Transformer-based models are really good at understanding and processing text, but they struggle when the text is very long. To address this issue, researchers developed a device known as the “longformer.” It’s a modified Transformer meant to operate well with extremely lengthy bits of text. It accomplishes this by altering how it perceives words.
For the understanding of this article, we will take a running example of a task. Let’s say we want to classify a review written on the Geeks for Geeks website. The length of this review is 1000 words. Since it’s not practical to fit all the words of the review in the article at all the places, we will take a short representation of the review so that it becomes easy to comprehend the concepts presented. Let the review be “I love Geeks for Geeks”.
LongFormers
Longformers are neural networks designed specially to process and understand long sequences of text or other data. They are able to handle very long sequences and documents with thousand words, without experiencing the computational challenges that Transformers face.
Need For LongFormers
Transformer-based models improve in understanding and processing language, but struggle when the material is lengthy. This is because they use a kind of operation called “self-attention,” and the more words you have, the more complicated and slow this operation becomes. It’s like having to look at every word and figure out how it relates to every other word, which takes a lot of time and computing power.
To solve this problem, researchers came up with something called the “longformer.” It’s a modified version of the Transformer that’s designed to work well with super long pieces of text. It does this by changing how it pays attention to words.
Instead of trying to look at every word in the whole text all at once, the Longformer uses a combination of two types of attention. First, it looks closely at nearby words, kind of like reading a paragraph or a page at a time, which is faster. Then, it also looks at the bigger picture, trying to understand how different parts of the text connect to each other. This combination of close-up and big-picture attention helps the Longformer work efficiently with really long documents, like ones with thousands of words or even more.
Full Attention /Self Attention Mechanism
In layman’s terms, self-attention mechanism tries to measure the relationship of each word with all the other words in the sentence. In order to understand self-attention in detail we need to understand QUERY, KEY and VALUE.

Self Attention and Multi-Head Attention Mechanism
- Value is the sequential data we feed into the architecture. For our example : Each of the word of the review “I love geeks for geeks ‘” is an input. Each of the word in the review ‘I love geeks for geeks” will have a value which is the word embedding plus positional encoding.
- Query is the question that we ask about each word . Like who loves geeks for geeks?
- Key is a vector which describes how relevant is the associated value for the query. Think this in terms of searching a database. If we ‘query’ a database of collection of different ‘values’ how relevant is each value to the query result is determined by the ‘key’.
Please note that above concept of KEY, QUERY and VALUE is for logical understanding of the self attention mechanism. In practice, the weight matrix related to key, query and value are learnt by the model during training which we will discuss mathematically now.
Let us understand the working with help of below diagram.

Q and K vector calculation
VALUE – Each of the word is represented with word embeddings . For simplicity we have taken dimension of length 4 but in practice this are of size of 100s depending on the embedding used
QUERY AND KEY – For each of the word we calculate a query and key vector. We initialize a query matrix and key matrix with random value. This values are then learnt during the training of model using backprogogation.
For each word we multiply its value with the query and key matrix to get query and key value vector :
1. The first dimension of query matrix should match with the length of the embedding vector.
2. The second dimension can be any value. Here for explanation purpose we have taken it as 3. However the dimension of both query and key matrix should be same as we need to take dot product of QK vector as explained below.
Here in the diagram we have shown the calculation of Q1 and K1 for the word ‘I’ , the superscript 1 representing the first word. This is done for all the words . Hence we get a total of five Query , Key value pairs as :
Q1K1, Q2K2, Q3K3 , Q4K4, Q5K5

Self attention calculation for word ‘I’
Above diagram shows in detail how the self attention is calculated for the word ‘I
- First we obtain Q and K values for each of the word using the Query and Key weight matrix as shown in the figure 3.
- Then for each of the word we calculate the dot product of its query with the key value of each word in the sentence (Q1K1T , Q2K2T, Q3K3T,Q4K4T,Q5K5T ) . Here T represents transpose of the vector.
- The output of above is scalar value. Note the dimension of Q and K needs to be same as mentioned earlier exactly for this reason. We need to compute the dot product which is only possible if the dimension is same.
- The scalar value obtained in step 2 is passed through a softmax layer .
- The value obtained from step 4 is multiplied withe the value vector of each word and all the vector values are added to obtain a single attention vector.
- The output of step 5 is the self attention vector of word “I”.
- All the above steps are repeated for each word . The change would be in query vector as for word 2 we will be using Q2 to calculate dot product with keys.
The above operation can be represented mathematically as :

The dimension of attention vector is same as value vector . Thus the dimension of final output of the encoder block will be N x Vd where N is the number of words in the sentence and Vd is the dimension of value vector. If you observe all this are matrix calculation and can be done parallelly as there is no dependency of any calculation with other. Hence Transformer self attention mechanism is able to take a sequential input and process it in parallel.
Quadratic Scaling in Self Attention
Lets calculate the number of operation to be done for calculation of output of self
- For a single word to calculate its attention vector we need to do Q*K (dot multiplication) followed by softmax and multiply the value of softmax with the Value vector . For a single word ‘I’ this needs to be one with each other word of sentence(“I love Geeks for Geeks”). Thus a single word has N operations.
- The single word N operation has to be done for each word to calculate attention vectors of each word in the sentence. Since there are N words this will have to be done N times.
Hence we need to do N2 operations fore each sentence of length N which is quadratic in scale.
The quadratic scaling of operation of transformer with respective to input size makes it inefficient for processing long sentences/documents.This becomes very large and consumes large amount of memory. Hence it posses challenge for processing long sentences. The standard BERT model is able to process 512 tokens. Any long document with more than 512 words had to be either truncated or chunked which lead to information loss or cascading errors respectively.
This is were the long transformer comes in. It scales linearly with the input size thereby allowing 4 times the token size .
Attention Mechanism in Longformers
The long transformer proposed 4 types of self attention as shown in below diagram:

Longformer self-attention mechanism
The matrix shows different ways of calculating attention mechanism . Each row and column indicate the words in the sentence. This is N* N matrix where N is the size of input sentence. In the diagram ‘green squares’ indicate word where attention mechanism is calculated and ‘white square’ indicates the word where the attention mechanism is not calculated
Full Attention
This is the basic full attention mechanism of the transformer architecture as discussed above. Here all the squares are green indicating that for each word all the other words are used for calculation of attention mechanism. Thereby the scale of operations is N2(Quadratic). For our example full attention can be visually represented as
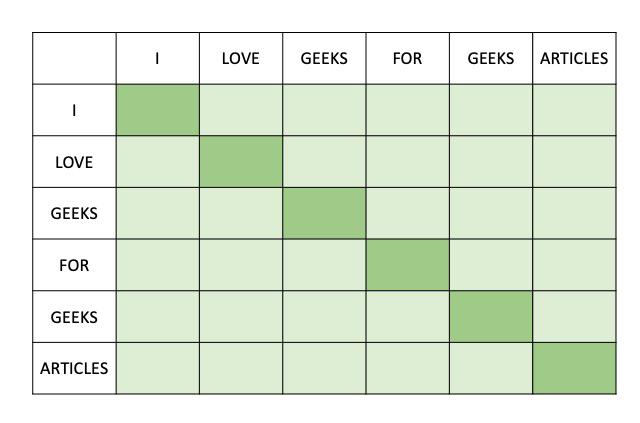
Full n^2 Attention
Sliding Window
In sliding window attention we do not compute the attention of each word with respect to all other words. Instead we take a window of length w and calculate the attention mechanism with respect to that window length. For example let say we have a window of length 2. So for sentence ‘I love geeks for geeks articles ‘ , for the third word ‘geeks’ we will calculate the attention vector considering ‘love’ and ‘for’ words only. The computation complexity of this attention window is O(N × w), which scales linearly with input sequence length N. A sliding window can be visually represented as
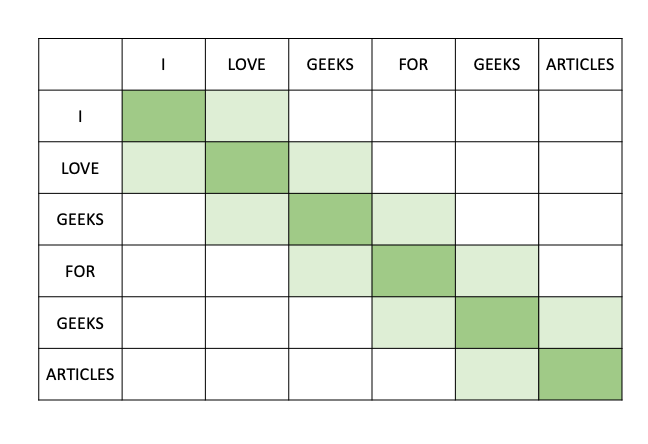
Sliding Window Attention
Dilated Sliding Window Attention
Also known as spare window the dilation window attention causes gap in the connection patterns as we skip certain token. It is similar to sliding window but here we attend to words with difference of ‘d’ within a window of ‘w'(indicated by white squares in between the green squares). This allows to increase the receptive file without increasing the memory requirement.
Through the utilization of dilated sliding windows, Transformers can prioritize capturing of dependencies and relationships within a limited local context, mitigating the computational complexity typically associated with considering all positions in the input sequence.
Here since the computations are limited within the window computation complexity scales linearly with respect to input .
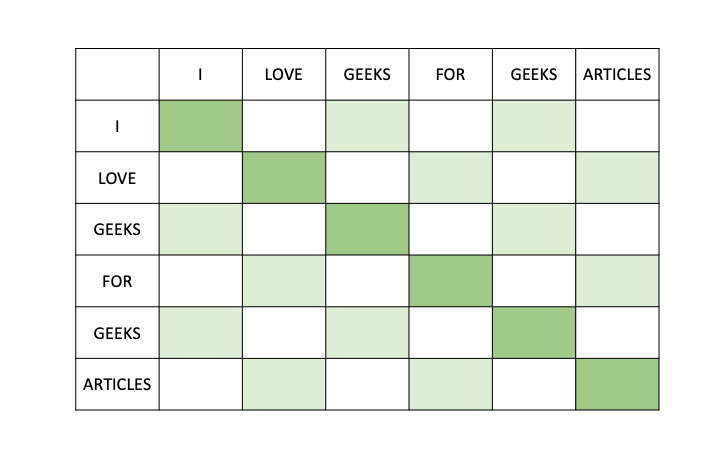
Dilated Sliding Window Attention
Global Sliding Window Attention
Global Sliding Window Attention is modification of sliding window mechanism in which we allow certain words or tokens to access all the tokens for attention vector calculation (indicated by green horizontal and vertical lines) . The self-attention mechanism of transformer works on both a “local” and “global” context. In the Longformer architecture, most tokens attend “locally” to each other within a specified window size. Tokens look at preceding and succeeding tokens within this local context. A selected few tokens have the ability to attend “globally” to all other tokens in the sequence. These global attention tokens have the capacity to consider information from the entire sequence, as opposed to being limited to a specific window size. It’s important to note that in Longformer’s design, every token that attends locally not only considers tokens within its window but also attends to all globally attending tokens. This ensures that the global attention is symmetric.
Global Sliding Window Attention strikes a middle ground, providing a compromise between computational efficiency and modeling capacity. This makes it well-suited for tasks that require a delicate balance between managing computational resources and capturing contextual information within a restricted context window.
Since global tokens are limited, the computations are limited and computation complexity scales linearly with respect to input.
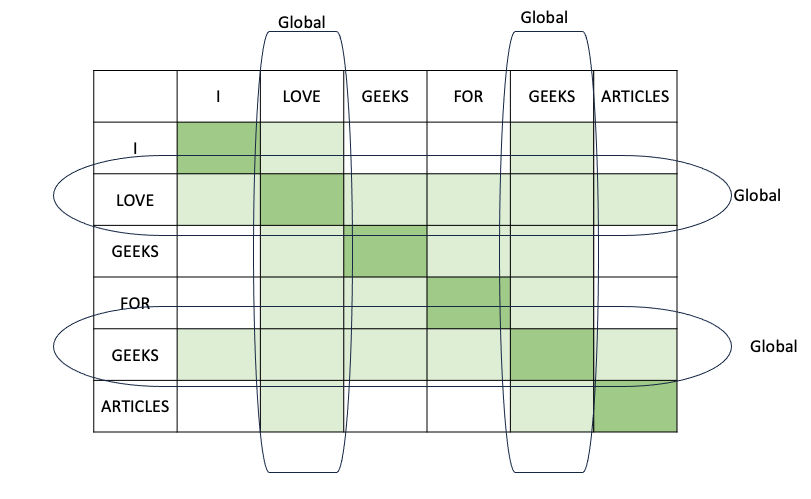
Global Attention Mechanism
Global Sliding Window and Dilated Attention techniques are designed to enhance the scalability and efficiency of the self-attention process within transformer-based models. They offer innovative alternatives to the conventional self-attention mechanism, striking a balance between computational demands and the ability to capture extensive contextual relationships within input sequence.
The hugging face Longformer model has support for global attention and not for dilated sliding window mechanism
Implementation of Longformers
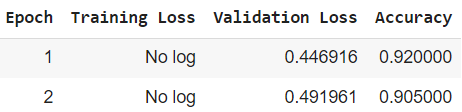
Let us use the long-transformer to classify the IMDB review dataset into positive or negative. This code was run successfully in google colab using T4 GPU. We will train it on 400 reviews and then use it to classify a new review. Using 200 train data and training epoch of 2 we were able to achieve accuracy of 90 % . If we use entire dataset and train for more epochs we can achieve much better accuracy.
First we need to install the dependencies
# Installing dependencies
!pip install transformers
!pip install datasets
!pip install transformers[torch]
!pip install evaluate
!pip install torch
!pip install accelerate
We will use the hugging face model ‘allenai/longformer-base-4096’. Loading the tokenizer .
Python3
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("allenai/longformer-base-4096")
|
Loading the IMDB dataset and applying the tokenizer.
Python3
import datasets
train_ds = datasets.load_dataset("imdb", split="train[:200]+train[-200:]")
test_ds = datasets.load_dataset("imdb", split="test[:100]+test[-100:]")
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True)
train_tokenized_imdb = train_ds.map(preprocess_function, batched=True)
test_tokenized_imdb = test_ds.map(preprocess_function, batched=True)
|
Creating label index and loading the model.
Python3
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
id2label = {0: "NEGATIVE", 1: "POSITIVE"}
label2id = {"NEGATIVE": 0, "POSITIVE": 1}
model = AutoModelForSequenceClassification.from_pretrained(
"allenai/longformer-base-4096",
num_labels=2,
id2label=id2label,
label2id=label2id
)
|
Using Data Collator to create batches of tokenized input with padding during run time. Also creating a compute_metric function for evaluation of test data during training. This function will calculate the accuracy of our classification.
Python3
import numpy as np
import evaluate
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy.compute(predictions=predictions, references=labels)
|
Training the model
The training_args contain the hyperparameters. You can modify them as per your requirement.
Python3
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="sequence_classification",
learning_rate=2e-5,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_tokenized_imdb,
eval_dataset=test_tokenized_imdb,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
|
Output:
Once the model is trained and saved we can use it for inferencing on new data. Inferencing from the trained model.
Python3
import torch
model = AutoModelForSequenceClassification.from_pretrained(
"/content/sequence_classification/checkpoint-200")
text = "This was an awesome movie."
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
|
Output:
'POSITIVE'
Share your thoughts in the comments
Please Login to comment...