Fetching text from Wikipedia’s Infobox in Python
Last Updated :
09 Jan, 2023
An infobox is a template used to collect and present a subset of information about its subject. It can be described as a structured document containing a set of attribute-value pairs, and in Wikipedia, it represents a summary of information about the subject of an article.
So a Wikipedia infobox is a fixed-format table usually added to the top right-hand corner of articles to represent a summary article of that wiki page and sometimes to improve navigation to other interrelated articles.
[To know more about infobox, Click here]
Web Scraping is a mechanism that helps to extract large amounts of data from websites whereby the data is extracted and saved to a local file in your computer or to a database in table (spreadsheet) format.
There are several ways to extract information from the web. Using APIs is one of the best ways to extract data from a website. Almost all large websites like Youtube Facebook, Google, Twitter, StackOverflow provide APIs to access their data in a more structured manner. If you can get what you need through an API, it is almost always preferred the red approach over web scraping.
Sometimes, there is a need for scraping the content of a Wikipedia page, while we are developing any project or using it somewhere else. In this article, I’ll tell how to extract contents of the Wikipedia’s Infobox.
Basically, We can use two Python modules for scraping data:
Urllib2: It is a Python module that can be used for fetching URLs. urllib2 is a Python module for fetching URLs. It offers a very simple interface, in the form of the urlopen function. This is capable of fetching URLs using a variety of different protocols. For more detail refer to the documentation page.
Note:
The urllib2 library was deprecated in favor of the requests library because the latter offered a more user-friendly and feature-rich interface for making HTTP requests. Specifically, the requests library supported HTTPS by default, provided a simpler and more flexible interface, and offered features such as automatic retries and connection pooling.
BeautifulSoup: It is an incredible tool for pulling out information from a webpage. You can use it to extract tables, lists, paragraphs and you can also put filters to extract information from web pages. Look at the documentation page of BeautifulSoup
BeautifulSoup does not fetch the web page for us. We can use urllib2 with the BeautifulSoup library.
Now I am going to tell you another easy way for scraping
Steps for the following:
The modules we will be using are:
I have used Python 2.7 here,
Make sure these modules are installed on your machine.
If not then on the console or prompt you can install it using pip
Python
import requests
from lxml import etree
req = requests.get(url)
store = etree.fromstring(req.text)
output = store.xpath('//table[@class="infobox vcard"]/tr[th/text()="Motto"]/td/i')
print output[0].text
|
See this link, it will display the ‘Motto section’ of this Wikipedia page info box.(as shown in this screenshot)
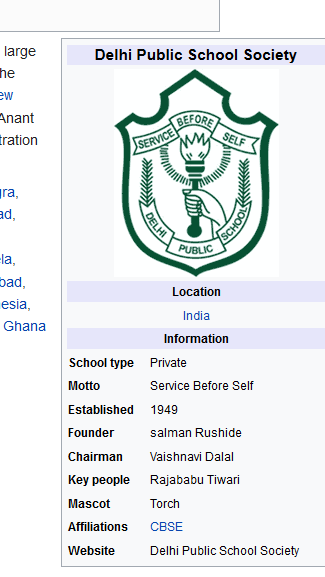

Write your code first of all
Now finally after running the program you get,
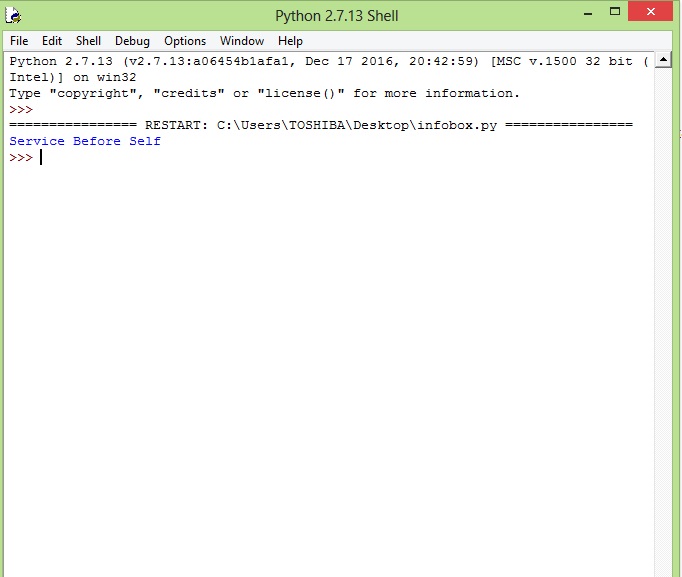
You can also modify the URL.XPath to get different sections of the infobox.
If you want to learn more about web scraping, go to these links,
1) Web Scraping 1
2) Web Scraping 2
Share your thoughts in the comments
Please Login to comment...