Pandas read_csv: low_memory and dtype options
Last Updated :
02 Oct, 2023
By understanding and using the low_memory and dtype options effectively, we can enhance the accuracy and efficiency of our data processing tasks. Whether we are working with large datasets or dealing with columns that require custom data types, these options give us the flexibility to tailor the data reading process to our specific needs. In this article, we are going to see about Pandas read_csv: low_memory and dtype options in Python.
When to Use low_memory and dtype
Here are some guidelines on when to use the low_memory and dtype options:
- low_memory: Use low_memory=True (the default) for most cases, as it is memory-efficient and works well for most datasets. Consider setting low_memory=False when working with smaller datasets or when we suspect that the automatic data type inference is incorrect.
- dtype: Use the dtype option when we need precise control over the data types of specific columns. Specify data types when dealing with columns that contain mixed data or when we want to optimize memory usage for specific columns.
CSV File Link: nba.csv
The read_csv Function
Let’s briefly review the basics of the read_csv function.
Python3
import pandas as pd
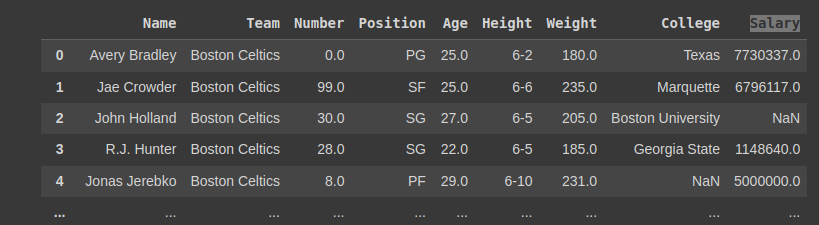
df = pd.read_csv('nba.csv')
|
Output
The low_memory option
The low_memory option is a boolean parameter that controls whether Pandas should read the CSV file in chunks or load the entire file into memory at once. By default, low_memory is set to True, which means Pandas will attempt to read the file in chunks to conserve memory.
Python3
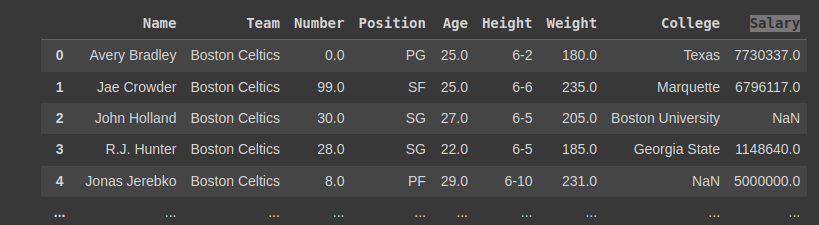
df = pd.read_csv('nba.csv', low_memory=False)
df
|
Output
The dtype option
The dtype option allows you to specify the data type of individual columns when reading a CSV file. This option is particularly useful when you want to ensure that specific columns have the correct data type, especially in cases where Pandas may misinterpret the data type during the automatic inference.
Python3
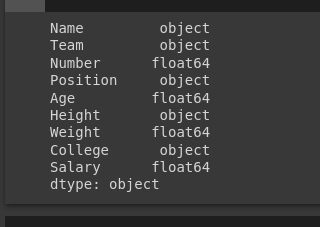
dtype_dict = {'Name': 'str', 'Number': 'float64', 'Age': 'float64'}
df = pd.read_csv('nba.csv', dtype=dtype_dict)
print(df.dtypes)
|
Output
Combining low_memory and dtype
So, when you run this code, it will read the ‘nba.csv’ file into a DataFrame, ensuring that the ‘Name’ column has a string data type, the ‘Number’ column has a float data type, and the ‘Age’ column also has a float data type. The printed output will show the data types of all columns in the DataFrame, including the ones specified in the dtype_dict dictionary.
Python3
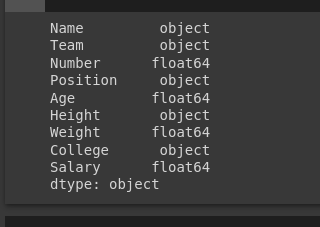
import pandas as pd
dtype_dict = {'Name': 'str', 'Number': 'float64', 'Age': 'float64'}
df = pd.read_csv('nba.csv', low_memory=True, dtype=dtype_dict)
print(df.dtypes)
|
Output
Share your thoughts in the comments
Please Login to comment...