Pandas Profiling in Python
Last Updated :
01 Sep, 2023
Pandas is a very vast library that offers many functions with the help of which we can understand our data. Pandas profiling provides a solution to this by generating comprehensive reports for datasets that have numerous features. These reports can be customized according to specific requirements. In this article, we will dive into this library’s functionalities and explore its various features like:
- Installation of Pandas Profiling
- Importing Pandas Profiling
- Generating Profile Report
- Exploring Profile Report Generated
- Overview
- Variables
- Correlations
- Missing Values
- Sample
- Saving the Profile Report
Installation of Pandas Profiling
Pandas Profiling can be easily installed using the following command
pip install pandas-profiling
The pandas_profiling library in Python includes a method named as ProfileReport() which generates a basic report on the input DataFrame.
The report consists of the following:
- DataFrame overview,
- Each attribute on which DataFrame is defined,
- Correlations between attributes (Pearson Correlation and Spearman Correlation), and
- A sample of DataFrame.
Syntax :
pandas_profiling.ProfileReport(df, **kwargs)
|
df
|
DataFrame
|
Data to be analyzed
|
|
bins
|
int
|
Number of bins in histogram. The default is 10.
|
|
check_correlation
|
boolean
|
Whether or not to check correlation. It’s `True` by default.
|
|
correlation_threshold
|
float
|
Threshold to determine if the variable pair is correlated. The default is 0.9.
|
|
correlation_overrides
|
list
|
Variable names not to be rejected because they are correlated. There is no variable in the list (`None`) by default.
|
|
check_recoded
|
boolean
|
Whether or not to check recoded correlation (memory heavy feature). Since it’s an expensive computation it can be activated for small datasets. `check_correlation` must be true to disable this check. It’s `False` by default.
|
|
pool_size
|
int
|
Number of workers in thread pool. The default is equal to the number of CPU.
|
Now, let’s take an example, we will create our own data frame and will have a look at how pandas profiling can help in understanding the dataset more. Before that let us import the pandas_profiling.
Importing Pandas Profiling
Python3
import pandas as pd
from pandas_profiling import ProfileReport
|
Now, create the data frame or import any dataset.
Python3
dct = {'ID': {0: 23, 1: 43, 2: 12, 3: 13,
4: 67, 5: 89, 6: 90, 7: 56,
8: 34},
'Name': {0: 'Ram', 1: 'Deep', 2: 'Yash',
3: 'Aman', 4: 'Arjun', 5: 'Aditya',
6: 'Divya', 7: 'Chalsea',
8: 'Akash' },
'Marks': {0: 89, 1: 97, 2: 45, 3: 78,
4: 56, 5: 76, 6: 100, 7: 87,
8: 81},
'Grade': {0: 'B', 1: 'A', 2: 'F', 3: 'C',
4: 'E', 5: 'C', 6: 'A', 7: 'B',
8: 'B'}
}
data = pd.DataFrame(dct)
print(data)
|
Output:
ID Name Marks Grade
0 23 Ram 89 B
1 43 Deep 97 A
2 12 Yash 45 F
3 13 Aman 78 C
4 67 Arjun 56 E
5 89 Aditya 76 C
6 90 Divya 100 A
7 56 Chalsea 87 B
8 34 Akash 81 B
Generating Profile Report
For generating the profile report we will simply use the Profile Report from pandas_profile and input will the dataframe.
Python3
profile = ProfileReport(data)
profile
|
Exploring the Profile Report Generated
Overview
Overview consists of 3 tabs, these are Overview, Alerts, and Reproduction.
The Overview consists of dataset statistics and variable types. Dataset statistics gives us information on number of variables, duplicates and missing values.
.png)
Overview
Next is the Alerts tab, which gives us information on the correlated variables. Also, about the unique values. Here, the data is small but if the dataset will be large then it will also tell us about missing values, skewness of data, etc.
.png)
Alerts
The Reproduction tab tells us about the start and end time of the report generation, also about the duration, software version, etc. Take a look at the below image for more clearance.

Reproduction
Variables
This section gives us information on the variables, which tells us about the type of the variable, then distinct and missing values with the memory size that the variable is taking. Let’s see the example of two variables below, id is a real number and grade is categorical.
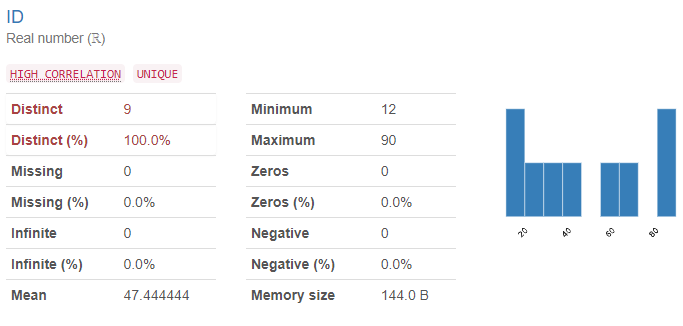
ID variable

Grade Variable
Correlations
A statistical tool that helps in the study of the relationship between two variables is known as Correlation.
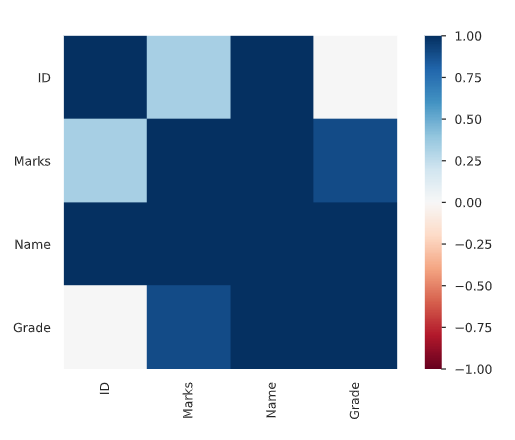
Correlation
Missing Values
The profile report also gives us information on missing values in the data visually using the bar plot.
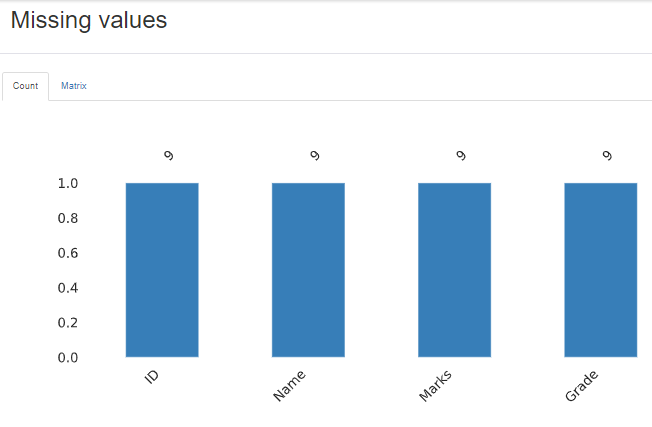
Missing Values
Sample
This displays the first and last 10 rows of the dataset.

Sample dataset
Saving the Profile Report
We can save the report in either HTML or JSON format. The code for that is shown below:
Python3
profile.to_file("output.html")
profile.to_file("output.json")
|
Share your thoughts in the comments
Please Login to comment...