Read Text file into PySpark Dataframe
Last Updated :
18 Jul, 2021
In this article, we are going to see how to read text files in PySpark Dataframe.
There are three ways to read text files into PySpark DataFrame.
- Using spark.read.text()
- Using spark.read.csv()
- Using spark.read.format().load()
Using these we can read a single text file, multiple files, and all files from a directory into Spark DataFrame and Dataset.
Text file Used:

Method 1: Using spark.read.text()
It is used to load text files into DataFrame whose schema starts with a string column. Each line in the text file is a new row in the resulting DataFrame. Using this method we can also read multiple files at a time.
Syntax: spark.read.text(paths)
Parameters: This method accepts the following parameter as mentioned above and described below.
- paths: It is a string, or list of strings, for input path(s).
Returns: DataFrame
Example : Read text file using spark.read.text().
Here we will import the module and create a spark session and then read the file with spark.read.text() then create columns and split the data from the txt file show into a dataframe.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataFrame").getOrCreate()
df = spark.read.text("output.txt")
df.selectExpr("split(value, ' ') as\
Text_Data_In_Rows_Using_Text").show(4,False)
|
Output:

Method 2: Using spark.read.csv()
It is used to load text files into DataFrame. Using this method we will go through the input once to determine the input schema if inferSchema is enabled. To avoid going through the entire data once, disable inferSchema option or specify the schema explicitly using the schema.
Syntax: spark.read.csv(path)
Returns: DataFrame
Example: Read text file using spark.read.csv().
First, import the modules and create a spark session and then read the file with spark.read.csv(), then create columns and split the data from the txt file show into a dataframe.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.csv("output.txt")
df.selectExpr("split(_c0, ' ')\
as Text_Data_In_Rows_Using_CSV").show(4,False)
|
Output:

Method 3: Using spark.read.format()
It is used to load text files into DataFrame. The .format() specifies the input data source format as “text”. The .load() loads data from a data source and returns DataFrame.
Syntax: spark.read.format(“text”).load(path=None, format=None, schema=None, **options)
Parameters: This method accepts the following parameter as mentioned above and described below.
- paths : It is a string, or list of strings, for input path(s).
- format : It is an optional string for format of the data source. Default to ‘parquet’.
- schema : It is an optional pyspark.sql.types.StructType for the input schema.
- options : all other string options
Returns: DataFrame
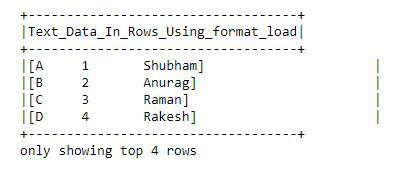
Example: Read text file using spark.read.format().
First, import the modules and create a spark session and then read the file with spark.read.format(), then create columns and split the data from the txt file show into a dataframe.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.format("text").load("output.txt")
df.selectExpr("split(value, ' ')\
as Text_Data_In_Rows_Using_format_load").show(4,False)
|
Output:
Share your thoughts in the comments
Please Login to comment...