Pagination in GraphQL
Last Updated :
26 Mar, 2024
Pagination in GraphQL is a powerful tool that allows developers to efficiently retrieve large amounts of data by breaking it into smaller, more manageable parts. This not only enhances the performance of data queries but also reduces the burden on servers and networks.
In this article, We will learn about Pagination along with its types also see some examples, and so on.
Pagination in GraphQL
- Pagination in GraphQL involves dividing a large amount of data into smaller, more manageable manner.
- This approach enhances the efficiency of data queries by reducing the amount of data retrieved at once.
- It allows for more efficient data retrieval, reducing the burden on the server and network.
- Pagination allows for flexibility in querying data, as it enables developers to retrieve data in parts based on specific requirements or use cases
Below are the types of Pagination in GraphQL.
- Offset Pagination
- Cursor-Based Pagination
1. Offset Pagination
- Offset pagination divides a large dataset into smaller parts for easier handling.
- It requires specifying a starting point (offset) and a limit (number of items to retrieve).
- For example, to display items 21 to 30 from a list of 100 items, set the offset to 20 and the limit to 10.
- This technique allows for navigating through a dataset by skipping a specified number of items each time to fetch the next set of results.
Let’s take an example:
Let’s Develop a GraphQL query that retrieves a subset of posts from a list of posts. The query should fetch 5 posts starting from the 11th post in the list. The query should include the “id,” “title,” and “content” fields for each post.
query GetPosts {
posts(limit: 5, offset: 10) {
id
title
content
}
}
Response:
{
"data": {
"posts": [
{
"id": "11",
"title": "Post Title 11",
"content": "Post Content 11"
},
{
"id": "12",
"title": "Post Title 12",
"content": "Post Content 12"
},
{
"id": "13",
"title": "Post Title 13",
"content": "Post Content 13"
},
{
"id": "14",
"title": "Post Title 14",
"content": "Post Content 14"
},
{
"id": "15",
"title": "Post Title 15",
"content": "Post Content 15"
}
]
}
}
Visual Represenation of the Output:
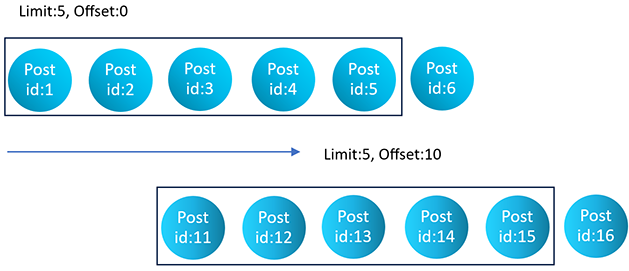
Offset Pagination
Explanation: This response would contain an array of 5 posts, starting from the 11th post in the list. Each post object includes its id, title, and content.
How Performant is Offset-Based Pagination?
While a regular offset pagination is quite simple, its advantage is that it’s I/O-intensive, and therefore the performance slows down if we work with large amounts of data. Here’s why:
- Skipping Records: Beyond random skipping, SQL databases require the server to skip a certain number of records before picking up the next set of items. For instance, if we want to load page number 5 of a list the server requires us to skip the first 4 pages’ notes. The input process adjusts slowly with progressing datasets.
- Increased Query Time: Missing from the query is enough of the data that can damage its performance. As the fraction of grabbed data gets larger, the time required to rebound the page and solidify the data also increases. This means that they will wait longer to obtain information without having a pleasant user experience.
- Server Load: An optimal self-server can also put strain on the server because the server parsing time gets longer, especially when processing queries with a large amount of data. The server is responsible for tasks such as jumping over the records and getting the requested information, which usually slows it down, and affects its general performance and responsiveness, as well.
However, the implementation of offset pagination is straightforward and it allows the user to continue exploring the sphere of unknown efficiently. yet at first sight it doesn’t seem to be that effective, especially for large datasets applications.
2. Cursor-Based Pagination
- Cursor-Based Pagination uses a unique marker known as a cursor to navigate through results.
- Each data entry has a unique cursor serving as a bookmark for different entries.
- It allows for proper structuring and relatively faster performance when dealing with large datasets that change dynamically.
- Instead of fetching by page numbers, it fetches data based on the cursor, which points to a specific entry in the dataset.
- Cursors are more efficient for navigating large datasets compared to offset pagination.
Let’s take an Example:
Let’s develop a GraphQL query to retrieve user information in a paginated manner. The query should fetch the first 5 users after a specified cursor. The query should return the user’s id, name, and email. Additionally, the query should provide metadata including the total count of users, a flag indicating if there is a next page, and the end cursor for the current page.
query GetUsers {
users(first: 5, after: "cursor123") {
edges {
cursor
node {
id
name
email
}
}
totalCount
pageInfo {
hasNextPage
endCursor
}
}
}
Response:
{
"data": {
"users": {
"edges": [
{
"cursor": "cursor1",
"node": {
"id": "1",
"name": "John Doe",
"email": "john.doe@example.com"
}
},
{
"cursor": "cursor2",
"node": {
"id": "2",
"name": "Jane Smith",
"email": "jane.smith@example.com"
}
},
...
],
"totalCount": 100,
"pageInfo": {
"hasNextPage": true,
"endCursor": "cursor50"
}
}
}
}
Explanation: The output includes an array of user objects, each with a cursor and details like id, name, and email. Additionally, metadata like the total user count, and whether there’s a next page and the end cursor is provided.
Types of Pagination Based On User’s Point of View
From the user’s point of view, pagination shows up in three main forms based on various ways users interact with paginated content on websites or applications:
- Numbered Page Implementation: As the user move through the dataset by the numbers of pages, so they navigate through them by clicking on the page numbers in this implementation. Showing up to count indicated number of items at one page is for the app’s configuration. For instance, the users in an online shopping site may be able to boost to a precise page by clicking on a specific page numbers at the bottom.
- Sequential Page Implementation: The consecutiveness of multiple pages rendering enables users to walk through the dataset using the previous and next buttons, showing next set of items by given limit. As an illustration with the browsing the news on a newspaper’s website, users are able to click on “Next” and “Previous” buttons to move between the stories like going backwards and forwards.
- Infinite Scroll Implementation: Dynamic content that is loaded continuously as we scroll down the page does not end when we reach the bottom of the screen but the other content is loaded to continue our search. It’s just like scrolling through Instagram feeds or Snapchat stories where after scrolling down we’ll be presented with new content.
Conclusion
Overall, pagination in GraphQL plays a crucial role in optimizing data retrieval and improving user experience. By implementing pagination, developers can effectively manage large datasets, reduce latency, and enhance the overall performance of their applications. Whether using offset pagination or cursor-based pagination, GraphQL provides the flexibility and efficiency needed to handle complex data querying requirements.
Share your thoughts in the comments
Please Login to comment...