Kubernetes or K8s is an open-sourced container orchestration technology that is used for automating the manual processes of deploying, managing and scaling applications by the help of containers. Kubernetes was originally developed by engineers at Google and In 2015, it was donated to CNCF (Cloud Native Computing Foundation)
To understand Kubernetes, one must understand its basic components and its building blocks. In this article, we will be discussing the most fundamental components of Kubernetes as well as what are they used for.
Kubernetes has tons of components but most of the time we are going to be working with just a handful of them. Following is the list of all the important components of Kubernetes along with their roles in Kubernetes.
1. Pods
Pod is the smallest or fundamental component of a Kubernetes architecture. One very important feature of Pod is that it is ephemeral. This means that if a Pod fails, then Kubernetes can automatically create its new replica.
Role of a Pod
The pod is an abstraction over a container. Pod creates a running environment or a layer on top of the Container. The reason is that Kubernetes wants to abstract away the container runtime or container technologies so that we can replace them if we want to. This is also so that we don’t have to directly work with Docker or whatever container technology we use in Kubernetes. so we only interact with the Kubernetes layer.
The pod is usually meant to run one application container inside of it. You can run multiple containers inside one Pod but usually, it’s only the case if you have one main application container and a helper container or some side service that has to run inside of that pod.

In the diagram above we have an application Pod which is our own application and that also uses a database Pod with its own container. We have one server and two containers running on it with a abstraction layer on top of it.
2. Virtual Network
Virtual Network is the component of Kubernetes which enables the worker nodes and the master nodes to talk to each other. Virtual Network actually turns all the nodes inside of the cluster into one powerful machine that has the sum of all the resources of individual nodes.
Role of Virtual Network
Role of Virtual Network inside a Kubernetes Cluster is to enable the worker nodes and the master node to communicate with each other enabling them to act as one single powerful machine.
3. IP addresses
In Kubernetes, inside the virtual network, each Pod gets its own IP address (note that Pod gets the IP address not the container) and each Pod can communicate with each other using that IP address.
Role of IP addresses
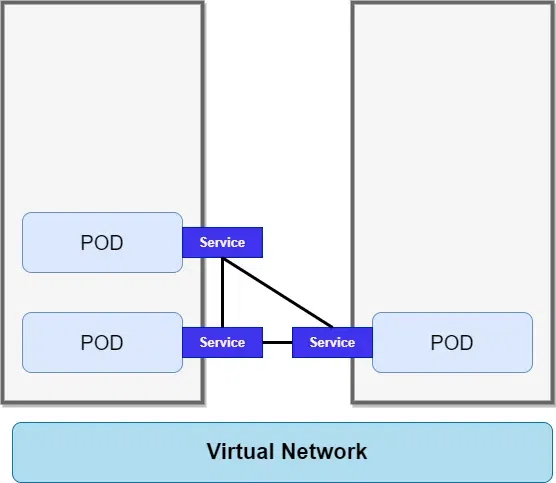
In a Kubernetes Cluster, Pods communicate can communicate with each other by the help of their IP addresses. It is an internal IP address so it’s not the public. Let’s say that our application container can communicate with database using the IP address. However, Pod components in Kubernetes are ephemeral (which means that they can die very easily). Have a look at the diagram.
.webp)
When the Pods die, for example, if we lose a base container because the container crashed because the application crashed inside or because the Nodes that we are running them on ran out resources, the Pod will die and a new one will get created in its place. When that happens it will get assigned a new IP address. This is very inconvenient because now we have to adjust the IP address every time the Pod restarts. And that is why we use another Kubernetes component called service.
4. Service
The official definition on services says that “a Service is a method for exposing a network application that is running as one or more Pods in your cluster.” Service is basically a static IP address or permanent IP address that can be attached to the Pod. That means that “my app” will have its own Service and database Pod will have its own Service.
Role of Service
The Role of Service is that the life cycles of Service and the Pod are not connected so even if the pod dies the Service and its IP address will stay so we don’t have to change that endpoints every time the Pod dies.
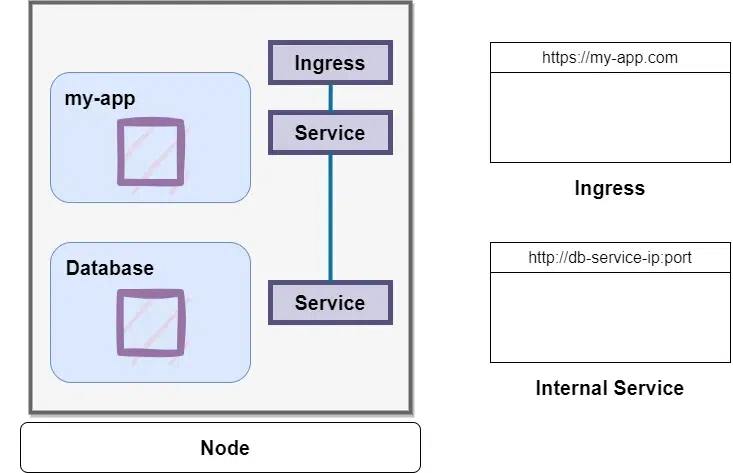
Now we want our application to be accessible through a browser and for this we would have to create an external service. External service is a service that opens the communication from external sources. But we would not want our database to be open to the public requests (because of security reasons). So for that we would create an internal service – this is a type of a service that you specify when creating one.
Example of Internal Service:
http://db-service-ip:port
Example of External Service:
http://my-app-service-ip:port
however this URL of the external service is not very practical, it is good for test purposes but not for the end product so usually you will want your URL to look like this if you want to talk to your application with a secure protocol and a domain name –
https://my-app.com
And for that we use Ingress.
5. Ingress
The official definition of Ingress says “Ingress is an API object that manages external access to the services in a cluster”.
Role of Ingress
The role of Ingress is that instead of Service, the request goes first to Ingress and it does the forwarding then to the Service.
6. Config Map
Config Map is the external configuration to your application. Config Map usually contains configuration data like URLs of database or URLs of some other services that we are using.
Role of Config Map
Pods communicate with each other using a Service. Our application will have a database end point, For example, mongo-db-service will have a database end point that it uses to communicate with the database. Now the problem is where should we configure? Usually we would keep this database URL or endpoints inside of the built image of the application. And there is an issue with that – For example, if the endpoint of the Service or Service name in this case changed to mongo-db. We will have to adjust that URL in the application and we would have to rebuild the application with a new version, then push it to the repository and then pull that new image in our pod and then restart the whole thing. This you can see is very tedious for a small change like database URL. To solve this problem Kubernetes has a component called Config Map. Diagram of Config map along with Secret is available in the next section.
In Kubernetes, we just connect Config Map to the Pod so that the Pod actually gets the data that Config Map contains. Now if we want to change the name of the service, or the endpoint of the service, we just have to edit the config map and that’s it. We don’t have to build a new image and go through that whole cycle again.
6. Secret
Secret is just like config map but the difference is that it’s used to store secret data credentials and it stores this data not a plain text format but in base64 encoded format.
Role of Secret
Role of Secret like we just discussed is similar to that of a Config map. Secret is used to store the data and credentials that we would not want to share with others.
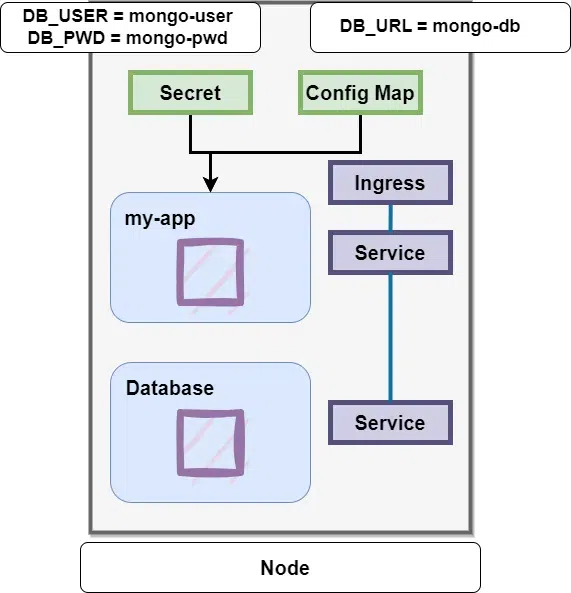
Database Username and Password can also be part of the external configuration. Username and Password may also change in the application deployment process but putting a password or other credentials in a Config Map in plain text format would be insecure. For this purpose Kubernetes has the component called Secret. The passwords, certificates, etc that you don’t want other people to have access to would go in the Secret. Just like Config Map you can just connect it to your Pod so that the Pod can actually see those data and read from the Secret.
7. Volumes
A Volume in Kubernetes is a data storing feature with the help of which we can store data that is persistent and can be accessed by containers in a Kubernetes pod.
Role of Volumes
In our current diagram, we have the database Pod that our application uses and it has some data or it generates some data. The issue with this Pod is that if the database container or the Pod gets restarted, the data would be gone. We would want your database data or log data to be persisted in the long-term and that is why we have the Kubernetes component called Volumes.
How Volumes do this is that it basically attaches a physical storage on a hard drive to your Pod. That storage could be either on a local machine (meaning on the same server node where the Pod is running) or it could be on a remote storage (meaning outside of the Kubernetes cluster). Now when the database Pod or the Container gets restarted, all the data will be there persisted.
8. Deployment
Deployment are the Kubernetes component that manages the replication and lifecycle of the Pods in the Kubernetes Cluster.
In our current example, what happens if our application Pod dies, crashes or I have to restart the Pod because I built a new container image? What happens is that we will have a downtime where the users will not be able to reach our application. This is a terrible thing if it happens in production.
Role of Deployment
The role of StatefulSets and Deployment is exactly this. When using distributed systems and containers, instead of relying on just one application Pod and one database Pod etc. We can replicate everything on multiple servers, so we would have another node where a replica or clone of our application would run which will also be connected to the Service. Previously we discussed that the service is like an persistent static IP address with a DNS name so that you don’t have to constantly adjust the end point when pod dies. The Service is also a load balancer which means that the service will actually catch the request and forward it to whichever Pod is the least busy.
In order to create the second replica of the my application pod we will not create a second Pod rather we will define a blueprint in our application Pod and specify how many replicas of that pod we want to run. That component or that blueprint in Kubernetes is called Deployment. Actually we don’t even work with Pods or create Pods, we rather create creating Deployments and StatefulSets and there we can specify how many replicas we want and we can scale up or scale down number of replicas of Pods.

Therefore we can say that Pod is a layer of abstraction on top of containers and Deployment is another abstraction on top of Pods which makes it more convenient to interact with the Pods, replicate them and do some other configuration. Now if one of the replicas of our replication Pod would die, the Service will forward the requests to another one so our application would still be accessible for the user.
9. StatefulSet
StatefulSets are the Kubernetes component that manages the replication and lifecycle of the Pods in the Kubernetes Cluster but specifically for Stateful applications.
Role of StatefulSet
Deployment solved our problems with the application Pod but what about the database Pod? Because if the database Pod dies, our application also would not be accessible so we need database replicas as well however we can’t replicate database using a deployment. The reason for that is because database has a state (which is its data) meaning that if we have closed a set of replicas of the database, they would all need to access the same shared data storage and there we would need some kind of mechanism that manages which Pods are currently writing to that storage or which Pods are reading from that storage. We will have to do this in order to avoid data inconsistencies.
This mechanism in addition to replicating feature is offered the Kubernetes component called StatefulSet. StatefulSet is meant specifically for applications like databases. StatefulSet just like deployment would take care of replicating the pods and scaling them up or scaling them down but making sure that database reads and writes are synchronized so that no database inconsistencies are offered. however deploying database applications using StatefulSets in Kubernetes cluster can be somewhat tedious that’s why it is also a common practice to host database applications outside of the Kubernetes cluster and just have the deployments or stateless applications that replicate and scale with no problem inside of the Kubernetes Cluster and then communicate with the external database.

Conclusion
The best way to understand the Kubernetes architecture is to first start with all the components of Kubernetes and how they work. Make sure to go through all the Kubernetes Components we discussed in this article before you learn about the Kubernetes architecture in order to understand it in a more comprehensive way.
FAQs on Fundamental Kubernetes Components and their role in Container Orchestration:
1. What is the use of Virtual Network?
Virtual Network inside a Kubernetes Cluster enables the worker nodes and the master node to communicate with each other
2. Why do we use Kubernetes Volumes?
Volumes in Kubernetes is used for persistent data storing.
3. What are Kubernetes Pods?
Pod is the smallest or fundamental component of a Kubernetes architecture.
4. What are Kubernetes Deployment?
Deployment are the Kubernetes component that manages the replication and lifecycle of the Pods in the Kubernetes Cluster.
5. What is the difference between Secret and Config Map?
Kubernetes Secret is used to store secret data credentials that should not be available to everyone, in base64 encoded format. While Config Maps usually contains configuration data like URLs of database or URLs of some other services.
Share your thoughts in the comments
Please Login to comment...