Designing Non-Deterministic Finite Automata (Set 4)
Last Updated :
28 Jan, 2024
Prerequisite: Finite Automata Introduction In this article, we will see some designing of Non-Deterministic Finite Automata (NFA). Problem-1: Construction of a minimal NFA accepting a set of strings over {a, b} in which each string of the language contain ‘a’ as the substring. Explanation: The desired language will be like:
L1 = {ab, abba, abaa, ...........}
Here as we can see that each string of the above language contains ‘a’ as the substring. But the below language is not accepted by this NFA because some of the string of below language does not contain ‘a’ as the substring.
L2 = {bb, b, bbbb, .............}
The state transition diagram of the desired language will be like below: 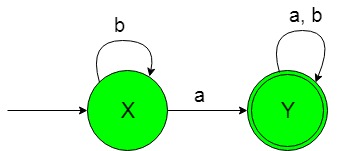 In the above NFA, the initial state ‘X’ on getting ‘a’ as the input it transits to a final state ‘Y’ and on getting ‘b’ as the input it remains in the state of itself. The final state ‘Y’ on getting either ‘a’ or ‘b’ as the input it remains in the state of itself. Refer for DFA of above NFA.
In the above NFA, the initial state ‘X’ on getting ‘a’ as the input it transits to a final state ‘Y’ and on getting ‘b’ as the input it remains in the state of itself. The final state ‘Y’ on getting either ‘a’ or ‘b’ as the input it remains in the state of itself. Refer for DFA of above NFA.
Transition Table :
In this table initial state is depicted by —> and final state is depicted by *.
| STATES |
INPUT (a) |
INPUT (b) |
| —> X |
Y* |
X |
| Y* |
Y* |
Y* |
Python implementation:
C++
#include <iostream>
#include <string>
void stateX(const std::string& n);
void stateY(const std::string& n);
void stateY(const std::string& n) {
if (n.empty()) {
std::cout << "string accepted" << std::endl;
} else if (n[0] == 'a') {
stateY(n.substr(1));
} else if (n[0] == 'b') {
stateY(n.substr(1));
}
}
void stateX(const std::string& n) {
if (n.empty()) {
std::cout << "string not accepted" << std::endl;
} else if (n[0] == 'a') {
stateY(n.substr(1));
} else if (n[0] == 'b') {
stateX(n.substr(1));
}
}
int main() {
std::string assumedString = "bab";
stateX(assumedString);
return 0;
}
|
Python3
def stateX(n):
if(len(n)==0):
print("string not accepted")
else:
if (n[0]=='a'):
stateY(n[1:])
elif (n[0]=='b'):
stateX(n[1:])
def stateY(n):
if(len(n)==0):
print("string accepted")
else:
if (n[0]=='a'):
stateY(n[1:])
elif (n[0]=='b'):
stateY(n[1:])
n=input()
stateX(n)
|
Problem-2: Construction of a minimal NFA accepting a set of strings over {a, b} in which each string of the language is not containing ‘a’ as the substring. Explanation: The desired language will be like:
L1 = {b, bb, bbbb, ...........}
Here as we can see that each string of the above language is not containing ‘a’ as the substring But the below language is not accepted by this NFA because some of the string of below language is containing ‘a’ as the substring.
L2 = {ab, aba, ababaab..............}
The state transition diagram of the desired language will be like below: 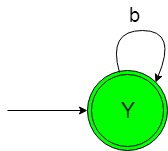 In the above NFA, the initial and final state ‘Y’ on getting ‘b’ as the input it remains in the state of itself.
In the above NFA, the initial and final state ‘Y’ on getting ‘b’ as the input it remains in the state of itself.
Transition Table :
In this table initial state is depicted by —> and final state is depicted by *.
| STATES |
INPUT (a) |
INPUT (b) |
| —> Y * |
Y* |
Y* |
Implementation:
Java
import java.util.*;
import java.io.*;
class GFG
{
public static void stateY(StringBuilder n)
{
if(n.length() == 0)
System.out.println("string accepted");
else
{
if (n.charAt(0)=='a')
System.out.println("String not accepted");
else if(n.charAt(0)=='b')
{
n.deleteCharAt(0);
stateY(n);
}
}
}
public static void main (String[] args)
{
Scanner sc = new Scanner(System.in);
String n = sc.next();
StringBuilder b = new StringBuilder(n);
stateY(b);
}
}
|
Python3
def stateY(n):
if(len(n)==0):
print("string accepted")
else:
if (n[0]=='a'):
print("String not accepted")
elif (n[0]=='b'):
stateY(n[1:])
n=input()
stateY(n)
|
Share your thoughts in the comments
Please Login to comment...