Rank and Dense Rank in SQL Server
Last Updated :
01 Dec, 2023
The RANK() and DENSE_RANK() functions are essential tools in SQL Server for assigning rankings to rows in a dataset based on specified criteria. RANK() functions assign a unique rank to each distinct row in the result set, with tied rows receiving the same rank and leaving gaps in subsequent ranks. For example, if two rows tie for first place, the next row will receive a rank of 3.
On the other hand, DENSE_RANK() also assigns ranks based on criteria, but it does not leave gaps between ranks in case of tied rows. This means that if there are ties, the next rank will not skip any numbers. These functions are particularly useful when you need to identify the relative position of rows in a sorted dataset, which can be crucial for tasks like finding top performers or tracking trends over time. They offer valuable insights into the data and enable more sophisticated analysis and reporting.
Need for Ranking
- Ordering Results: Ranking allows you to sort the results of a query based on specific criteria. This is fundamental for presenting data in a meaningful and organized manner, making it easier for users to interpret and analyze.
- Top-N Queries: Ranking is indispensable for identifying the highest or lowest N records in a dataset according to specific conditions. This is valuable in scenarios where you need to focus on the most significant or extreme values, such as identifying top-performing products or addressing quality control issues.
- Analytical Functions: Ranking is a cornerstone of various advanced analytical functions. It serves as a foundational step for calculating percentiles, quartiles, medians, and other statistical measures. These functions provide deeper insights into the distribution and characteristics of the data.
- Handling Ties: When you have tied values (i.e., multiple records with the same value), ranking ensures that each record receives an appropriate rank. This is crucial for maintaining accuracy and fairness in scenarios where tied values must be differentiated, such as in sports competitions or financial rankings.
- Pagination: In web applications and other software, ranking is essential for implementing pagination. It allows for the efficient display of large datasets by breaking them into manageable chunks. Users can navigate through pages of results, enhancing the user experience.
These points highlight how ranking is a versatile and indispensable tool in data analysis, enabling a wide range of tasks from basic sorting to more complex statistical calculations. It forms the foundation for many advanced analytical techniques and is applicable across various industries and domains.
RANK() Function
The RANK() function in SQL Server is a tool used to assign a position or rank to each row in a result set based on specific criteria. If two or more rows share the same values according to the specified criteria, they will receive the same rank. In this scenario, the rank of the next row is incremented by the number of tied rows. For example, if two rows tie for the first position, the next row will be assigned a rank of 3, not 2. This function is particularly valuable when you need to determine the relative position of rows in a sorted dataset. It’s extensively utilized in analytical queries to gain insights and perform calculations based on these rankings.
Syntax:
RANK() OVER (PARTITION BY column1, column2, ... ORDER BY sort_column1, sort_column2, ...)
- RANK(): The function itself.
- PARTITION BY: An optional clause that divides the result set into partitions or groups. The ranking is applied within each partition separately. If omitted, the entire result set is treated as a single partition.
- ORDER BY: This clause specifies the columns by which the data is sorted to determine the ranking order.
Example:
Let’s assume we have a table called ‘Students’ with the following data. In this table, Alice has a score of 90.
|
Name
|
Score
|
|
John
|
85
|
|
Jane
|
90
|
|
Mark
|
85
|
|
Alice
|
90
|
SELECT
Name,
Score,
RANK() OVER (ORDER BY Score DESC) AS Rank
FROM
Students;
Output:

Explanation:
- Both Jane and Alice have the highest score, so they share the top rank (1), and the next rank is 3.
- John and Mark both have the same score (85), so they share rank 3. The next rank is 5.
4. DENSE_RANK() Function
The DENSE_RANK() function in SQL server serves the purpose of assigning ranks to rows in a dataset according to specific conditions. Much like the RANK() function, it orders the data based on certain criteria. However, what sets it apart is that it ensures there are no gaps between ranks in cases where multiple rows share the same values. This means that tied rows receive consecutive ranks without any interruptions. DENSE_RANK() is particularly useful when you need a continuous and unbroken sequence of ranks. It’s especially valuable in situations where you require a clear and uninterrupted ordering of data, particularly when dealing with tied values. This function is widely employed in scenarios where a seamless and sequential arrangement of data is essential for accurate analysis and reporting.
Syntax:
DENSE_RANK() OVER (PARTITION BY column1, column2, ... ORDER BY sort_column1, sort_column2, ...)
- DENSE_RANK(): The function itself.
- PARTITION BY: This optional clause divides the result set into partitions or groups, and the ranking is applied within each partition separately. If omitted, the entire result set is treated as a single partition.
- ORDER BY: This clause specifies the columns by which the data is sorted to determine the ranking order.
Example:
Let’s assume we have same table called ‘Students’ with the following data. In this table, Alice has a score of 90.
|
Name
|
Score
|
|
John
|
85
|
|
Jane
|
90
|
|
Mark
|
85
|
|
Alice
|
90
|
SELECT
Name,
Score,
DENSE_RANK() OVER (ORDER BY Score DESC) AS Dense_Rank
FROM
Students;
Output:
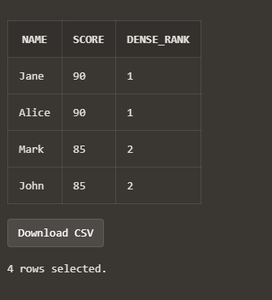
Explanation:
- Both Alice and Jane have the highest score (90), so they share the top dense rank (1).
- John and Mark both have the same score (85), so they share dense rank 2. The next dense rank is 3.
Differnce between Rank() and Dense Rank()
|
Definition
|
Assigns a unique rank to each row, leaving no gaps between ranks. If there are ties, the next rank will be skipped.
|
Assigns a unique rank to each row, leaving no gaps between ranks. If there are ties, the next rank will not be skipped.
|
|
Example
|
Data: 10, 20, 20, 30, 40 Rank: 1, 2, 2, 4, 5
|
Data: 10, 20, 20, 30, 40 Dense Rank: 1, 2, 2, 3, 4
|
|
Behavior with ties
|
Skips the next rank after a tie.
|
Does not skip the next rank after a tie.
|
|
Example with ties
|
Data: 10, 20, 20, 30, 40 Rank: 1, 2, 2, 4, 5
|
Data: 10, 20, 20, 30, 40 Dense Rank: 1, 2, 2, 3, 4
|
|
Gaps between ranks
|
Leaves gaps between ranks after ties.
|
Does not leave gaps between ranks after ties.
|
|
Example with gaps
|
Data: 10, 20, 20, 30, 40 Rank: 1, 2, 2, 4, 5
|
Data: 10, 20, 20, 30, 40 Dense Rank: 1, 2, 2, 3, 4
|
|
Effect of skipping ranks
|
May lead to non-sequential ranks.
|
Always maintains sequential ranks.
|
|
Application
|
Useful when you want to differentiate between tied values distinctly.
|
Useful when you want to maintain a sequential rank without gaps.
|
|
Syntax
|
RANK() OVER (PARTITION BY … ORDER BY …)
|
DENSE_RANK() OVER (PARTITION BY … ORDER BY …)
|
Conclusion
Rank and Dense Rank in SQL Server are powerful window functions used to assign a relative ranking to rows within a result set based on specific criteria. `RANK()` assigns a unique rank to each distinct row, potentially leaving gaps in the ranking in the case of tied values. On the other hand, `DENSE_RANK()` also assigns a unique rank to each distinct row but ensures that no gaps occur, even when ties are present. These functions are particularly useful in scenarios where you need to analyze data based on its relative position, such as identifying top performers in a competition or evaluating sales performance. Understanding the differences between these two functions allows for precise ranking strategies tailored to the specific needs of the dataset at hand.
Share your thoughts in the comments
Please Login to comment...