SQL Query to Delete Duplicate Columns
Last Updated :
24 Feb, 2022
Through this article, we will learn how to delete duplicate columns from a database table. As we know that duplicity in our database tends to be a waste of memory space. It records inaccurate data and is also unable to fetch the correct data from the database. To remove the duplicate columns we use the DISTINCT operator in the SELECT statement as follows:
Syntax:
SELECT DISTINCT
column1, column2, ...
FROM
table1;
- DISTINCT when used in one column, uses the values in that column to evaluate duplicates.
- When there are two or more columns, it uses the combination of values in those columns to evaluate the duplicate.
Note: DISTINCT does not delete the data of the table it only removes the duplicates in the resulting table.
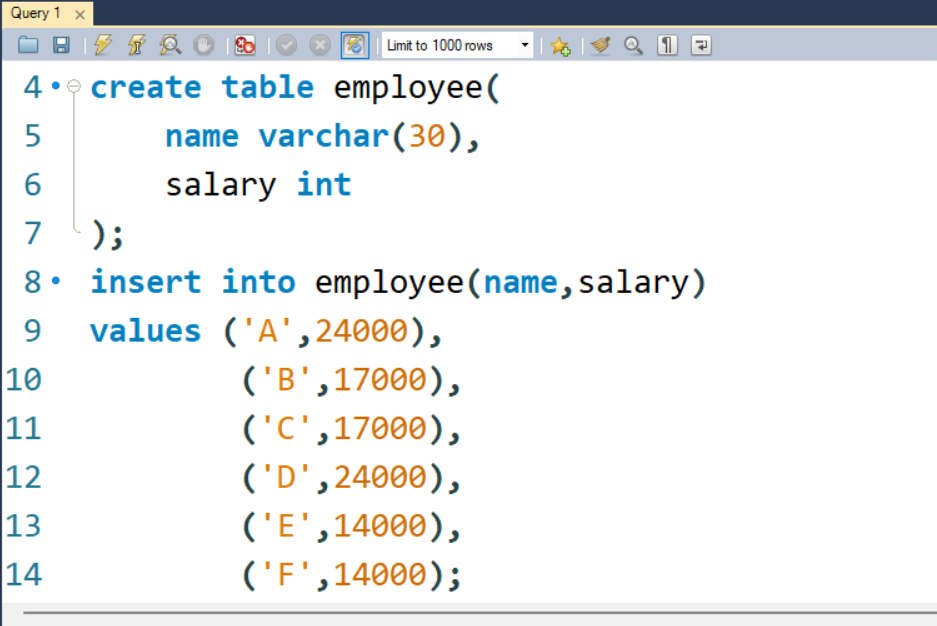
Step 1: First we have to create a table having named “employee”
Query:
CREATE TABLE employee
( name varchar(30),salary int);
Step 2: Now, we have to insert values or data in the table.
Query:
INSERT INTO employee (name,salary)
VALUES ('A',24000),
('B',17000),
('C',17000),
('D',24000),
('E',14000),
('F',14000);
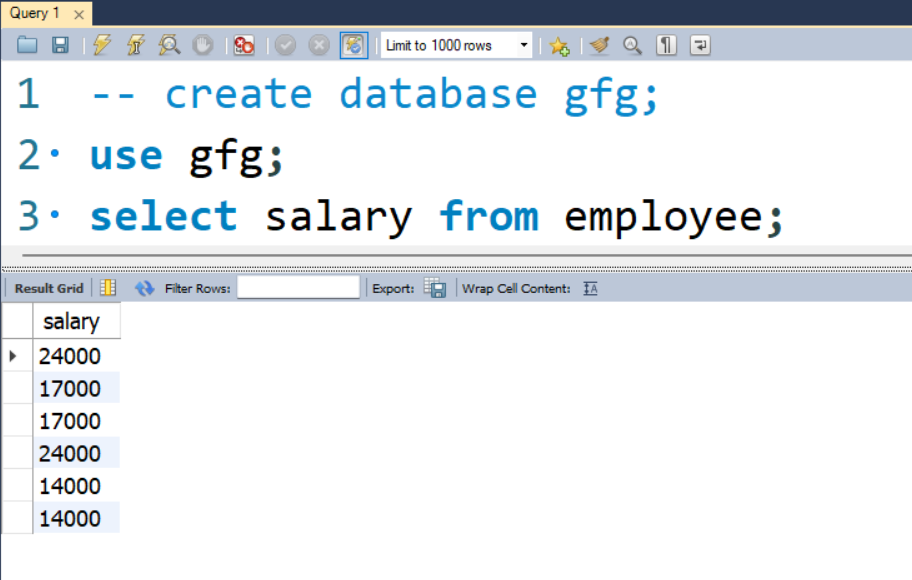
Step 3: Now we see the complete table value by using given below query.
Query:
SELECT salary FROM employee;
Output:
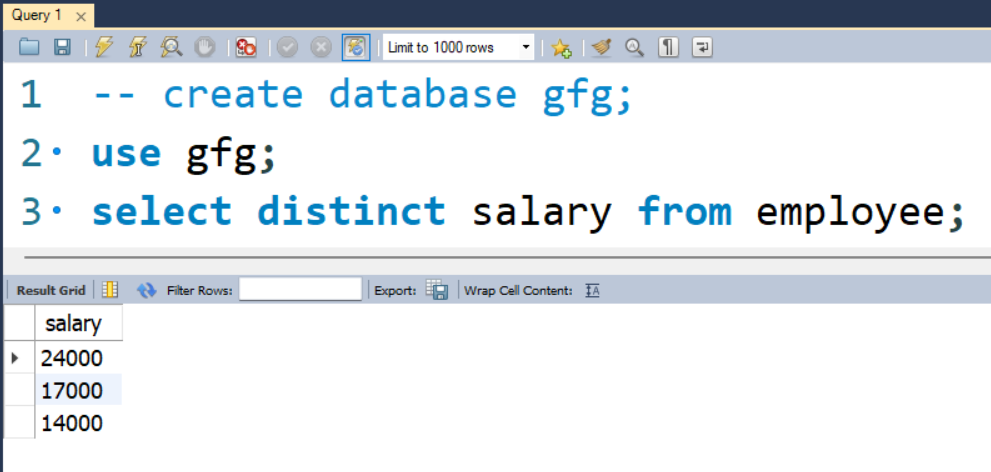
Step 4: We are using the employee table in a sample database as a sample to show DISTINCT uses.
Query:
SELECT DISTINCT salary FROM employees;
Output:
Share your thoughts in the comments
Please Login to comment...