Types of Big Data
Last Updated :
05 Jan, 2023
2.5 quintillion bytes of data are generated every day by users. Predictions by Statista suggest that by the end of 2021, 74 Zettabytes( 74 trillion GBs) of data would be generated by the internet. Managing such a vacuous and perennial outsourcing of data is increasingly difficult. So, to manage such huge complex data, Big data was introduced, it is related to the extraction of large and complex data into meaningful data which can’t be extracted or analyzed by traditional methods.
All data cannot be stored in the same way. The methods for data storage can be accurately evaluated after the type of data has been identified. A Cloud Service, like Microsoft Azure, is a one-stop destination for storing all kinds of data; blobs, queues, files, tables, disks, and applications data. However, even within the Cloud, there are special services to deal with specific sub-categories of data.
For example, Azure Cloud Services like Azure SQL and Azure Cosmos DB help in handling and managing sparsely varied kinds of data.
Applications Data is the data that is created, read, updated, deleted, or processed by applications. This data could be generated via web apps, android apps, iOS apps, or any applications whatsoever. Due to a varied diversity in the kinds of data being used, determining the storage approach is a little nuanced.
Types of Big Data

Structured Data
- Structured data can be crudely defined as the data that resides in a fixed field within a record.
- It is type of data most familiar to our everyday lives. for ex: birthday,address
- A certain schema binds it, so all the data has the same set of properties. Structured data is also called relational data. It is split into multiple tables to enhance the integrity of the data by creating a single record to depict an entity. Relationships are enforced by the application of table constraints.
- The business value of structured data lies within how well an organization can utilize its existing systems and processes for analysis purposes.
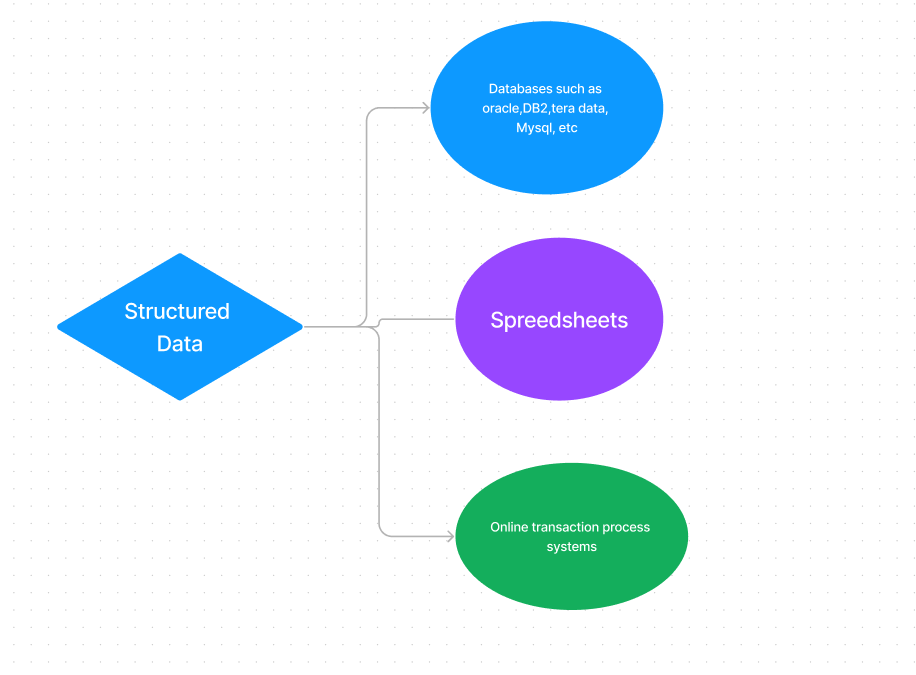
Sources of structured data
A Structured Query Language (SQL) is needed to bring the data together. Structured data is easy to enter, query, and analyze. All of the data follows the same format. However, forcing a consistent structure also means that any alteration of data is too tough as each record has to be updated to adhere to the new structure. Examples of structured data include numbers, dates, strings, etc. The business data of an e-commerce website can be considered to be structured data.
| Name |
Class |
Section |
Roll No |
Grade |
| Geek1 |
11 |
A |
1 |
A |
| Geek2 |
11 |
A |
2 |
B |
| Geek3 |
11 |
A |
3 |
A |
Cons of Structured Data
- Structured data can only be leveraged in cases of predefined functionalities. This means that structured data has limited flexibility and is suitable for certain specific use cases only.
- Structured data is stored in a data warehouse with rigid constraints and a definite schema. Any change in requirements would mean updating all of that structured data to meet the new needs. This is a massive drawback in terms of resource and time management.
Semi-Structured Data
- Semi-structured data is not bound by any rigid schema for data storage and handling. The data is not in the relational format and is not neatly organized into rows and columns like that in a spreadsheet. However, there are some features like key-value pairs that help in discerning the different entities from each other.
- Since semi-structured data doesn’t need a structured query language, it is commonly called NoSQL data.
- A data serialization language is used to exchange semi-structured data across systems that may even have varied underlying infrastructure.
- Semi-structured content is often used to store metadata about a business process but it can also include files containing machine instructions for computer programs.
- This type of information typically comes from external sources such as social media platforms or other web-based data feeds.

Semi-Structured Data
Data is created in plain text so that different text-editing tools can be used to draw valuable insights. Due to a simple format, data serialization readers can be implemented on hardware with limited processing resources and bandwidth.
Data Serialization Languages
Software developers use serialization languages to write memory-based data in files, transit, store, and parse. The sender and the receiver don’t need to know about the other system. As long as the same serialization language is used, the data can be understood by both systems comfortably. There are three predominantly used Serialization languages.

1. XML– XML stands for eXtensible Markup Language. It is a text-based markup language designed to store and transport data. XML parsers can be found in almost all popular development platforms. It is human and machine-readable. XML has definite standards for schema, transformation, and display. It is self-descriptive. Below is an example of a programmer’s details in XML.
XML
<ProgrammerDetails>
<FirstName>Jane</FirstName>
<LastName>Doe</LastName>
<CodingPlatforms>
<CodingPlatform Type="Fav">GeeksforGeeks</CodingPlatform>
<CodingPlatform Type="2ndFav">Code4Eva!</CodingPlatform>
<CodingPlatform Type="3rdFav">CodeisLife</CodingPlatform>
</CodingPlatforms>
</ProgrammerDetails>
|
XML expresses the data using tags (text within angular brackets) to shape the data (for ex: FirstName) and attributes (For ex: Type) to feature the data. However, being a verbose and voluminous language, other formats have gained more popularity.
2. JSON– JSON (JavaScript Object Notation) is a lightweight open-standard file format for data interchange. JSON is easy to use and uses human/machine-readable text to store and transmit data objects.
Javascript
{
"firstName": "Jane",
"lastName": "Doe",
"codingPlatforms": [
{ "type": "Fav", "value": "Geeksforgeeks" },
{ "type": "2ndFav", "value": "Code4Eva!" },
{ "type": "3rdFav", "value": "CodeisLife" }
]
}
|
This format isn’t as formal as XML. It’s more like a key/value pair model than a formal data depiction. Javascript has inbuilt support for JSON. Although JSON is very popular amongst web developers, non-technical personnel find it tedious to work with JSON due to its heavy dependence on JavaScript and structural characters (braces, commas, etc.)
3. YAML– YAML is a user-friendly data serialization language. Figuratively, it stands for YAML Ain’t Markup Language. It is adopted by technical and non-technical handlers all across the globe owing to its simplicity. The data structure is defined by line separation and indentation and reduces the dependency on structural characters. YAML is extremely comprehensive and its popularity is a result of its human-machine readability.

YAML example
A product catalog organized by tags is an example of semi-structured data.
Unstructured Data
- Unstructured data is the kind of data that doesn’t adhere to any definite schema or set of rules. Its arrangement is unplanned and haphazard.
- Photos, videos, text documents, and log files can be generally considered unstructured data. Even though the metadata accompanying an image or a video may be semi-structured, the actual data being dealt with is unstructured.
- Additionally, Unstructured data is also known as “dark data” because it cannot be analyzed without the proper software tools.

Un-structured Data
Summary
Applications data can be classified as structured, semi-structured, and unstructured data. Structured data is neatly organized and obeys a fixed set of rules. Semi-structured data doesn’t obey any schema, but it has certain discernible features for an organization. Data serialization languages are used to convert data objects into a byte stream. These include XML, JSON, and YAML. Unstructured data doesn’t have any structure at all. All these three kinds of data are present in an application. All three of them play equally important roles in developing resourceful and attractive applications.
Share your thoughts in the comments
Please Login to comment...