Rule-Based Data Extraction in HTML using Python textminer Module
Last Updated :
21 Jul, 2021
While working with HTML, there are various requirements to extract data from plain HTML tags in an ordered manner in form of python data containers such as lists, dict, integers, etc. This article deals with a library that helps to achieve this using a rule-based approach.
Features of Python – textminer:
- Extracts data in form of a list, dictionary, and texts from HTML.
- Used rule-based system in YAML format.
- Supports extraction from URL in form of scraping.
Installation:
Use the below command to install Python textminer:
pip install textminer
Functions Description:
The following functions come in handy while extracting data from HTML:
Syntax:
extract(html, rule)
Parameters:
- html: The HTML to extract data from.
- rule: Rule in YAML format to apply on HTML to extract data.
Syntax:
extract_from_url(url, rule)
Parameters:
- rule: Rule in YAML format to apply on HTML to extract data.
- url: The HTML URL from which extraction of HTML has to be performed.
Example 1: Extracting data from HTML
This basic rule in YAML format is formulated to extract data between a suffix and a prefix.
Python3
import textminer
inp_html = '<html><body><div>GFG is best for Geeks</div></body></html>'
rule =
res = textminer.extract(inp_html, rule)
print("The data extracted between divs : ")
print(res)
|
Output :
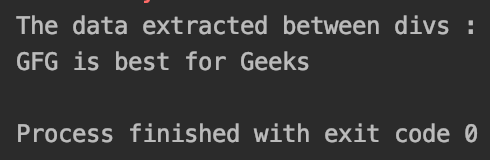
Extracted data between divs
Example 2: Extracting a list from HTML
The python-based list can be extracted from Html which is commonly referred to using list tags, by using <li> and </li> as prefix and suffix of rule. Additionally, the “list” keyword needs to be added to achieve this.
Python3
import textminer
inp_html =
rule =
res = textminer.extract(inp_html, rule)
print("The data extracted between list tags : ")
print(res)
|
Output :

Extracted list
Example 3: Extracting dictionary from HTML using defined data types.
Similar to the above example, a dictionary can be extracted using “dic” keyword, with mentioning “key” required to map key to, and value is extracted using defining prefix and suffix tags with a specific id. The data type can be mentioned using the “type” keyword.
Python3
import textminer
inp_html =
rule =
res = textminer.extract(inp_html, rule)
print("The data extracted between dictionary tags : ")
print(res)
|
Output :

Extracted Dictionary
Example 4: Extract HTML from URL
Apart from giving HTML as a string, HTML can also be provided using a url using extract_from_url().
Python3
import textminer
rule =
res = textminer.extract_from_url(target_url, rule)
print("The data extracted between title tags from url : ")
print(res)
|
Output :

Extraction from URL.
Share your thoughts in the comments
Please Login to comment...