Python | Pandas TimedeltaIndex.drop_duplicates
Last Updated :
10 May, 2022
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas TimedeltaIndex.drop_duplicates() function return Index with duplicate values removed. The function provides the flexibility to choose which duplicate value to keep and rest to drop.
Syntax : TimedeltaIndex.drop_duplicates(keep=’first’)
Parameters : keep : {‘first’, ‘last’, False}, default ‘first’ -> first : Drop duplicates except for the first occurrence. -> last : Drop duplicates except for the last occurrence. -> False : Drop all duplicates
Return : deduplicated : Index
Example #1: Use TimedeltaIndex.drop_duplicates() function to drop all the duplicate value from the given TimedeltaIndex object. Keep the first occurrences only.
Python3
import pandas as pd
tidx = pd.TimedeltaIndex(data =['06:05:01.000030', '+23:59:59.999999',
'22 day 2 min 3us 10ns', '+23:59:59.999999',
'+23:29:59.999999', '+12:19:59.999999'])
print(tidx)
|
Output :

Now we will use the TimedeltaIndex.drop_duplicates() function to drop all the duplicate values while keeping the first occurrence.
Python3
tidx.drop_duplicates(keep ='first')
|
Output : 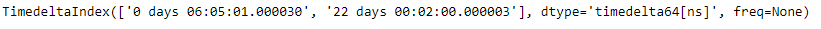
As we can see in the output, the TimedeltaIndex.drop_duplicates() function has returned a new object which has all the duplicate values removed except the first occurrence.
Example #2: Use TimedeltaIndex.drop_duplicates() function to drop all the duplicate value from the given TimedeltaIndex object. Keep the last duplicate value.
Python3
import pandas as pd
tidx = pd.TimedeltaIndex(data =['1 days 02:00:00', '1 days 06:05:01.000030',
'1 days 02:00:00', '1 days 02:00:00', '21 days 06:15:01.000030'])
print(tidx)
|
Output :

Now we will use the TimedeltaIndex.drop_duplicates() function to drop all the duplicate values while keeping the last occurrence.
Python3
tidx.drop_duplicates(keep ='last')
|
Output :

As we can see in the output, the TimedeltaIndex.drop_duplicates() function has returned a new object which has all the duplicate values removed except the last occurrence.
Share your thoughts in the comments
Please Login to comment...