This tutorial is going to provide you with a walk-through of the Gensim library.
Gensim : It is an open source library in python written by Radim Rehurek which is used in unsupervised topic modelling and natural language processing. It is designed to extract semantic topics from documents. It can handle large text collections. Hence it makes it different from other machine learning software packages which target memory processing. Gensim also provides efficient multicore implementations for various algorithms to increase processing speed. It provides more convenient facilities for text processing than other packages like Scikit-learn, R etc.
This tutorial will cover these concepts:
- Create a Corpus from a given Dataset
- Create a TFIDF matrix in Gensim
- Create Bigrams and Trigrams with Gensim
- Create Word2Vec model using Gensim
- Create Doc2Vec model using Gensim
- Create Topic Model with LDA
- Create Topic Model with LSI
- Compute Similarity Matrices
- Summarize text documents
Let us understand what some of the below mentioned terms mean before moving forward.
- Corpus: A collection of text documents.
- Vector: Form of representing text.
- Model: Algorithm used to generate representation of data.
- Topic Modelling: It is an information mining tool which is used to extract semantic topics from documents.
- Topic: A repeating group of words frequently occurring together.
For example:
You have a document which consists of words like -
bat, car, racquet, score, glass, drive, cup, keys, water, game, steering, liquid
These can be grouped into different topics as-| Topic 1 | Topic 2 | Topic 3 |
|---|
| glass | bat | car |
| cup | racquet | drive |
| water | score | keys |
| liquid | game | steering |
Some of the Topic Modelling Techniques are –
- Latent Semantic Indexing(LSI)
- Latent Dirichlet Allocation(LDA)
Now that we have the basic idea of the terminologies let’s start with the use of Gensim package.
First Install the library using the commands-
#for linux
#for anaconda prompt
Step 1: Create a Corpus from a given Dataset
You need to follow these steps to create your corpus:
- Load your Dataset
- Preprocess the Dataset
- Create a Dictionary
- Create Bag of Words Corpus
1.1 Load your Dataset:
You can have a .txt file as your dataset or you can also load datasets using the Gensim Downloader API.
Code:
python3
import os
doc = open('sample_data.txt', encoding ='utf-8')
|
- Gensim Downloader API: This is a module available in the Gensim library which is an API for downloading, getting information and loading datasets/models.
Code:
python3
import gensim.downloader as api
info_datasets = api.info()
print(info_datasets)
dataset_info = api.info("text8")
dataset = api.load("text8")
word2vec_model = api.load('word2vec-google-news-300')
|
Here we are going to consider a text file as raw dataset which consist of data from a wikipedia page.
1.2 Preprocess the Dataset
Text preprocessing: In natural language preprocessing, text preprocessing is the practice of cleaning and preparing text data. For this purpose we will use the simple_preprocess( ) function.This function returns a list of tokens after tokenizing and normalizing them.
Code:
python3
import gensim
import os
from gensim.utils import simple_preprocess
doc = open('sample_data.txt', encoding ='utf-8')
tokenized =[]
for sentence in doc.read().split('.'):
tokenized.append(simple_preprocess(sentence, deacc = True))
print(tokenized)
|
Output:
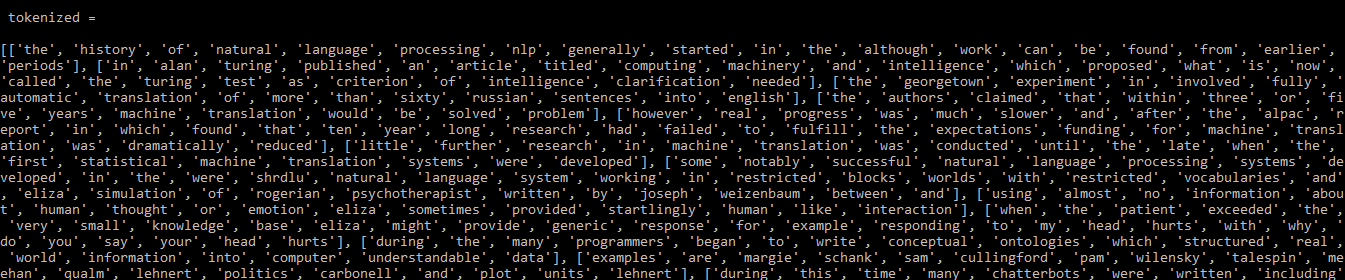
Output: tokenized
1.3 Create a Dictionary
Now we have our preprocessed data which can be converted into a dictionary by using the corpora.Dictionary( ) function. This dictionary is a map for unique tokens.
Code:
python3
from gensim import corpora
my_dictionary = corpora.Dictionary(tokenized)
print(my_dictionary)
|
Output:

my_dictionary
1.3.1 Saving Dictionary on Disk or as Text File
You can save/load your dictionary on the disk as well as a text file as mentioned below:
Code:
python3
my_dictionary.save('my_dictionary.dict')
load_dict = corpora.Dictionary.load(my_dictionary.dict')
from gensim.test.utils import get_tmpfile
tmp_fname = get_tmpfile("dictionary")
my_dictionary.save_as_text(tmp_fname)
load_dict = corpora.Dictionary.load_from_text(tmp_fname)
|
1.4 Create Bag of Words Corpus
Once we have the dictionary we can create a Bag of Word corpus using the doc2bow( ) function. This function counts the number of occurrences of each distinct word, convert the word to its integer word id and then the result is returned as a sparse vector.
Code:
python3
BoW_corpus =[my_dictionary.doc2bow(doc, allow_update = True) for doc in tokenized]
print(BoW_corpus)
|
Output:
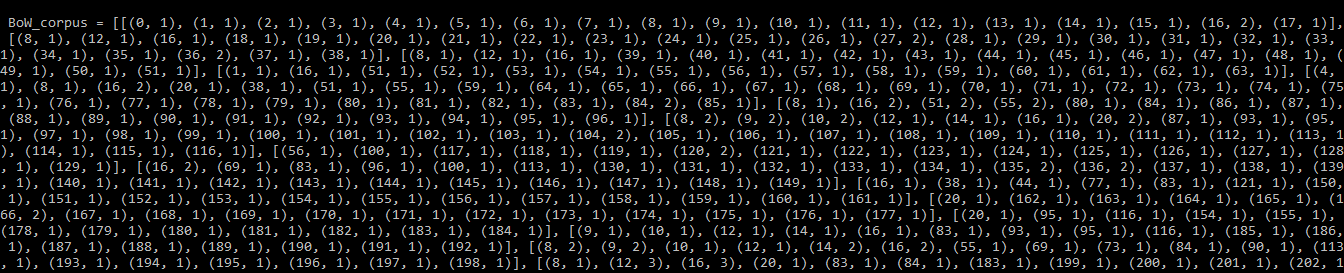
BoW_corpus
1.4.1 Saving Corpus on Disk:
Code: To save/load your corpus
python3
from gensim.corpora import MmCorpus
from gensim.test.utils import get_tmpfile
output_fname = get_tmpfile("BoW_corpus.mm")
MmCorpus.serialize(output_fname, BoW_corpus)
load_corpus = MmCorpus(output_fname)
|
Step 2: Create a TFIDF matrix in Gensim
TFIDF: Stands for Term Frequency – Inverse Document Frequency. It is a commonly used natural language processing model that helps you determine the most important words in each document in a corpus. This was designed for a modest-size corpora.
Some words might not be stopwords but may occur more often in the documents and may be of less importance. Hence these words need to be removed or down-weighted in importance. The TFIDF model takes the text that share a common language and ensures that most common words across the entire corpus don’t show as keywords. You can build a TFIDF model using Gensim and the corpus you developed previously as:
Code:
python3
from gensim import models
import numpy as np
word_weight =[]
for doc in BoW_corpus:
for id, freq in doc:
word_weight.append([my_dictionary[id], freq])
print(word_weight)
|
Output:

Word weight before applying TFIDF Model
Code: applying TFIDF model
python3
tfIdf = models.TfidfModel(BoW_corpus, smartirs ='ntc')
weight_tfidf =[]
for doc in tfIdf[BoW_corpus]:
for id, freq in doc:
weight_tfidf.append([my_dictionary[id], np.around(freq, decimals = 3)])
print(weight_tfidf)
|
Output:

word weights after applying TFIDF model
You can see that the words occurring frequently across the documents now have lower weights assigned.
Step 3: Creating Bigrams and Trigrams with Gensim
Many words tend to occur in the content together. The words when occur together have a different meaning than as individuals.
for example:
Beatboxing --> the word beat and boxing individually have meanings of their own
but these together have a different meaning.
Bigrams: Group of two words
Trigrams: Group of three words
We will be using the text8 dataset here which can be downloaded using the Gensim downloader API
Code: Building bigrams and trigrams
python3
import gensim.downloader as api
from gensim.models.phrases import Phrases
dataset = api.load("text8")
data =[]
for word in dataset:
data.append(word)
bigram_model = Phrases(data, min_count = 3, threshold = 10)
print(bigram_model[data[0]])
|

Bigram model
To create a Trigram we simply pass the above obtained bigram model to the same function.
Code:
python3
trigram_model = Phrases(bigram_model[data], threshold = 10)
print(trigram_model[bigram_model[data[0]]])
|
Output:

Trigram
The ML/DL algorithms cannot access text directly which is why we need some numerical representation so that these algorithms can process the data. In simple Machine Learning applications CountVectorizer and TFIDF are used which do not preserve the relationship between the words.
Word2Vec: Method to represent text to generate Word Embeddings which map all the words present in a language into a vector space of a given dimension. We can perform mathematical operations on these vectors which help preserve the relationship between the words.

Pre-built word embedding models like word2vec, GloVe, fasttext etc. can be downloaded using the
Gensim downloader API. Sometimes you may not find word embeddings for certain words in your document. So you can train your model.
4.1) Train the modelCode:
python3
import gensim.downloader as api
from multiprocessing import cpu_count
from gensim.models.word2vec import Word2Vec
dataset = api.load("text8")
data =[]
for word in dataset:
data.append(word)
data_1 = data[:1200]
data_2 = data[1200:]
w2v_model = Word2Vec(data_1, min_count = 0, workers = cpu_count())
print(w2v_model['time'])
|
Output:
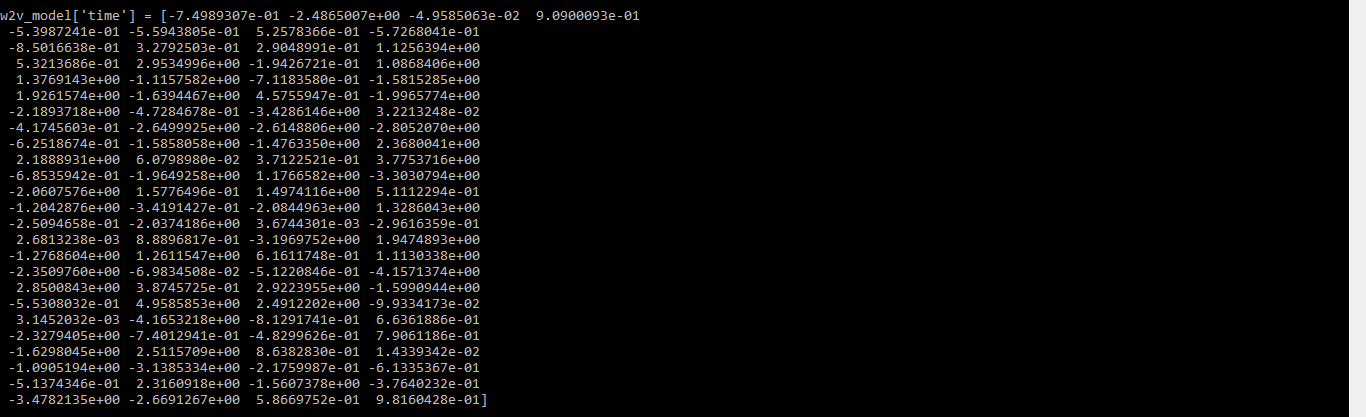
word vector for the word time
You can also use the most_similar( ) function to find similar words to a given word.
Code:
python3
print(w2v_model.most_similar('time'))
w2v_model.save('Word2VecModel')
model = Word2Vec.load('Word2VecModel')
|
Output:

most similar words to ‘time’
4.2) Update the model
Code:
python3
w2v_model.build_vocab(data_2, update = True)
w2v_model.train(data_2, total_examples = w2v_model.corpus_count, epochs = w2v_model.iter)
print(w2v_model['time'])
|
Output:
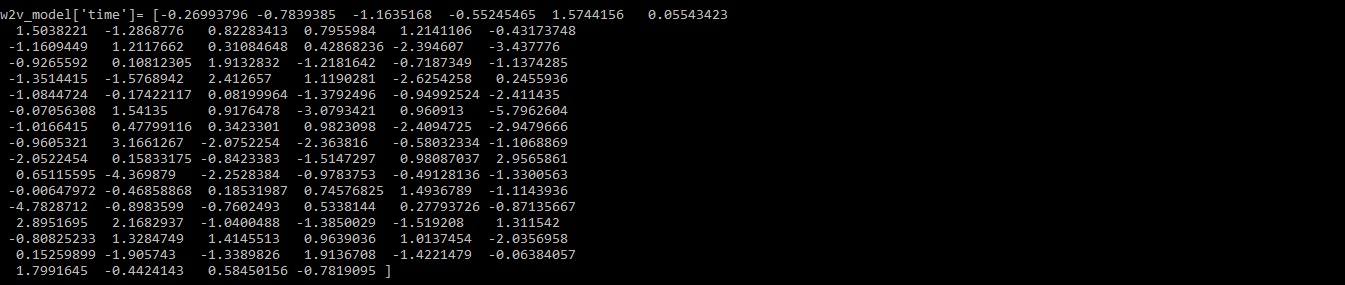
Step 5: Create Doc2Vec model using Gensim
In contrast to the Word2Vec model, the Doc2Vec model gives the vector representation for an entire document or group of words. With the help of this model, we can find the relationship among different documents such as-
If we train the model for literature such as "Through the Looking Glass".We can say that-

5.1) Train the model
Code:
python3
import gensim
import gensim.downloader as api
from gensim.models import doc2vec
dataset = api.load("text8")
data =[]
for w in dataset:
data.append(w)
def tagged_document(list_of_ListOfWords):
for x, ListOfWords in enumerate(list_of_ListOfWords):
yield doc2vec.TaggedDocument(ListOfWords, [x])
data_train = list(tagged_document(data))
print(data_train[:1])
|
Output:

OUTPUT – trained dataset
5.2) Update the modelCode:
python3
d2v_model = doc2vec.Doc2Vec(vector_size = 40, min_count = 2, epochs = 30)
d2v_model.build_vocab(data_train)
d2v_model.train(data_train, total_examples = d2v_model.corpus_count, epochs = d2v_model.epochs)
Analyze = d2v_model.infer_vector(['violent', 'means', 'to', 'destroy'])
print(Analyze)
|
Output:

Output of updated model
Step 6: Create Topic model with LDA
LDA is a popular method for topic modelling which considers each document as a collection of topics in a certain proportion. We need to take out the good quality of topics such as how segregated and meaningful they are. The good quality topics depend on-
- the quality of text processing
- finding the optimal number of topics
- Tuning parameters of the algorithm
NOTE: If you run this code on python3.7 version you might get a StopIteration Error.
It is advisable to use python3.6 version for this.
Follow the below steps to create the model:
6.1 Prepare the Data
This is done by removing the stopwords and then lemmatizing it. In order to lemmatize using Gensim, we need to first download the pattern package and the stopwords.
#download pattern package
pip install pattern
#run in python console
>> import nltk
>> nltk.download('stopwords')
Code:
python3
import gensim
from gensim import corpora
from gensim.models import LdaModel, LdaMulticore
import gensim.downloader as api
from gensim.utils import simple_preprocess, lemmatize
import nltk
from nltk.corpus import stopwords
import re
import logging
logging.basicConfig(format ='%(asctime)s : %(levelname)s : %(message)s')
logging.root.setLevel(level = logging.INFO)
stop_words = stopwords.words('english')
stop_words = stop_words + ['subject', 'com', 'are', 'edu', 'would', 'could']
dataset = api.load("text8")
data = [w for w in dataset]
processed_data = []
for x, doc in enumerate(data[:100]):
doc_out = []
for word in doc:
if word not in stop_words:
Lemmatized_Word = lemmatize(word, allowed_tags = re.compile('(NN|JJ|RB)'))
if Lemmatized_Word:
doc_out.append(Lemmatized_Word[0].split(b'/')[0].decode('utf-8'))
else:
continue
processed_data.append(doc_out)
print(processed_data[0][:10])
|
Output:

OUTPUT – processed_data
6.2 Create Dictionary and Corpus
The processed data will now be used to create the dictionary and corpus.
Code:
python3
dict = corpora.Dictionary(processed_data)
Corpus = [dict.doc2bow(l) for l in processed_data]
|
6.3 Train LDA model
We will be training the LDA model with 5 topics using the dictionary and corpus created previously.Here the LdaModel( ) function is used but you can also use the LdaMulticore( ) function as it allows parallel processing.
Code:
python3
LDA_model = LdaModel(corpus = LDA_corpus, num_topics = 5)
LDA_model.save('LDA_model.model')
print(LDA_model.print_topics(-1))
|
Output:

OUTPUT – topics
The words which can be seen in more than one topic and are of less relevance can be added to the stopwords list.
6.4 Interpret the Output
The LDA model majorly gives us information regarding 3 things:
- Topics in the document
- What topic each word belongs to
- Phi value
Phi value: It is the probability of a word to lie in a particular topic.For a given word, sum of the phi values give the number of times that word occurred in the document.
Code:
python3
LDA_model.get_term_topics('fire')
bow_list =['time', 'space', 'car']
bow = LDA_model.id2word.doc2bow(bow_list)
doc_topics, word_topics, phi_values = LDA_model.get_document_topics(bow, per_word_topics = True)
|
Step 7: Create Topic Model with LSI
To create the model with LSI just follow the steps same as with LDA. The only difference will be while training the model.
Use the LsiModel( ) function instead of the LdaMulticore( ) or LdaModel( ).
Code:
python3
LSI_model = LsiModel(corpus = Corpus, id2word = dct, num_topics = 7, decay = 0.5)
print(LSI_model.print_topics(-1))
|
Step 8: Compute Similarity Matrices
Cosine Similarity: It is a measure of similarity between two non-zero vectors of an inner product space. It is defined to equal the cosine of the angle between them.
Soft Cosine Similarity: It is similar to cosine similarity but the difference is that cosine similarity considers the vector space model(VSM) features as independent whereas soft cosine proposes to consider the similarity of features in VSM.
We need to take a word embedding model to compute soft cosines.
Here we are using the pre-trained word2vec model.
Note: If you run this code on python3.7 version you might get a StopIteration Error.
It is advisable to use python3.6 version for this.
Code:
python3
import gensim.downloader as api
from gensim.matutils import softcossim
from gensim import corpora
s1 = ' Afghanistan is an Asian country and capital is Kabul'.split()
s2 = 'India is an Asian country and capital is Delhi'.split()
s3 = 'Greece is an European country and capital is Athens'.split()
word2vec_model = api.load('word2vec-google-news-300')
similarity_matrix = word2vec_model.similarity_matrix(dictionary, tfidf = None, threshold = 0.0, exponent = 2.0, nonzero_limit = 100)
docs = [s1, s2, s3]
dictionary = corpora.Dictionary(docs)
s1 = dictionary.doc2bow(s1)
s2 = dictionary.doc2bow(s2)
s3 = dictionary.doc2bow(s3)
print(softcossim(s1, s2, similarity_matrix))
print(softcossim(s1, s3, similarity_matrix))
print(softcossim(s2, s3, similarity_matrix))
|
Some of the similarity and distance metrics which can be calculated for this word embedding model are mentioned below:
Code:
python3
print(word2vec_model.doesnt_match(['india', 'bhutan', 'china', 'mango']))
word2vec_model.distance('man', 'woman')
word2vec_model.distances('king', ['queen', 'man', 'woman'])
word2vec_model.cosine_similarities(word2vec_model['queen'],
vectors_all =(word2vec_model['king'],
word2vec_model['woman'],
word2vec_model['man'],
word2vec_model['king'] + word2vec_model['woman']))
word2vec_model.words_closer_than(w1 ='queen', w2 ='kingdom')
word2vec_model.most_similar(positive ='king', negative = None, topn = 5, restrict_vocab = None, indexer = None)
word2vec_model.most_similar_cosmul(positive ='queen', negative = None, topn = 5)
|
Step 9: Summarize Text Documents
The summarize( ) function implements the text rank summarization.
You do not have to generate a tokenized list by splitting the sentences as that is already handled by the gensim.summarization.textcleaner module.
Code:
python3
from gensim.summarization import summarize, keywords
import os
text = " ".join((l for l in open('sample_data.txt', encoding ='utf-8')))
print(summarize(text, word_count = 25))
|
Output:

OUTPUT – Summary
You can get the keywords by:
Code:

OUTPUT – Keywords
Conclusion:
These are some of the features of the Gensim library.This comes most handy while you are working on language processing.You can make use of these as per your need.
For any queries feel free to leave a comment down below.
Share your thoughts in the comments
Please Login to comment...