In this article, we will use Scrapy, for scraping data, presenting on linked webpages, and, collecting the same. We will scrape data from the website ‘https://quotes.toscrape.com/’.
Creating a Scrapy Project
Scrapy comes with an efficient command-line tool, also called the ‘Scrapy tool’. Commands are used for different purposes and, accept a different set of arguments, and options. To write the Spider code, we begin by creating, a Scrapy project, by executing the following command, at the terminal:
scrapy startproject gfg_spiderfollowlink
Use ‘startproject’ command to create a Scrapy Project
This should create a ‘gfg_spiderfollowlink’ folder in your current directory. It contains a ‘scrapy.cfg’, which is a configuration file, of the project. The folder structure is as shown below –

The folder structure of ‘gfg_spiderfollowlink’ folder
The folder contains items.py,middlerwares.py and other settings files, along with the ‘spiders’ folder.
The folder structure of ‘gfg_spiderfollowlink’ folder
Keep the contents of the configuration files as they are currently.
Extracting Data from one Webpage
The code for web scraping is written in the spider code file. To create the spider file, we will make use of the ‘genspider’ command. Please note, that this command is executed at the same level where scrapy.cfg file is present.
We are scraping all quotes present, on ‘http://quotes.toscrape.com/’. Hence, we will run the command as:
scrapy genspider gfg_spilink "quotes.toscrape.com"
Execute ‘genspider’ command to create a Spider file
The above command will create a spider file, “gfg_spilink.py” in the ‘spiders’ folder. The default code, for the same, is as follows:
Python3
import scrapy
class GfgSpilinkSpider(scrapy.Spider):
name = 'gfg_spilink'
allowed_domains = ['quotes.toscrape.com']
def parse(self, response):
pass
|
We will scrape all Quotes Title, Authors, and Tags from the website “quotes.toscrape.com”. The website landing page looks as shown below:
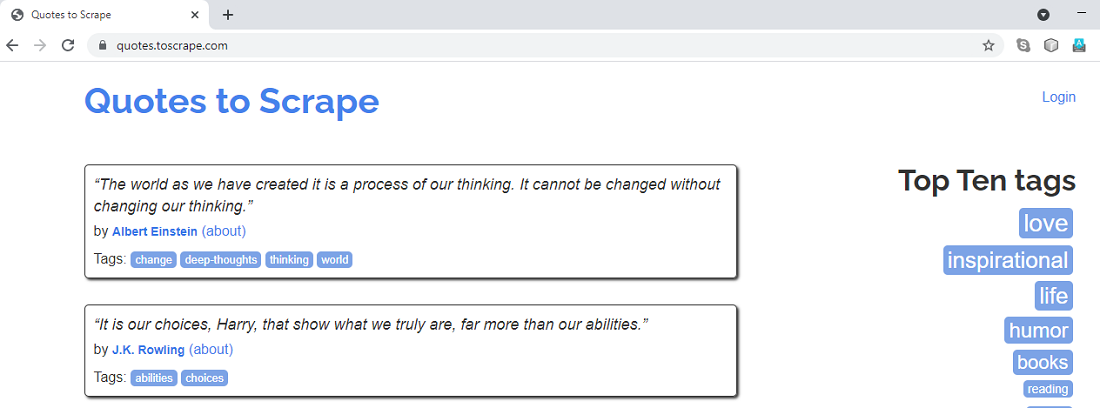
The landing page of “quotes.toscrape.com”
Scrapy provides us, with Selectors, to “select” parts of the webpage, desired. Selectors are CSS or XPath expressions, written to extract data from HTML documents. In this tutorial, we will make use of XPath expressions, to select the details we need.
Let us understand the steps for writing the selector syntax in the spider code:
- Firstly, we will write the code in the parse() method. This is the default callback method, present in the spider class, responsible for processing the response received. The data extraction code, using Selectors, will be written here.
- For writing the XPath expressions, we will select the element on the webpage, say Right-Click, and choose the Inspect option. This will allow us to view its CSS attributes.
- When we right-click on the first Quote and choose Inspect, we can see it has the CSS ‘class’ attribute “quote”. Similarly, all the other quotes on the webpage have the same CSS ‘class’ attribute. It can be seen below:
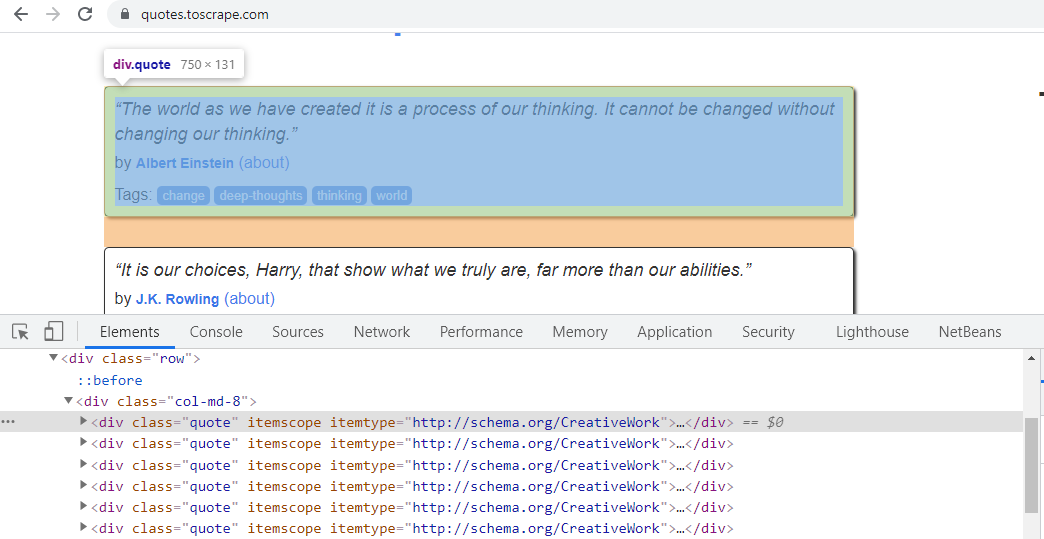
Right Click first quote and check its CSS “class” attribute
Hence, the XPath expression, for the same, can be written as – quotes = response.xpath(‘//*[@class=”quote”]’). This syntax will fetch all elements, having “quote”, as the CSS ‘class’ attribute. The quotes present on further pages have the same CSS attribute. For example, the quotes present on Page 3, of the website, belong to the ‘class’ attribute, as shown below –
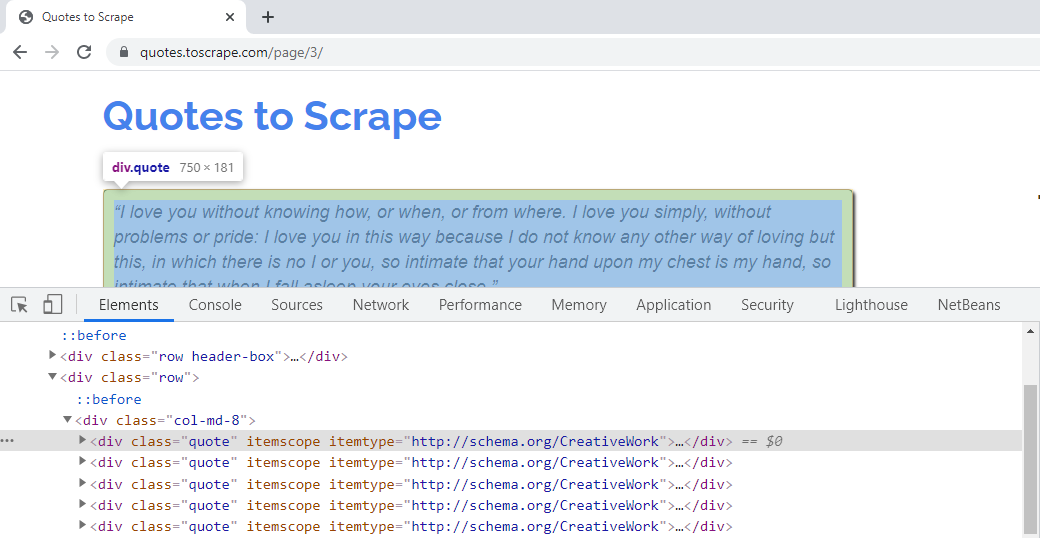
The Quotes on further pages of the website belong to the same CSS class attribute
We need to fetch the Quote Title, Author, and Tags of all the Quotes. Hence, we will write XPath expressions for extracting them, in a loop.
- The CSS ‘class’ attribute, for Quote Title, is “text”. Hence, the XPath expression, for the same, would be – quote.xpath(‘.//*[@class=”text”]/text()’).extract_first(). The text() method, will extract the text, of the Quote title. The extract_first() method, will give the first matching value, with the CSS attribute “text”. The dot operator ‘.’ in the start, indicates extracting data, from a single quote.
- The CSS attributes, “class” and “itemprop”, for author element, is “author”. We can use, any of these, in the XPath expression. The syntax would be – quote.xpath(‘.//*[@itemprop=”author”]/text()’).extract(). This will extract, the Author name, where the CSS ‘itemprop’ attribute is ‘author’.
- The CSS attributes, “class” and “itemprop”, for tags element, is “keywords”. We can use, any of these, in the XPath expression. Since there are many tags, for any quote, looping through them, will be tedious. Hence, we will extract the CSS attribute “content”, from every quote. The XPath expression for the same is – quote.xpath(‘.//*[@itemprop=”keywords”]/@content’).extract(). This will extract, all tags values, from “content” attribute, for quotes.
- We use ‘yield’ syntax to get the data. We can collect, and, transfer data to CSV, JSON, and other file formats, by using ‘yield’.
If we observe the code till here, it will crawl and extract data for one webpage. The code is as follows –
Python3
import scrapy
class GfgSpilinkSpider(scrapy.Spider):
name = 'gfg_spilink'
allowed_domains = ['quotes.toscrape.com']
def parse(self, response):
quotes = response.xpath('//*[@class="quote"]')
for quote in quotes:
title = quote.xpath(
'.//*[@class="text"]/text()').extract_first()
authors = quote.xpath('.//*[@itemprop="author"]/text()').extract()
tags = quote.xpath('.//*[@itemprop="keywords"]/@content').extract()
yield {"Quote Text ": title, "Authors ": authors, "Tags ": tags}
|
Following Links
Till now, we have seen the code, to extract data, from a single webpage. Our final aim is to fetch, the Quote’s related data, from all the web pages. To do so, we need to make our spider, follow links, so that it can navigate, to the subsequent pages. The hyperlinks are usually defined, by writing <a> tags. The “href” attribute, of the <a> tags, indicates the link’s destination. We need to extract, the “href” attribute, to traverse, from one page to another. Let us study, how to implement the same –
- To traverse to the next page, check the CSS attribute of the “Next” hyperlink.
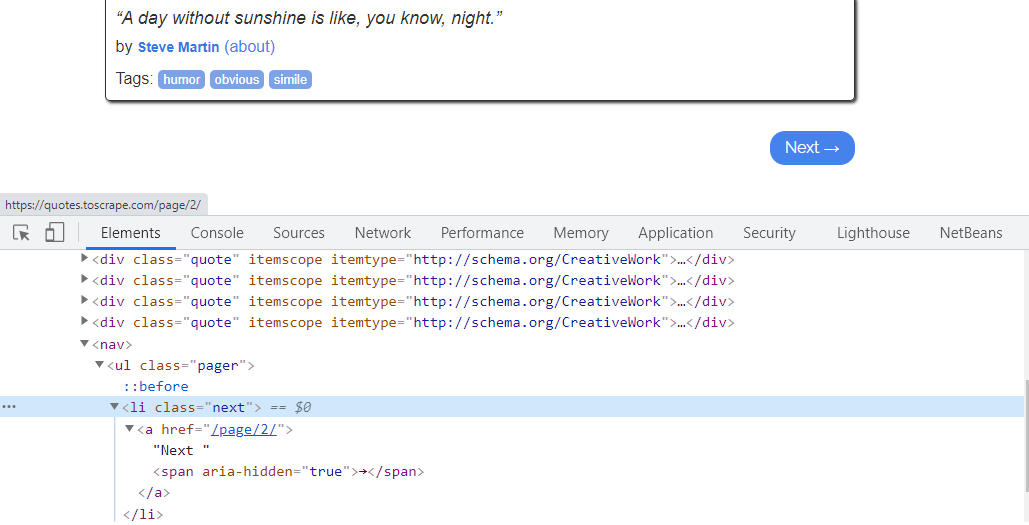
The CSS class attribute of “Next ->” hyperlink is “next”
We need to extract, the “href” attribute, of the <a> tag of HTML. The “href” attribute, denotes the URL of the page, where the link goes to. Hence, we need to fetch the same, and, join to our current path, for the spider to navigate, to further pages seamlessly. For the first page, the “href” value of <a> tag is, “/page/2”, which means, it links to the second page.
If you click, and, observe the “Next” link of the second webpage, it has a CSS attribute as “next”. For this page, the “href” value of <a> tag, is “/page/3” which means, it links to the third page, and so on.
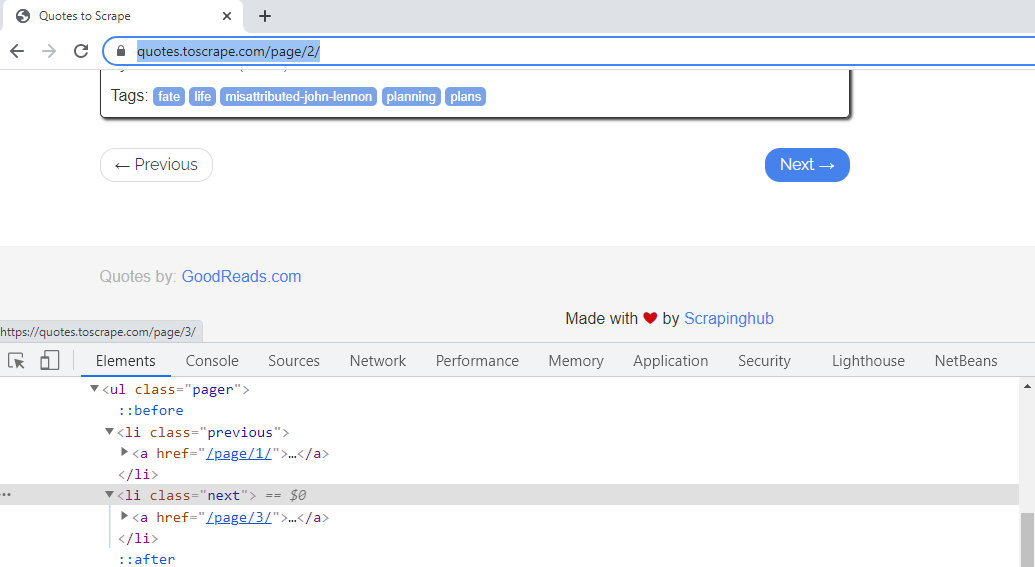
The “href” attribute of “Next” link on page2, links to the 3rd webpage
Hence, the XPath expression, for the next page link, can be fetched writing expression as – further_page_url = response.xpath(‘//*[@class=”next”]/a/@href’).extract_first(). This will give us, value of “@href” , which is “/page/2” for the first page.
The URL above, is not sufficient, to make the spider crawl, to the next page. We need to form, an absolute URL, by merging the response object URL, with the above relative URL. To do so, we will use urljoin() method.
The Response object URL is “https://quotes.toscrape.com/”. To travel, to the next page, we need to join it, with the relative URL “/page/2”. The syntax, for the same is – complete_url_next_page = response.urljoin(further_page_url). This syntax, will give us, the complete path as, “https://quotes.toscrape.com/page/2/”. Similarly, for second page, it will modify, according to the webpage number, as “https://quotes.toscrape.com/page/3/” and so on.
The parse method, will now make a new request, using this ‘complete_url_next_page ‘ URL.
Hence, our final Request object, for navigating to the second page, and crawling it, will be – yield scrapy.Request(complete_url_next_page). The complete code of the spider will be as follows:
Python3
import scrapy
class GfgSpilinkSpider(scrapy.Spider):
name = 'gfg_spilink'
allowed_domains = ['quotes.toscrape.com']
def parse(self, response):
quotes = response.xpath('//*[@class="quote"]')
for quote in quotes:
title = quote.xpath('.//*[@class="text"]/text()').extract_first()
authors = quote.xpath('.//*[@itemprop="author"]/text()').extract()
tags = quote.xpath('.//*[@itemprop="keywords"]/@content').extract()
yield {"Quote Text ": title, "Authors ": authors, "Tags ": tags}
further_page_url = response.xpath(
'//*[@class="next"]/a/@href').extract_first()
complete_url_next_page = response.urljoin(further_page_url)
yield scrapy.Request(complete_url_next_page)
|
Execute the Spider, at the terminal, by using the command ‘crawl’. The syntax is as follows – scrapy crawl spider_name. Hence, we can run our spider as – scrapy crawl gfg_spilink. It will crawl, the entire website, by following links, and yield the Quotes data. The output is as seen below –
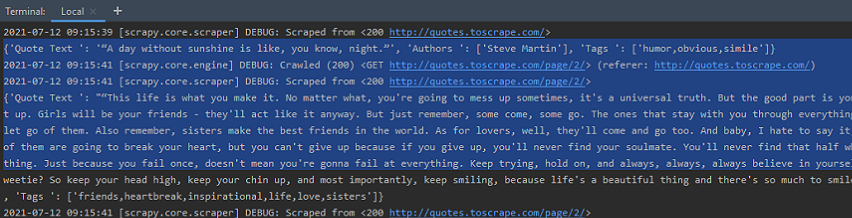
The Spider outputs Quotes from webpage 1 , 2 and rest of them
If we check, the Spider output statistics, we can see that the Spider has crawled, over ten webpages, by following the links. Also, the number of Quotes is close to 100.
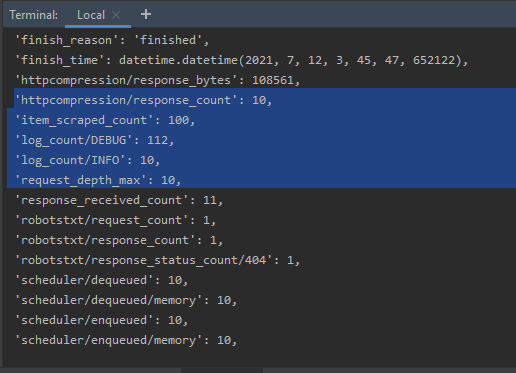
The Spider statistics, at the terminal, indicating the number of pages crawled
We can collect data, in any file format, for storage or analysis. To collect the same, in a JSON file, we can mention the filename, in the ‘crawl’, syntax as follows:
scrapy crawl gfg_spilink -o spiderlinks.json
The above command will collect the entire scraped Quotes data, in a JSON file “spiderlinks.json”. The file contents are as seen below:
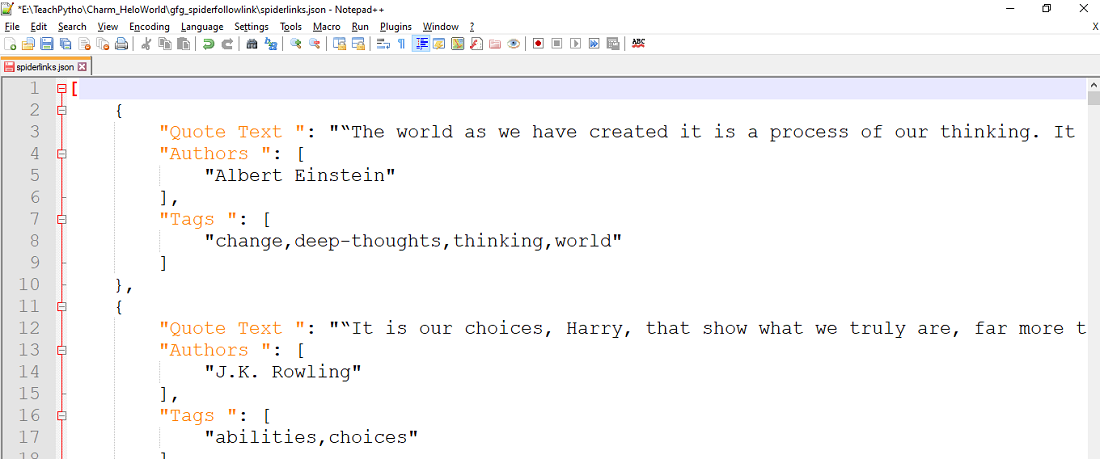
All Quotes are collected in JSON file
Share your thoughts in the comments
Please Login to comment...