How to get keys and values from Map Type column in Spark SQL DataFrame
Last Updated :
23 Apr, 2023
In Python, the MapType function is preferably used to define an array of elements or a dictionary which is used to represent key-value pairs as a map function. The Maptype interface is just like HashMap in Java and the dictionary in Python. It takes a collection and a function as input and returns a new collection as a result.
The formation of a map column is possible by using the createMapType() function on the DataTypes class such as StringType, IntegerType, ArrayType, and many more. This formation mainly takes two arguments, one is keyType and another is valueType which should extend the DataTypes class. valueContainsNull is the third param which is an optional boolean type, used to signify the value of the second param which accepts Null/None values. To get the key-value pair map type function applies a given operation to each element of a collection such as either list or an array.
Features and functionalities of MapType function:
- We use maptype function for data transformation due to its flexibility.
- It applies various transformations on output such as addition, multiplication, string concatenation, or other, which is defined for the collection of data type.
- MapType functions are collimated, which signifies that they can be executed on multiple threads to enhance the performance of map functions to handle massive collections.
- Output is computed only when they are needed, which overall saves memory as well as run time.
Create MapType in Spark DataFrame
Let us first create PySpark MapType to create map objects using the MapType() function. Then create the schema using the StructType() and StructField() functions. After that create a DataFrame using the spark.createDataDrame() method, which takes the data as one of its parameters. In this example, we are taking a list of tuples as the dataset. the printSchema() and show() methods are used to display the schema and the dataframe as the output.
Python3
from pyspark.sql.types import StringType, MapType
mapCol = MapType(StringType(),StringType(),False)
from pyspark.sql.types import StructField, StructType, StringType, MapType
schema = StructType([
StructField('identification', StringType(), True),
StructField('features', MapType(StringType(),StringType()),True)
])
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GeeksforGeeks').getOrCreate()
dataDictionary = [
('Shivaz',{'pupil':'black','nails':'white'}),
('Shivi',{'pupil':'brown','nails':'yellow'}),
('Shiv',{'pupil':'green','nails':'white'}),
('Shaz',{'pupil':'grey','nails':'yellow'}),
('Shiva',{'pupil':'blue','nails':'white'})
]
df = spark.createDataFrame(data=dataDictionary, schema = schema)
df.printSchema()
df.show(truncate=False)
|
Output:

Schema and DataFrame created
Steps to get Keys and Values from the Map Type column in SQL DataFrame
The described example is written in Python to get keys and values from the Map Type column in the SQL dataframe.
Example 1: Display the attributes and features of MapType
In this example, we will extract the keys and values of the features that are used in the DataFrame. Thr rdd.map() function returns the new DataFrame after applying the provided operation to each element of the input DataFrame.
Python3
df3=df.rdd.map(lambda x: \
(x.identification,x.features["pupil"],x.features["nails"])) \
.toDF(["identification","pupil","nails"])
df3.printSchema()
df3.show()
|
Output:

Schema, Attributes and Features of the DataFrame
Example 2: Get the keys and values from MapType using .getItem()
Python3
df.withColumn("pupil",df.features.getItem("pupil")) \
.withColumn("nails",df.features.getItem("nails")) \
.drop("features") \
.show()
|
Output:

Keys and Values using getItem()
Example 3: Getting all the keys MapType using Explode function
Using the explode() function, we can get all the keys that are in MapType.
Python3
from pyspark.sql.functions import explode,map_keys
keysDF = df.select(explode(map_keys(df.features))).distinct()
keysList = keysDF.rdd.map(lambda x:x[0]).collect()
print(keysList)
|
Output:
['pupil', 'nails']
Example 4: Getting the keys and values using explode function
Python3
from pyspark.sql.functions import explode
df.select(df.identification,explode(df.features)).show()
|
Output:

Keys and Values using explode() function
Example 5: Getting keys and values using map_key function
Python3
from pyspark.sql.functions import map_keys
df.select(df.identification,map_keys(df.features)).show()
|
Output:
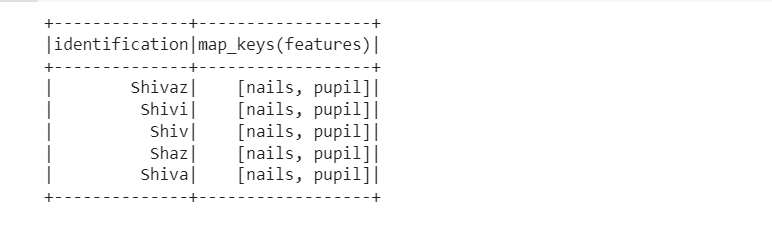
Keys and Values using map_key() function
Example 6: Getting keys and values using map_values.
Python3
from pyspark.sql.functions import map_values
df.select(df.identification,map_values(df.features)).show()
|
Output:

Keys and Values using map_values() function
Conclusion
The above implementation shows the multiple ways to fetch the key-value pair using maptype function. Hence, we can easily implement maptype function similar to the dictionary.
Share your thoughts in the comments
Please Login to comment...