Julia is a high-performance programming language designed for numerical and scientific computing. It is designed to be easy to use, yet powerful enough to solve complex problems efficiently. One of the key features of Julia is its support for parallelism, which allows you to take advantage of multiple CPU cores and distributed computing clusters to speed up your computations and scale your applications.
In Julia, parallelism is achieved through a variety of mechanisms, including multi-threading, distributed computing, and GPU computing which are explained below in detail.
Multi-threading
Julia’s multi-threading provides the ability to schedule Tasks simultaneously on more than one thread or CPU core, sharing memory. This is usually the easiest way to get parallelism on one’s PC or on a single large multi-core server. Julia’s multi-threading is composable. When one multi-threaded function calls another multi-threaded function, Julia will schedule all the threads globally on available resources, without oversubscribing.
Below is the Julia program to implement parallelism using multi-threading:
Julia
using Base.Threads
function my_thread(id::Int)
println("hello from thread $id")
end
for i in 1:4
@spawn my_thread(i)
end
|
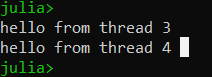
Output
In this example, we create a function my_thread that takes an integer id as an argument and prints a message to the console. We then create four threads using the Thread constructor and schedule them to run asynchronously using the schedule function.
Distributed Computing
Distributed computing runs multiple Julia processes with separate memory spaces. These can be on the same computer or multiple computers. The Distributed standard library provides the capability for the remote execution of a Julia function. With this basic building block, it is possible to build many different kinds of distributed computing abstractions. Packages like DistributedArrays.jl are an example of such an abstraction. On the other hand, packages like MPI.jl and Elemental.jl provide access to the existing MPI ecosystem of libraries.
Below is the Julia program to implement parallelism using Distributed Computing:
Julia
using Distributed
addprocs(4)
@everywhere function my_task(id::Int)
println("hello from process $id")
end
@sync for i in 1:4
@async begin
result = fetch(@spawnat i my_task(i))
println(result)
end
end
|
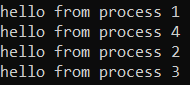
Output
GPU Computing
The Julia GPU compiler provides the ability to run Julia code natively on GPUs. There is a rich ecosystem of Julia packages that target GPUs.
Advantages of Parallelism in Julia:
- The advantage of Julia’s parallelism is that it allows users to take advantage of the full power of modern hardware, including multi-core CPUs and GPUs. Additionally, Julia’s syntax and built-in libraries are designed to make parallel programming more accessible and easier to use, even for users who are not experts in parallel computing.
- To take advantage of parallelism in Julia, users can use built-in functions and macros such as @spawn, @sync, and @distributed, as well as specialized libraries like DistributedArrays.jl, MPI.jl, and CUDA.jl. for GPU programming. With these tools, Julia makes it possible to write code that runs faster and more efficiently, even on large datasets or complex computations.
Asynchronous Programming
Julia provides Tasks (also known by several other names, such as symmetric coroutines, lightweight threads, cooperative multitasking, or one-shot continuations). When a piece of computing work (in practice, executing a particular function) is designated as a Task, it becomes possible to interrupt it by switching to another Task. The original Task can later be resumed, at which point it will pick up right where it left off.
Below is the Julia program to implement asynchronous programming:
Julia
t = @task begin;
sleep(5);
println("done");
end
|
This task will wait for five seconds, and then print “done”. However, it has not started running yet. We can run it whenever we’re ready by calling the schedule:
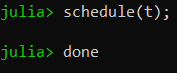
Output
If you try this in the REPL, you will see that schedule returns immediately. That is because it simply adds t to an internal queue of tasks to run. Then, the REPL will print the next prompt and wait for more input.
Global Variables
In Julia, global variables are variables that are defined outside of any function or module and can be accessed and modified from anywhere in the program.
Below is the Julia program to implement global variables:
Julia
global_var = 10
function increment_global()
global global_var
global_var += 1
end
println(global_var)
increment_global()
println(global_var)
|
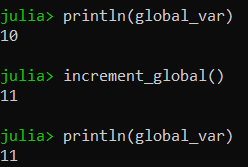
Output
However, using global variables can lead to issues such as unintended side effects and poor performance, and it is generally recommended to avoid them whenever possible.
Parallel Maps and Loops
Parallel maps and loops can be useful for computations that involve a large number of independent operations, such as image processing, numerical simulations, or machine learning. By using parallelism, we can reduce the time required to perform these computations and take full advantage of the available hardware resources. However, parallelism also introduces additional complexity and overhead, and it is important to carefully design and test parallel algorithms to ensure correctness and efficiency.
In Julia, parallel maps and loops are used to distribute computations across multiple processors or threads and to take advantage of parallelism to speed up the execution of code. One way to implement parallel maps and loops in Julia is to use the “pmap” and “@distributed” macros, which distribute the computation of a function or loop across multiple worker processes.
Below is the Julia program to implement parallel maps and loops:
Julia
function square(x)
return x^2
end
input = [1, 2, 3, 4, 5]
output = pmap(square, input)
|
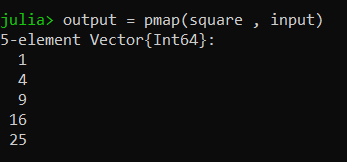
Output
Synchronization with Remote References
In Julia, synchronization with remote references is a mechanism that allows multiple processes to share and update values stored in remote memory locations. This is useful in distributed computing scenarios, where multiple processes running on different machines need to communicate and coordinate their actions. Remote references can also be used to implement more complex synchronization patterns, such as locking, semaphores, and message passing. However, these patterns require careful design and implementation to ensure correctness and efficiency and are best left to specialized libraries and frameworks that provide higher-level abstractions and primitives for distributed computing.
In Julia, remote references are created using the RemoteRef type, which represents a reference to a value stored in a remote process. To synchronize with a remote reference, we can use the put! and fetch functions. The put! function writes a value to a remote reference, while the fetch function reads a value from a remote reference.
Below is the Julia program to implement synchronization with remote references:
Julia
using Distributed;
addprocs(4);
const jobs = RemoteChannel(()->Channel{Int}(32));
const results = RemoteChannel(()->Channel{Tuple}(32));
@everywhere function do_work(jobs, results)
while true
job_id = take!(jobs)
exec_time = rand()
sleep(exec_time)
put!(results, (job_id, exec_time, myid()))
end
end
function make_jobs(n)
for i in 1:n
put!(jobs, i)
end
end;
n = 12;
errormonitor(@async make_jobs(n));
for p in workers()
remote_do(do_work, p, jobs, results)
end
@elapsed while n > 0
job_id, exec_time, where = take!(results)
println("$job_id finished in $(round(exec_time; digits=2)) seconds on worker $where")
global n = n - 1
end
|
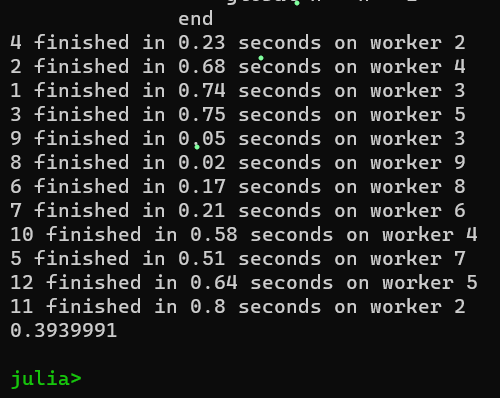
Output
Channels
In Julia, channels are a synchronization primitive that allows different processes to communicate by passing messages to each other. A channel is a queue that holds a sequence of values and provides methods for sending and receiving values between processes. Channels are useful for implementing message-passing algorithms, producer-consumer patterns, and other forms of inter-process communication.
To create a channel, we use the Channel function, which takes an optional argument specifying the maximum number of elements that can be stored in the channel. Below is the Julia program to implement Channels:
Julia
channel = Channel(10)
put!(channel, "Hello world")
value = take!(channel)
|
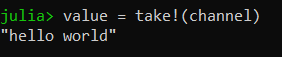
Output
Remote References and Abstract Channels
In Julia, remote references and abstract channels are two powerful abstractions for concurrent and distributed programming.
- Remote references, as we discussed earlier, are a mechanism for sharing and updating values stored in remote memory locations. Remote references can be used to implement fine-grained synchronization between processes, and are particularly useful in distributed computing scenarios where processes are running on different machines. Remote references can be created using the RemoteRef function, and values can be written and read using the put! and fetch functions.
- Abstract channels, on the other hand, are a mechanism for passing messages between processes and can be used to implement more coarse-grained communication patterns. Abstract channels are an abstraction that can be used to represent any kind of message-passing mechanism, such as sockets, pipes, and queues. Abstract channels can be created using the Channel function, and values can be sent and received using the put! and take! functions.
In Julia, remote references and abstract channels can be combined to implement more complex distributed algorithms and protocols. For example, we can use a remote reference to represent a shared counter or data structure and use an abstract channel to pass messages between processes that update the counter or access the data structure. Or we can use a remote reference to represent a lock or semaphore and use an abstract channel to pass messages between processes that request or release the lock.
Conclusion
Julia’s support for parallelism and distributed computing makes it an excellent choice for scientific and numerical computing, where computations can be parallelized and distributed across multiple cores or even multiple machines. By using Julia’s built-in support for parallelism, it is possible to write highly efficient and scalable code that can take full advantage of modern hardware.
Overall, Julia’s support for parallelism is one of its strongest features and makes it a compelling choice for anyone who needs to write code that can take advantage of modern hardware.
Share your thoughts in the comments
Please Login to comment...