuine interest, trying not to over-arrange, and limiting inactive assets.
|
circulates traffic proficiently across accessible assets; however, it doesn’t straightforwardly influence asset provisioning or cost administration.
|
|
Complexity
|
may present intricacy in design and for the executives because of the need to characterize scaling approaches, measurements, and limits.
|
usually easier to set up and manage than autoscaling because it mostly involves setting up health checks and routing rules.
|
|
Examples
|
Amazon EC2 Auto Scaling, Google Cloud Autoscaler
|
Amazon Elastic Load Balancer, Azure Load Balancer, nginx
|
Benefits
- Increased scalability: Resources can be automatically scaled to meet changing demand.
- High availability: To avoid single points of failure, split up traffic among several instances.
- Cost optimization: Reduce overprovisioning by scaling resources according to actual demand.
Drawbacks
- Complexity: Auto Scaling and load balancing configurations can be difficult to set up and maintain, particularly for large-scale deployments.
- Possibility of going overboard: Inadequately set up scaling strategies can result in higher expenses and needless resource consumption.
- Monitoring and maintenance: To guarantee optimum performance and cost-effectiveness, routine monitoring and maintenance are necessary.
Understanding Auto Scaling and Load Balancing Integration in AWS – FAQ’s
Can I use multiple load balancers with an Auto Scaling group?
Yes, you can attach multiple load balancers to an Auto Scaling group to distribute traffic across different protocols or regions.
How quickly does Auto Scaling respond to changes in demand?
Auto Scaling can typically add or remove instances within minutes in response to scaling events or triggers.
Share your thoughts in the comments
Please Login to comment...