Hierarchical data is structured like a family tree, where each member (node) is linked to others (children) in a parent-child relationship, forming a hierarchy. It’s ideal for representing corporate reporting structures or organizing tasks within projects. Nodes have one parent but parents can have multiple children, with the top-level parent called the ‘root node.’
Despite its complexity and the need to scan the entire tree for searches, modern databases employ clever techniques for efficient hierarchical data retrieval. Although less popular now, it finds utility in storing staffing information. Eric S Raymond once noted its historical challenges, yet its adaptability endures for specific use cases.
What Is Hierarchical Data?
Hierarchical data structures are perfect for organizations that need to represent their data in the form of parent-child relationships, or tree structures.
It’s used throughout the banking, telecommunications, and manufacturing sectors because it allows for fast and consistent performance the Windows registry, for example, which appears on a massive 91.7 percent of the world’s computers, is hierarchical.
Hierarchical data excels in scenarios where:
- Tree hierarchy: data can be cleanly organized hierarchically, like tree branches.
- Preservation of Hierarchy: The hierarchical relationships in the data must be maintained and used to manage and search for data. For more information, visit the Customer Support website.
- Managing large data volumes: the system must be able to process large volumes of data without compromising either performance or accuracy.
- Complex System Migration Constraints: Switching out to alternative models such as relational or network databases might be too difficult or too costly – in which case a hierarchical data model will do.
Alternatives to Hierarchical Data
Other data models may be more suitable for different requirements:
- Relational Data Model: Unlike hierarchical ones, relational databases have data organized in tables with rows and columns and establish connections between objects through keys. It is recognized for its flexibility and scalability that can be applied to various types of data.
- Network Data Model: This model expands on the hierarchical structure by having multiple parents for every child node hence creating a more interwoven web. Although it allows flexible representations of complex relationships, it can be difficult to implement and query, especially when compared to hierarchical models.
- Graph Data Model: Graph databases represent interconnected information as nodes and edges, which allows problem-specific flexible representation. For example, this type of database is useful for network analysis or social networks/recommendation systems where what counts most is entity relations.
- Document-Oriented Data Model: Document-Oriented Data Model: Document databases are structured in formless documents like JSON or BSON mostly for unstructured or semi-structured information. It scales well, provides high flexibility and ease of use making it perfect for applications such as content management systems (CMS), product catalogs and real-time analytics.
Advantages of Hierarchical Data Structures
- Enhanced Data Retrieval: Data retrieval has been made easy because of this hierarchical structure. There are clear parent-child relationships which make finding and accessing the inquired-about child easier while keeping parent and child near each other to speed up navigation.
- Simple Structure: The hierarchical arrangement is easily comprehensible hence making the data easy to understand and manage. The conceptual model of a parent child relationship is simple as it provides command chains within databases without ambiguity or confusion. It also enhances quickness and sharing of information across the organization.
- Good Security: Security mechanisms such as access control and data integrity are provided by database management systems. With these security measures, it’s hard for any unauthorised user to gain access of private information because it gives tight security to the system. This helps in ensuring that there is control over who accesses the documents and what they do with them, upholding confidentiality and integrity.
Challenges of Hierarchical Data Structures
- Inflexibility: The inflexible nature of this model makes changes difficult without disrupting the whole structure entirely. Adding new nodes/relationships may result in modifications being made on the parent table which ultimately leads to intricacy and turbulence sometimes. Reorganizing or moving nodes within the hierarchy can be challenging and may require significant effort.
- Suitability for One-to-Many Relationships Only: Such structures work well when representing one-to-many relationships examples being parent-child connections. However, they do not lend themselves well to many-to-many associations or more complex ones beyond simple parent-child relationships.
- Deletions: Removing a parent node from a hierarchical structure can result in the cascading removal of all associated child nodes. Unless carefully managed, this type of cascade deletion can lead to unintentional data loss and make data integrity difficult to maintain. To help illustrate the concept, consider the act of erasing a folder and all of its contents from a file system.
- Lack of Standards: Hierarchical structures, unlike some other models, lack data definition or manipulation languages (such as SQL) that are tailor made for them. Trying to enforce a set of common standards across different implementations can be a bit more difficult with this model, because it doesn’t provide as much rigidity.
- Complex Implementation: Building a system for hierarchical data storage requires a deep understanding of the operational nature of the data to be stored and the organizational structure it should have. This complexity can make this model more difficult to implement than other models, and it requires careful planning and analysis of the relationships between nodes.
Examples of Hierarchical Data
Example 1: Using CTE with Concatenation
CREATE TABLE hierarchy (
id INT PRIMARY KEY,
name VARCHAR(100),
parent_id INT
);
INSERT INTO hierarchy (id, name, parent_id) VALUES
(1, 'Node 1', NULL),
(2, 'Node 1.1', 1),
(3, 'Node 1.2', 1),
(4, 'Node 1.1.1', 2),
(5, 'Node 1.1.2', 2),
(6, 'Node 1.2.1', 3),
(7, 'Node 1.2.2', 3);
WITH hierarchy_paths AS (
SELECT id, name, CAST(name AS VARCHAR(255)) AS path
FROM hierarchy
WHERE parent_id IS NULL
UNION ALL
SELECT h.id, h.name, CAST(CONCAT(hp.path, ' > ', h.name) AS VARCHAR(255))
FROM hierarchy h
JOIN hierarchy_paths hp ON h.parent_id = hp.id
)
SELECT id, name, path
FROM hierarchy_paths;
Output:

CTE Output
Explanation: The given SQL code creates a table “hierarchy” representing a hierarchical structure. The subsequent CTE, “hierarchy_paths,” recursively traverses the hierarchy, building paths for each node. The output showcases the hierarchical paths for every node in the structure.
For example, Node 1.1.1 is displayed with its unique ID, name, and a path representation indicating its position in the hierarchy, such as “Node 1 > Node 1.1 > Node 1.1.1.” This structured output provides a clear view of the parent-child relationships within the hierarchy, facilitating easy comprehension and analysis of the data structure.
Example: Organizational Chart Hierarchy with Recursive CTE in SQL
-- Create table
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
EmployeeName VARCHAR(50),
ManagerID INT
);
-- Insert values
INSERT INTO Employees (EmployeeID, EmployeeName, ManagerID)
VALUES
(1, 'John', NULL),
(2, 'Alice', 1),
(3, 'Bob', 1),
(4, 'Charlie', 2),
(5, 'David', 3);
WITH RecursiveOrgChart AS (
SELECT EmployeeID, EmployeeName, ManagerID, 0 AS Level
FROM Employees
WHERE ManagerID IS NULL
UNION ALL
SELECT e.EmployeeID, e.EmployeeName, e.ManagerID, roc.Level + 1
FROM Employees e
INNER JOIN RecursiveOrgChart roc ON e.ManagerID = roc.EmployeeID
)
SELECT EmployeeID, EmployeeName, ManagerID, Level
FROM RecursiveOrgChart
ORDER BY Level, EmployeeID;
Output:
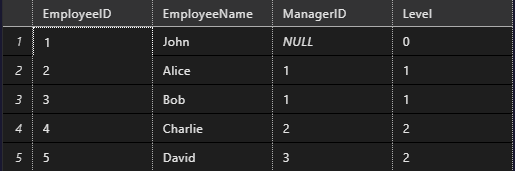
Output
Explanation: This SQL code creates an “Employees” table, inserts hierarchical data, and utilizes a recursive CTE (Common Table Expression) named “RecursiveOrgChart” to generate an organizational chart. The final query retrieves and orders the results, displaying EmployeeID, EmployeeName, ManagerID, and Level for clarity.
Conclusion
In conclusion, hierarchical data structures, resembling family trees, facilitate organized kinship relations in a tree-like hierarchy. Widely used in business maps and project organization, they offer intuitive data management. However, drawbacks include inflexibility in modifications, challenges with complex relationships, and issues with effective data deletion. Recursive SQL queries, often using CTE, are crucial for navigating hierarchical data.
Share your thoughts in the comments
Please Login to comment...