Lexicographic rank of a string with duplicate characters
Last Updated :
29 Mar, 2024
Given a string s that may have duplicate characters. Find out the lexicographic rank of s. s may consist of lower as well as upper case letters. We consider the lexicographic order of characters as their order of ASCII value. Hence the lexicographical order of characters will be ‘A’, ‘B’, ‘C’, …, ‘Y’, ‘Z’, ‘a’, ‘b’, ‘c’, …, ‘y’, ‘z’.
Examples:
Input : “abab”
Output : 2
Explanation: The lexicographical order is: “aabb”, “abab”, “abba”, “baab”, “baba”, “bbaa”. Hence the rank of “abab” is 2.
Input: “settLe”
Output : 107
Prerequisite: Lexicographic rank of a string
Method:
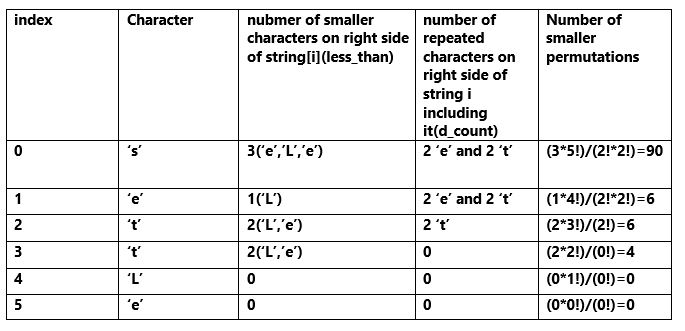
The method here is a little different from the without repetition version. Here we have to take care of the duplicate characters also. Let’s look at the string “settLe”. It has repetition(2 ‘e’ and 2 ‘t’) as well as upper case letter(‘L’). Total 6 characters and the total number of permutations are 6!/(2!*2!).
Now there are 3 characters(2 ‘e’ and 1 ‘L’) on the right side of ‘s’ which come before ‘s’ lexicographically. If there were no repetition then there would be 3*5! smaller strings which have the first character less than ‘s’. But starting from position 0, till the end there are 2 ‘e’ and 2 ‘t'(i.e. repetitions). Hence, the number of possible smaller permutations with the first letter smaller than ‘s’ are (3*5!)/(2!*2!).
Similarly, if we fix ‘s’ and look at the letters from index 1 to end then there is 1 character(‘L’) lexicographically less than ‘e’. And starting from position 1 there are 2 repeated characters(2 ‘e’ and 2 ‘t’). Hence, the number of possible smaller permutations with first letter ‘s’ and second letter smaller than ‘e’ are (1*4!)/(2!*2!).
Similarly, we can form the following table:
WorkFlow:
1. Initialize t_count(total count) variable
to 1(as rank starts from 1).
2. Run a loop for every character of the string, string[i]:
(i) using a loop count less_than(number of smaller
characters on the right side of string[i]).
(ii) take one array d_count of size 52 and using a
loop count the frequency of characters starting
from string[i].
(iii) compute the product, d_fac(the product of
factorials of each element of d_count).
(iv) compute (less_than*fac(n-i-1))/(d_fac).
Add it to t_count.
3. return t_count
C++
#include <iostream>
#include <vector>
using namespace std;
long long fac(long long n)
{
if (n == 0 or n == 1)
return 1;
return n * fac(n - 1);
}
int lexRank(string s)
{
long long n = s.size();
long long t_count = 1;
for (int i = 0; i < n; i++)
{
int less_than = 0;
for (int j = i + 1; j < n; j++)
{
if (int(s[i]) > int(s[j]))
{
less_than += 1;
}
}
vector<int> d_count(52, 0);
for (int j = i; j < n; j++)
{
if ((int(s[j]) >= 'A') && int(s[j]) <= 'Z')
d_count[int(s[j]) - 'A'] += 1;
else
d_count[int(s[j]) - 'a' + 26] += 1;
}
long long d_fac = 1;
for (int ele : d_count)
d_fac *= fac(ele);
t_count += (fac(n - i - 1) * less_than) / d_fac;
}
return (int)t_count;
}
int main()
{
string s1 = "abab";
cout << "Rank of " << s1 << " is: " << lexRank(s1)
<< endl;
string s2 = "settLe";
cout << "Rank of " << s2 << " is: " << lexRank(s2)
<< endl;
return 0;
}
|
Java
class GFG {
static long fac(long n)
{
if (n == 0 || n == 1)
return 1;
return n * fac(n - 1);
}
static int lexRank(String s)
{
long n = s.length();
long t_count = 1;
for (int i = 0; i < n; i++)
{
long less_than = 0;
for (int j = i + 1; j < n; j++)
{
if (s.charAt(i)
> s.charAt(j))
{
less_than += 1;
}
}
long[] d_count = new long[52];
for (int j = i; j < n; j++)
{
if ((s.charAt(j) >= 'A')
&& s.charAt(j) <= 'Z')
d_count[s.charAt(j) - 'A'] += 1;
else
d_count[s.charAt(j) - 'a' + 26] += 1;
}
long d_fac = 1;
for (long ele : d_count)
d_fac *= fac(ele);
t_count += (fac(n - i - 1)
* less_than) / d_fac;
}
return (int)t_count;
}
public static void main(String[] args)
{
String s1 = "abab";
System.out.print("Rank of " + s1
+ " is: " + lexRank(s1) + "\n");
String s2 = "settLe";
System.out.print("Rank of " + s2
+ " is: " + lexRank(s2) + "\n");
}
}
|
Python3
def fac(n):
if n == 0 or n == 1:
return 1
return n * fac(n - 1)
def lexRank(s):
n = len(s)
t_count = 1
for i in range(n):
less_than = 0
for j in range(i + 1, n):
if ord(s[i]) > ord(s[j]):
less_than += 1
d_count = [0] * 52
for j in range(i, n):
if ord(s[j]) >= ord('A') and ord(s[j]) <= ord('Z'):
d_count[ord(s[j]) - ord('A')] += 1
else:
d_count[ord(s[j]) - ord('a') + 26] += 1
d_fac = 1
for ele in d_count:
d_fac *= fac(ele)
t_count += (fac(n - i - 1) * less_than) // d_fac
return t_count
s1 = "abab"
print("Rank of", s1, "is:", lexRank(s1))
s2 = "settLe"
print("Rank of", s2, "is:", lexRank(s2))
|
C#
using System;
class GFG {
static long fac(long n)
{
if (n == 0 || n == 1)
return 1;
return n * fac(n - 1);
}
static long lexRank(String s)
{
long n = s.Length;
long t_count = 1;
for (long i = 0; i < n; i++)
{
long less_than = 0;
for (long j = i + 1; j < n; j++)
{
if (s[i] > s[j])
{
less_than += 1;
}
}
long[] d_count = new long[52];
for (int j = i; j < n; j++)
{
if ((s[j] >= 'A') && s[j] <= 'Z')
d_count[s[j] - 'A'] += 1;
else
d_count[s[j] - 'a' + 26] += 1;
}
long d_fac = 1;
foreach(long ele in d_count)
d_fac *= fac(ele);
t_count += (fac(n - i - 1)
* less_than) / d_fac;
}
return t_count;
}
public static void Main(String[] args)
{
String s1 = "abab";
Console.Write("Rank of " + s1
+ " is: " + lexRank(s1) + "\n");
String s2 = "settLe";
Console.Write("Rank of " + s2
+ " is: " + lexRank(s2) + "\n");
}
}
|
Javascript
<script>
function fac(n)
{
if (n == 0 || n == 1)
return 1;
return n * fac(n - 1);
}
function lexRank(s)
{
n = s.length;
let t_count = 1;
for (let i = 0; i < n; i++)
{
let less_than = 0;
for (let j = i + 1; j < n; j++)
{
if (s[i]
> s[j])
{
less_than += 1;
}
}
let d_count = new Array(52);
for(let i=0;i<52;i++)
d_count[i]=0;
for (let j = i; j < n; j++)
{
if ((s[j] >= 'A')
&& s[j] <= 'Z')
d_count[s[j].charCodeAt(0) - 'A'.charCodeAt(0)] += 1;
else
d_count[s[j].charCodeAt(0) - 'a'.charCodeAt(0) + 26] += 1;
}
let d_fac = 1;
for (let ele=0;ele< d_count.length;ele++)
d_fac *= fac(d_count[ele]);
t_count += (fac(n - i - 1)
* less_than) / d_fac;
}
return t_count;
}
let s1 = "abab";
document.write("Rank of " + s1
+ " is: " + lexRank(s1) + "<br>");
let s2 = "settLe";
document.write("Rank of " + s2
+ " is: " + lexRank(s2) + "<br>");
</script>
|
Output
Rank of abab is: 2
Rank of settLe is: 107
Time complexity: O(n2)
Space complexity: O(1)
Share your thoughts in the comments
Please Login to comment...